Tirez un maximum de ce cours
Présentation du cours

Bienvenue à tous ! Dans ce cours, nous allons mettre en place l’intégration continue et la livraison continue sur un projet de développement.
Vous avez sûrement entendu parler de ces termes, sur Internet ou dans les entreprises. L’intégration et la livraison continues, ou en anglais Continuous Integration and Continuous Delivery (CI/CD) permettent de :
accélérer le time-to-market (le temps de développement et de mise en production d’une fonctionnalité) ;
accroître la stabilité en permettant la reproductibilité du processus de livraison ;
assurer une continuité de service des applications.
Généralement, les pratiques DevOps sont souvent associées à l’intégration continue et à la livraison continue. Souvent, ces deux termes sont associés à l’abréviation CI/CD. Si vous voulez en savoir plus sur le DevOps, vous pouvez suivre le cours Découvrez la méthodologie DevOps.
Rencontrez votre professeur
Laurent Grangeau est Architect Solutions chez Google. Il est également l’organisateur du meetup Serverless Paris, ainsi que co-organisateur des meetups Kubernetes et Docker Paris.
Il a développé dans plusieurs langages, principalement orientés objet comme Java ou C#.
Depuis plusieurs années, il aide les entreprises à utiliser le cloud, ainsi que les principes DevOps. Il a de l’expérience dans la construction de microservices et de systèmes distribués. Il aime automatiser les choses et exécuter des applications distribuées à l’échelle.
Découvrez le fonctionnement de ce cours
Ce cours sera divisé en deux parties ; chacune de ces parties aborde un pan de ce cycle CI/CD.
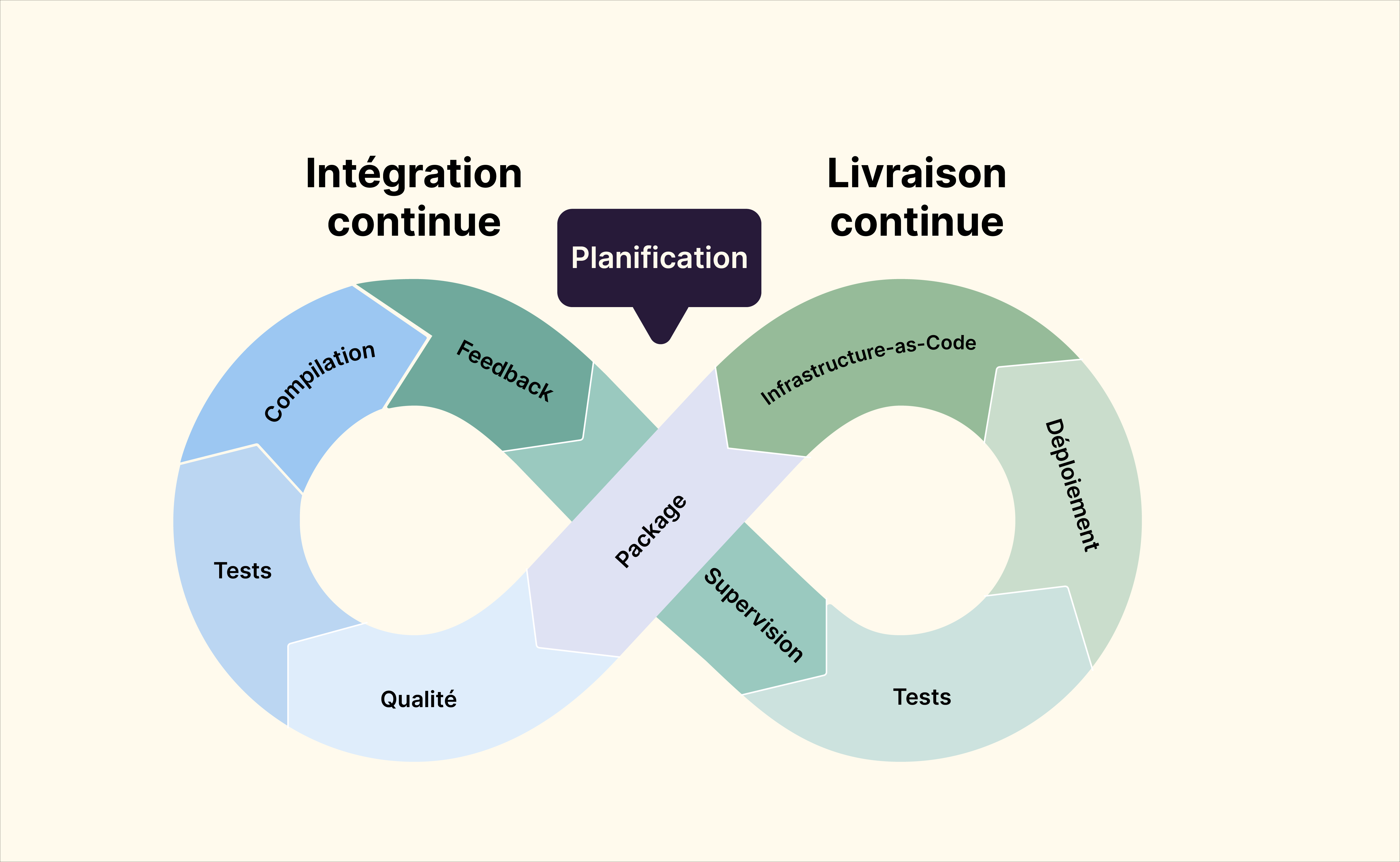
Dans la première partie, nous mettrons en place l’intégration continue en suivant chacune de ses étapes, de la planification aux tests en passant par l’intégration.
Dans la deuxième partie, nous poursuivrons la mise en place de la méthode avec la livraison continue : de la conteneurisation à la supervision de l’application.

Tout au long de ce cours, nous utiliserons GitLab CI, un outil très performant et permettant de mettre en place chacune des étapes du cycle avec un seul et même outil. Néanmoins, je vous présenterai à chaque étape les autres outils que vous pouvez utiliser.
Ce cours est très complet, il regroupe énormément de pratiques et vous fera voir de nombreux outils et notions. Ce cours est un cours pratique, dans lequel vous mettrez en application les enseignements. À chaque étape, vous aurez des conseils pour la mise en place. Effectuez les commandes présentées dans les vidéos au fur et à mesure, pour avancer dans le projet fil rouge au bon rythme.
Découvrez le projet fil rouge de ce cours

Dans l’ensemble du cours, je vous propose de travailler sur un projet exemple de Spring : le projet PetClinic. PetClinic est un projet de développement en Java, open source et utilisé pour illustrer des problématiques de déploiement et de code en microservice. C’est une plateforme de gestion de clinique vétérinaire en ligne. Nous allons mettre en place l’intégration continue et la livraison continue sur cette application, dans sa version microservice. Ça nous permettra de mettre en pratique ce qui est abordé tout au long du cours !
