Découvrez la livraison continue
Appréhendez la livraison continue
Dans cette partie, nous allons voir comment livrer votre code en continu pour le mettre en production rapidement, et de manière fiable.
La livraison continue est la suite logique de l’intégration continue. Dans l’intégration continue, nous cherchons à ce que le code compile bien, mais aussi qu’il soit fonctionnel en production et de qualité, en lançant le plus régulièrement possible les tests unitaires, ainsi que d’autres types de tests qui ne peuvent cependant pas être lancés sans avoir un environnement déployé.
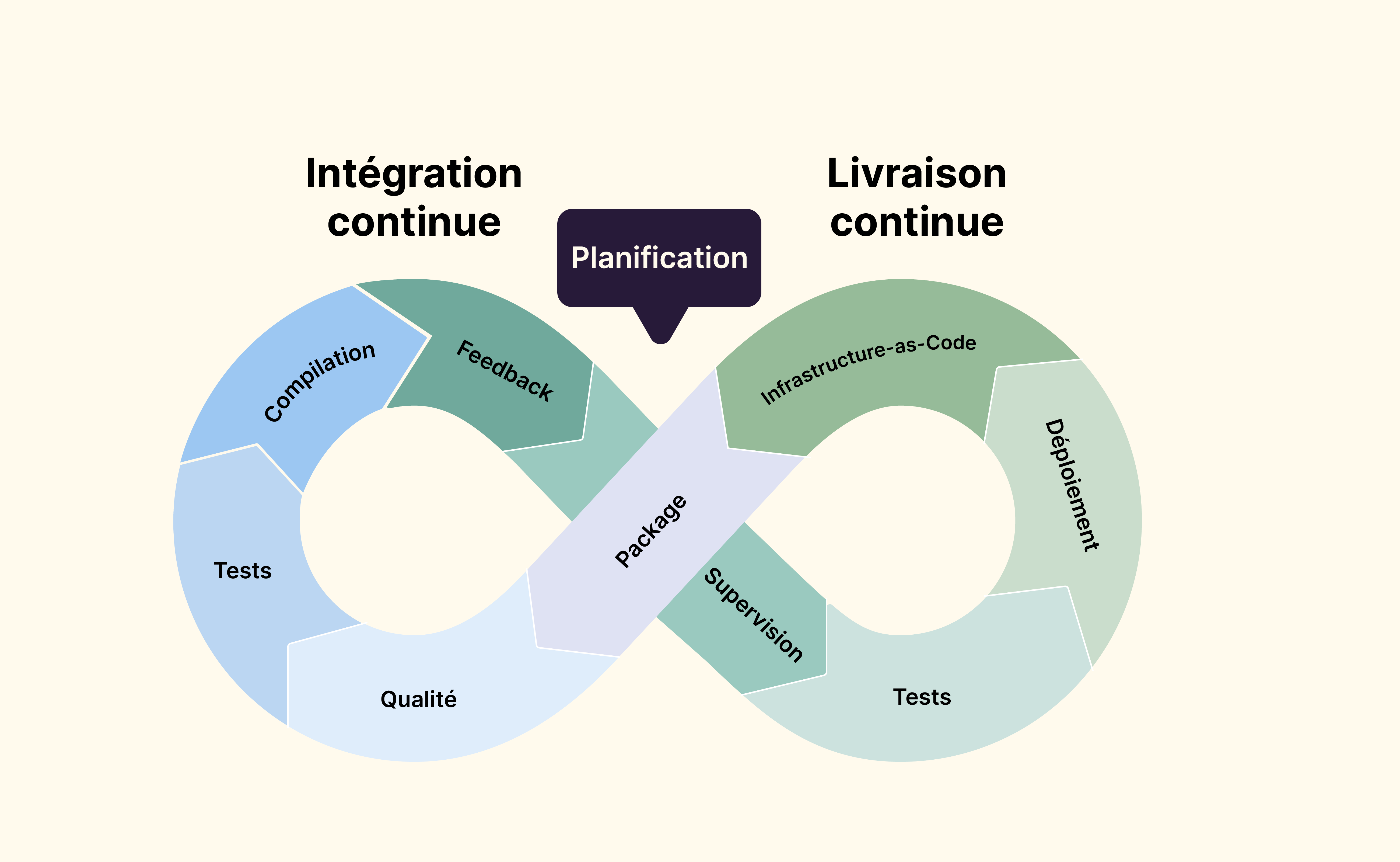
La livraison continue est une discipline où l’application est construite de manière à pouvoir être mise en production à n’importe quel moment.
Pour atteindre la mise en œuvre de la livraison continue sur une application, il est nécessaire de mettre en place plusieurs étapes supplémentaires au sein de notre pipeline.
La livraison continue peut aussi se faire sur des environnements déjà configurés. L’étape d’Infrastructure-as-Code ne sera donc pas nécessaire. Cependant, l’Infrastructure-as-Code permet de créer des environnements éphémères qui seront créés et détruits à la demande et contenant exactement ce dont a besoin l’application pour fonctionner. Ces environnements n’étant pas démarrés tout le temps, cela permet de faire des économies d’argent. De plus, ces environnements étant créés automatiquement, cela conduit aussi à des économies de temps car les ops ne perdent pas de temps à configurer ces environnements à chaque nouvelle livraison.
Dans la suite du cours, nous allons aborder plusieurs outils pour chacune des étapes. Rassurez-vous ! Vous n’avez pas à connaître tous ces outils pour mettre en place l’intégration continue et le déploiement continu en place. Ces outils ne sont ici qu’à titre informatif et sont à adapter par rapport au contexte de déploiement de l’intégration et la livraison continues de votre entreprise.
Dans la suite de ce chapitre, nous allons détailler chacune de ces étapes.
Codifiez votre infrastructure avec l’Infrastructure-as-Code
Les avantages sont nombreux :
possibilité de créer des environnements à la demande ;
création d’environnement en quelques minutes, contre plusieurs semaines dans une entreprise classique ;
pilotage de l’infrastructure grâce au pipeline de livraison continue ;
connaissance des logiciels installés sur la plateforme, grâce à l’outillage ;
montée de version des environnements automatisés.
Nous découvrirons comment déployer des infrastructures rapidement avec l’Infrastructure-as-Code dans le chapitre suivant.
Déployez et testez votre application
L’étape la plus importante de la livraison continue est le déploiement du package que nous avons précédemment créé lors de l’intégration continue. Les avantages d’utiliser un outil pour automatiser le déploiement de l’application sont nombreux :
cela permet à l’équipe de se concentrer sur le développement, là où elle a sa valeur à ajouter ;
n’importe qui dans l’équipe peut déployer des logiciels ;
les déploiements deviennent beaucoup moins sujets aux erreurs et beaucoup plus reproductibles ;
déployer sur un nouvel environnement est facile ;
les déploiements peuvent être très fréquents.
Nous mettrons en place le déploiement automatique du code dans le troisième chapitre de cette partie.
Dans cette étape, nous ajoutons aussi d’autres types de tests, comme les tests de charge ou les tests de performance, autres que ceux lancés lors de l’intégration continue, plus pertinents et plus fonctionnels, afin de garantir que l’application fonctionne comme nous l’avons estimé.
L’avantage de tester à ce stade du pipeline est que l’application tourne sur un environnement de test presque identique à celui de la production. Pour des raisons de coût ou de non-nécessité de haute disponibilité, cet environnement est différent de la production dans son infrastructure. Il n’y aura pas autant de serveurs que la production, ni la même taille de machine en termes de CPU, RAM ou stockage, mais les versions de middleware ainsi que les configurations doivent être rigoureusement identiques. Son comportement sera donc le plus fidèle possible à celui qu’elle aura en production.
Nous mettrons en place le lancement automatique des tests dans le troisième chapitre de cette partie.
Maintenez en conditions opérationnelles vos applications
Le maintien en conditions opérationnelles des applications est une étape critique de notre pipeline DevOps. Cette étape garantit que l’application sera toujours accessible et disponible pour l’utilisateur final.
Afin de pouvoir superviser les applications et garantir que les serveurs sous-jacents continuent à avoir les ressources nécessaires au bon fonctionnement de l’application, il faut mettre en place des indicateurs surveillant les métriques du système comme le CPU utilisé, la RAM disponible ou encore le stockage restant.
Traditionnellement, cette étape était assurée par des exploitants qui s’assuraient que les indicateurs mis en place étaient bons, c’est-à-dire en vert sur les dashboards de production. Quand une des ressources monitorées devient non disponible, les indicateurs changent de couleur selon l’importance de l’indisponibilité : orange si la ressource est proche d’être épuisée, rouge si elle est épuisée. Si un de ces indicateurs n’était plus disponible, en devenant orange voire rouge (ce qui signifie une interruption de service), ces exploitants intervenaient alors manuellement sur la machine incriminée, redémarrant les processus qui ne fonctionnaient plus.
Avec la migration des applications dans le cloud, ou la transformation de ces applications en microservices, celles-ci sont devenues scalables et les environnements sont devenus dynamiques. Par conséquent, il est maintenant quasiment impossible de maîtriser tout un système d’information pour une personne seule.
À partir de ce constat, un nouveau métier est apparu : le Site Reliability Engineer (SRE), ou ingénieur de qualité opérationnelle en français. Le rôle du SRE est de s’assurer que l’application soit toujours disponible, de manière automatique, et qu’elle se répare toute seule. Le SRE se repose sur l’automatisation des infrastructures sous-jacentes de l’application, mais aussi sur de la supervision et de l’observabilité de ces applications que nous verrons plus en détail dans la suite de ce chapitre.
Pour cela, le SRE se base sur ce qu’on appelle les quatre signaux dorés que sont la latence, le trafic, les erreurs et la saturation. Ces quatre signaux dorés sont utilisés pour définir les Service Level Indicators (SLI). Ces SLI sont utilisés pour définir des Service Level Objectives(SLO). Enfin, ces SLO sont utilisés dans les Service Level Agreements (SLA).
Nous verrons plus en détail ce sujet lors du quatrième chapitre de cette partie.
Supervisez le comportement de votre application
Le monitoring, ou supervision, intervient une fois que notre application est déployée sur un environnement, que ce soit un environnement de staging, de test, de démonstration ou bien l’environnement de production lui-même.
Le principe est de récupérer certaines métriques qui ont du sens pour ceux qui interviennent sur l’application. Cela peut être par exemple le nombre de connexions HTTP, le nombre de requêtes à la base de données, le temps de réponse de certaines pages ; mais aussi des métriques davantage orientées métier, comme le chiffre d’affaires généré, ou le nombre de personnes inscrites sur l’application.
Les métriques peuvent aussi concerner la partie livraison en elle-même, ou le processus de développement. Par exemple, l’équipe peut mesurer le nombre de déploiements qu’elle effectue par jour, ainsi que deux autres indicateurs qui sont importants afin de mesurer la performance correction d’erreurs qui peuvent survenir en production : Mean-Time-Between-Failure et le Mean-Time-To-Recover.
Calculez le Mean-Time-Between-Failure
Le Mean-Time-Between-Failure (ou MTBF) est le temps moyen qui sépare deux erreurs en production. Plus ce temps est élevé, plus le système est stable et fiable, notamment du fait de la qualité des tests qui sont joués lors de la livraison continue.
Calculez le Mean-Time-To-Recover
Le Mean-Time-To-Recover (ou MTTR) est le temps moyen de correction entre deux erreurs de production. Plus ce temps est faible, plus l’équipe est apte à détecter des erreurs et à les corriger rapidement.
Ces métriques comme le MTTR ou le MTBF sont indispensables mais ne sont pas suffisantes dans un contexte de déploiement microservices ou d’environnement scalable et dynamique comme le Cloud, c’est pourquoi une nouvelle discipline est apparue ces dernières années afin de pouvoir monitorer plus en détail et plus finement l’application dans ce contexte. Cette nouvelle discipline s’appelle l’observabilité et étend plus loin le concept de supervision que nous avons vu juste plus tôt dans le cours.
L’observabilité est la capacité à mesurer les états internes d’un système en examinant ce qu’il produit. Un système est considéré comme “observable” si son état actuel peut être estimé uniquement en utilisant les informations de sortie, à savoir les données des indicateurs. Nous verrons cela plus en détail dans le chapitre 5 de cette partie.
Nous verrons comment superviser l’application dans le cinquième chapitre de cette partie.
L’observabilité de l’application nous renvoie énormément de métriques afin d’avoir l’image la plus complète du comportement de l’application. Quand l’une de ces métriques est en échec, il est alors nécessaire d’avertir le plus rapidement l’équipe de support en notifiant celle-ci via des outils de notification. De plus, la première version d’une nouvelle fonctionnalité ou d’un nouveau produit ne couvre souvent pas entièrement les besoins des clients. Même lorsque l’équipe passe des semaines ou des mois à construire quelque chose, le produit final est souvent voué à manquer des fonctionnalités importantes. C’est le principe du Minimum Viable Product (MVP) en gestion Agile.
Il arrive donc très souvent de livrer des logiciels incomplets ou buggés, si l’équipe veut aller assez vite. Au lieu de vouloir éviter cela, il est nécessaire d’adopter l’idée de livrer des petites pièces de valeur.
En livrant plus vite, nous pouvons réparer les bugs tant que les livraisons restent petites et que nous savons ce qui a été modifié dans l’application. Quand les développements grossissent, ils deviennent plus difficiles à gérer et à remanier. Un feedback rapide, grâce aux tests en production et au monitoring, permet d’intervenir et de corriger le problème dès que possible. Il nous permet d’apprendre des clients, et des erreurs, au bon moment.
Nous verrons comment mettre en place des outils de notification rapide en cas de problème, dans le cinquième chapitre de cette partie.
En résumé
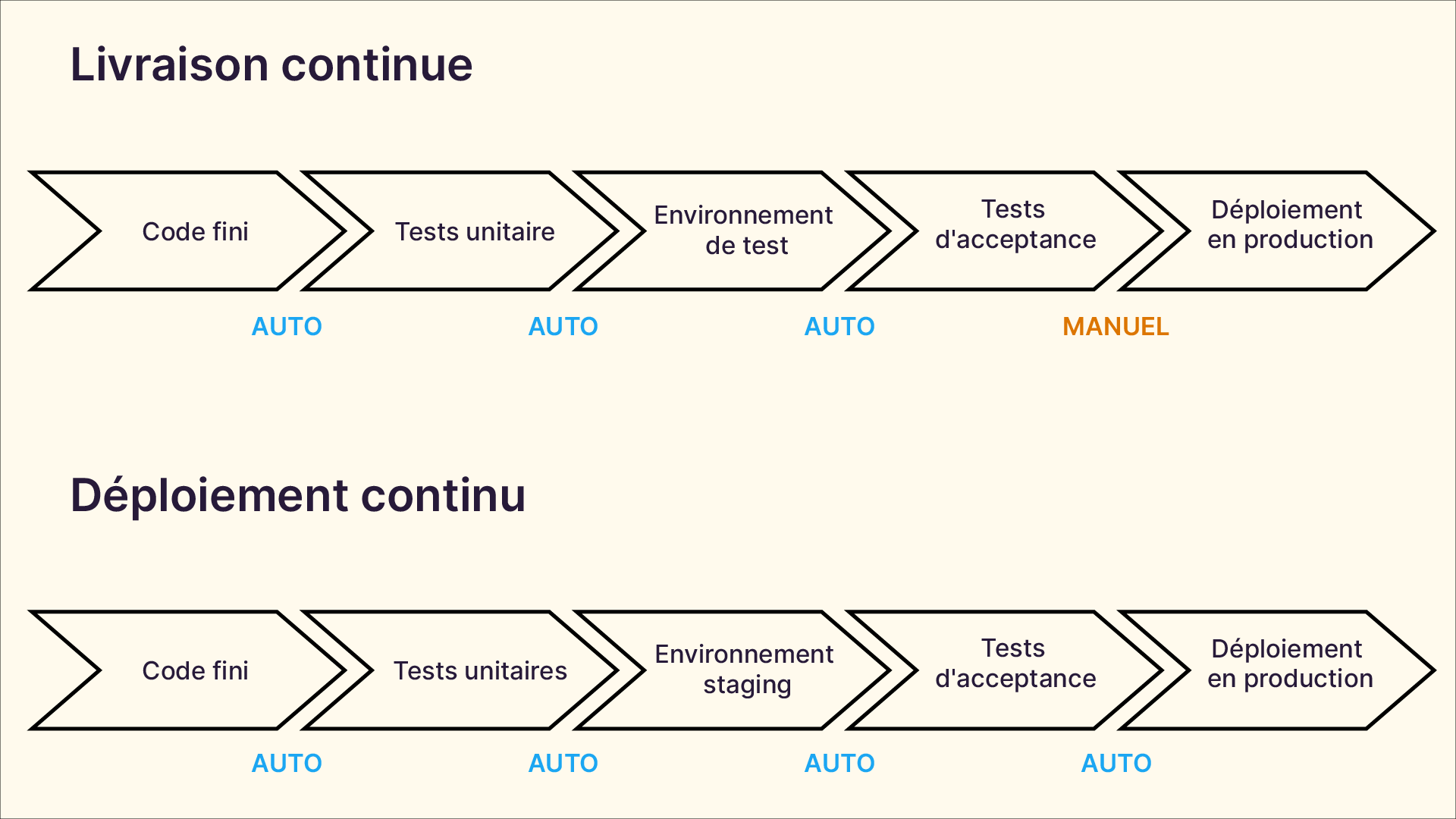
Il ne faut pas confondre livraison continue et déploiement continu.
La livraison continue étend le principe d’intégration continue et permet aux développeurs de disposer en permanence d’un artefact de génération prêt pour le déploiement.
Quatre étapes constituent la mise en œuvre de la livraison continue :
la codification de l’infrastructure avec l’Infrastructure-as-Code ;
le déploiement des images de l’application et le test de celle-ci en environnement de test ;
le maintien en conditions opérationnelles de l’application ;
la supervision de l’application, grâce à plusieurs métriques suivies automatiquement.
Vous avez maintenant une vue d’ensemble des différentes étapes qui composent la livraison continue. Dans le chapitre suivant, vous allez découvrir plus en détail la codification avec l’Infrastructure-as-Code.
