Fragmentez vos paquets
La fragmentation va donc être un rôle secondaire de la couche 3 qui devra permettre de découper un datagramme en plusieurs paquets ET de reconstituer ces paquets à la machine destinatrice.
La difficulté va donc être de pouvoir découper, puis recomposer les paquets reçus, même s’ils ne prennent pas le même chemin et arrivent dans le désordre, ou alors que l’un d’entre eux est perdu.
En effet, sur Internet, il y a souvent beaucoup de chemins possibles pour aller d’une machine A à une machine B et il peut arriver que des paquets ne suivent pas le même chemin.
Nous allons donc maintenant voir comment nous allons découper notre datagramme et identifier chacun des paquets qui seront coupés pour pouvoir les réassembler correctement.
Découpage des fragments
On nous parle de fragment, paquet et datagramme, mais qu’est-ce qui représente quoi là-dedans ?
Le datagramme est l’information de couche 3 au moment où la machine qui émet une information reçoit les informations de la couche 4.
Un paquet est l’élément de couche 3 qui circule sur le réseau. Il peut être un datagramme complet s’il n’a pas été découpé, ou un des morceaux de datagrammes fragmentés.
Un fragment est comme un paquet, sauf que l’on utilise souvent ce terme quand on parle de fragmentation.
Imaginons que notre machine souhaite envoyer un datagramme de 1 600 octets. Une trame pouvant transporter un datagramme de 1 500 octets (1518 - 18 octets d’en-tête Ethernet), il va falloir fragmenter ce datagramme.
Mais où va-t-on couper ? Au milieu ? Au début ? À la fin ?
La réponse est simple, les fragments doivent toujours être les plus gros possible.
Ainsi, nous allons faire un premier fragment de 1 500 octets, et un autre de... 120 octets.
Heu... mais 1 500 + 120, ça ne fait pas 1 600 ?
C’est exact, mais vous avez oublié les 20 octets d’en-tête qui sont dans notre datagramme d’origine. Il n’est pas nécessaire de les transporter, puisque nous allons de toute façon fabriquer un nouvel en-tête pour chacun des fragments réalisés. Il faut aussi ajouter un nouvel en-tête à chacun de nos nouveaux fragments. Voici un schéma qui explique cela :
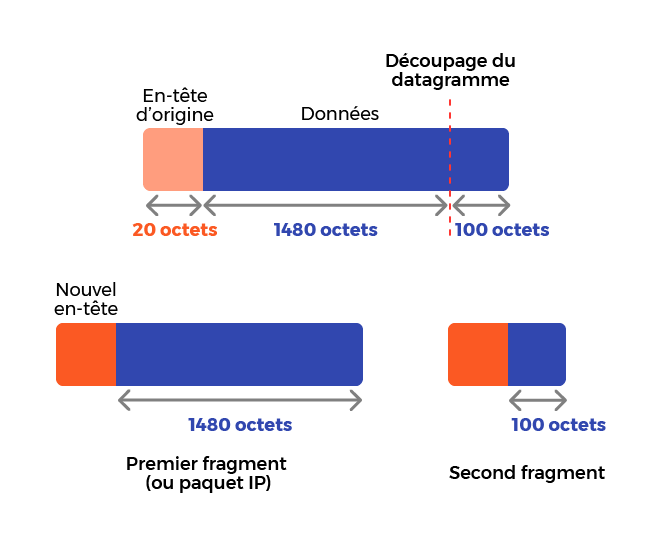
On voit bien ici que l’ancien en-tête sera enlevé et que seules les données seront découpées. Ensuite, chaque fragment aura un en-tête qui lui sera propre pour pouvoir être aiguillé sur Internet.
OK, donc un datagramme trop gros devra être découpé en fragments les plus gros possible.
Mais ça veut dire quoi, "les plus gros possible" ? C’est toujours 1 500 ? Ou ça peut être plus ? Ou moins ?
En fait, cette information doit être donnée par la couche 2, car c’est elle qui va encapsuler le datagramme IP et qui peut donc dire quelle taille de datagramme elle peut transporter. D’ailleurs, cette information porte un nom dont vous avez peut-être déjà entendu parler, il s’agit de la MTU (Maximum Transmission Unit).
La couche 2 va donc dire à la couche 3 quelle est la taille qu’elle peut accepter comme datagramme, et la couche 3 va faire en sorte de découper les datagrammes trop gros à cette taille. Par exemple, pour le protocole Ethernet, la MTU est de 1 500 octets.
Mais une des règles d’or du modèle OSI était que les couches étaient indépendantes entre elles ? Ici, ce n’est pas le cas ?
En fait si, car cette information n’est pas contenue dans les en-têtes. Il n’y aura donc pas de modification d’un protocole si l’on change cette taille. Le protocole IP utilise cette information, mais il est capable d’en accepter de différentes valeurs si jamais on change de protocole de couche 2. Cette information doit donc être définie par tout protocole de couche 2.
Identification et assemblage des fragments
Nous savons donc maintenant que la couche 3 va devoir découper les datagrammes trop gros par rapport à la MTU imposée par la couche 2. Mais il nous faut encore découvrir comment ces fragments vont être identifiés, et comment une machine qui va recevoir ces fragments va pouvoir reconstituer le puzzle !
Mais nous avons déjà vu des éléments dans l’en-tête que nous allons étudier plus en détail.

Il y a ici trois éléments qui nous intéressent : l’IPID, les flags et le fragment offset.
L’IPID : c’est un identifiant unique qui permet de savoir de quel datagramme d’origine proviennent les fragments. En gros, si un datagramme a l’IPID X, tous les fragments qui en proviennent auront l’IPID X. Ainsi, quand une machine recevra différents fragments X, Y ou Z, elle saura que ceux ayant l’IPID X proviennent du même datagramme. Étant codé sur deux octets, il peut prendre 2^{16} valeurs, soit entre 0 et 65 535.
Mais maintenant que nous savons quels fragments proviennent d’un datagramme, il faut encore être capable de les remettre dans l’ordre pour reconstituer le datagramme d’origine. Il y a pour cela le fragment offset, qui n’est pas des plus simples à comprendre...
Le fragment offset : il indique la place du fragment par rapport au datagramme d’origine.
Mais pour bien comprendre comment il fonctionne, nous allons devoir nous plonger dans un cas concret.
Reprenons notre cas précédent :
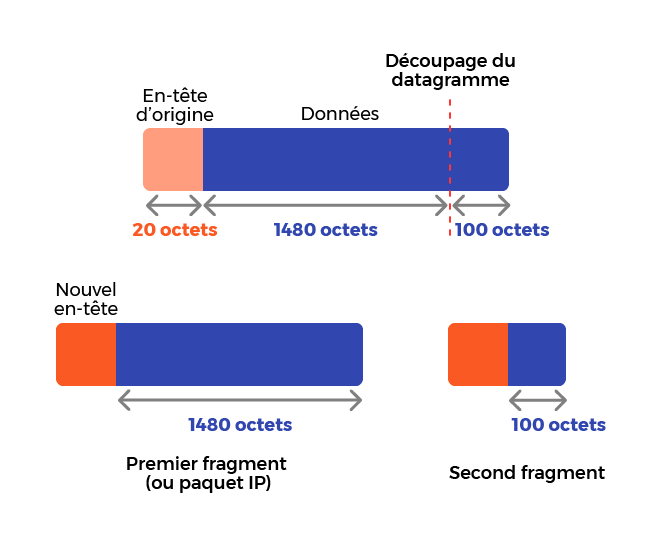
Nous allons donc devoir dire quelle est la place de chacun de ces fragments par rapport au datagramme d’origine. Cette place est donnée en octets.
Par exemple, le premier fragment aura un fragment offset de 0, car il n’y a aucun fragment avant lui.
Le second fragment aura un fragment offset de 1 480, car il y a 1 480 octets avant lui.
Le fragment offset n’est pas codé en octets, mais en mots de 8 octets. Il faut donc diviser les octets par 8 pour obtenir le vrai fragment offset.
Dans notre exemple, le premier FO (Fragment Offset, mais je suis fainéant) vaut toujours 0. Par contre, le second vaudra non plus 1 480, mais 1480/8 soit 185.
Mais pourquoi s’amuse-t-on à diviser le nombre d’octets par 8 ? On n’a rien d’autre à faire de mieux que des maths en réseau ?
En fait, c’est une nécessité, et pour le comprendre, nous allons revoir l’en-tête IP.
La longueur d’un datagramme est codée sur 16 bits et peut donc prendre des valeurs entre 0 et 65 535.
Le fragment offset est codé sur 13 bits et peut donc prendre des valeurs entre 0 et 8 191.
Cependant, il est possible de devoir coder un fragment offset pour un datagramme qui fait plus de 8 191 octets, et dans ce cas, on a un problème !
Les personnes qui ont créé le protocole IP se sont alors dit qu’en multipliant le fragment offset par 8, on pourrait couvrir toutes les valeurs possibles de taille de datagramme. Et c’est effectivement vrai : 8*8192=65536.
Mais d’où vient ce facteur multiplicateur de 8 ?
Eh bien, c’est la différence de 3 bits qui existe entre le nombre de bits pour coder la taille du datagramme et celle de la taille de l’offset. 3 bits représentent valeurs, soit 8 !
Cela apporte aussi une contrainte très forte pour nous :
Eh oui ! Cependant, si l’on regarde notre capture Wireshark précédente, on observe que la taille totale du datagramme fait 1 326 octets, soit une taille de données de 1 306 octets, qui n’est pas un multiple de 8. C’est un peu contradictoire.

Mais c’est normal, car en fait, le fragment offset doit coder des valeurs multiples de 8. Mais ces valeurs correspondent au nombre d’octets des paquets précédents !
Le dernier paquet provenant d’un datagramme fragmenté n’a pas besoin d’avoir une taille de données multiple de 8, car il n’y aura aucun fragment après lui et donc besoin d’avoir un nombre de données multiple de 8.
Vous me suivez ? Si ce n’est pas le cas, relisez tranquillement les informations précédentes plusieurs fois pour bien les assimiler.
On en arrive donc à la règle suivante :
Il nous reste à voir un dernier champ que sont les flags, codés sur trois bits, chaque bit représentant une information.
Premier bit : Réservé, il n’est pas utilisé et vaut toujours 0.
Second bit : Don't Fragment, qui indique donc que l’on veut obliger l’impossibilité de fragmenter un datagramme. S’il vaut 0, on a le droit de fragmenter, s’il vaut 1, on n’a pas le droit.
Troisième bit : More fragment. Ce bit indique s’il y a encore des fragments derrière celui-ci, et permet donc à une machine qui reçoit les fragments de savoir quel est le dernier d’entre eux.
À quoi ça peut bien servir d’interdire de faire de la fragmentation ?
Cela peut avoir de l’intérêt pour connaître la plus petite MTU autorisée entre deux points d’un réseau. C’est un mécanisme que l’on appelle MTU path discovery et qui sert notamment à éviter de faire de la fragmentation quand il y a beaucoup d’échanges entre deux points. Cela améliore légèrement les performances réseau, mais reste très peu utilisé.
OK, donc pour récapituler, nous avons tous les éléments nécessaires pour fragmenter un datagramme et être capables de le reconstruire à l’arrivée. Prenons un exemple concret pour mieux comprendre en détail le fonctionnement de la fragmentation.
Premier exercice de fragmentation
Nous allons faire un premier exercice simple sur la fragmentation pour remettre bout à bout toutes les notions que nous venons de voir. Nous pourrons ensuite passer à un exercice plus complexe !
Nous sommes sur un réseau simple que nous avons déjà utilisé par le passé avec deux machines situées sur deux réseaux différents, et un routeur qui relie ces deux réseaux :
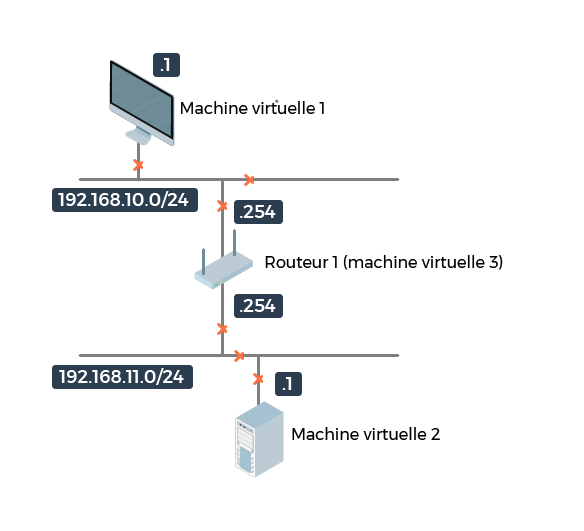
Notre machine virtuelle 1 veut envoyer un datagramme de 5 600 octets à la machine virtuelle 2. Les MTU pour les réseaux 192.168.10.0/24 et 192.168.11.0/24 sont identiques et valent 1 500 octets, comme pour un réseau Ethernet habituel.
Il va donc falloir fragmenter !
Nous savons que chaque fragment doit être le plus gros possible. Ici, chaque fragment devra donc faire 1 500 octets, sauf peut-être le dernier.
Chaque fragment aura donc la forme suivante :
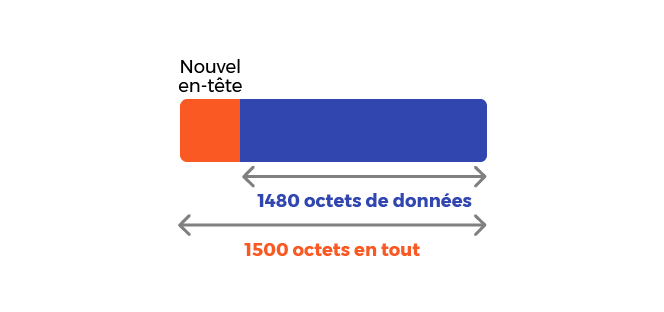
Chaque fragment pourra donc contenir 1 480 octets de données. Au passage, 1 480 est bien un multiple de 8, donc tout va bien !
Notre datagramme d’origine fait 5 600 octets au total, soit 5 580 octets de données. Nous allons maintenant chercher à savoir combien il nous faut de fragments pour transporter ces données.
5580/1480=3,7...
Il va donc nous falloir 3 fragments de 1 480 octets, et un dernier fragment de 5580-(1480*3)=5580-4440=1140 octets
Cela nous donne donc 4 fragments :
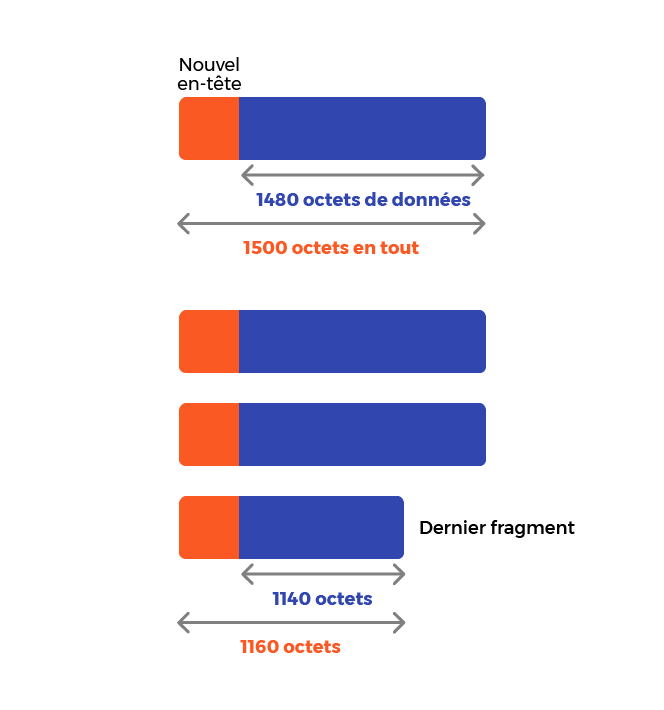
Cherchons maintenant les informations contenues dans les en-têtes IP.
Dans le datagramme d’origine, nous avions :
IPID : 10254 (choisi au hasard pour l’exemple)
Flags : On n’indiquera que MF (More Fragments), qui est ici à 0, car le datagramme est le dernier fragment, vu qu’il n’est pas encore fragmenté.
FO (Fragment Offset) : 0
Dans notre premier fragment :
IPID : 10254 (le même que dans le datagramme d’origine)
Flags : MF=1 (il y a encore des fragments après celui-ci)
FO : 0
Dans le second fragment :
IPID : 10254
Flags : MF=1
FO : 1480/8=185
Dans le troisième fragment :
IPID : 10254
Flags : MF=1
FO : 370 (1480*2/8)
Et dans le dernier fragment :
IPID : 10254
Flags : MF=0 (Cette fois, c’est le dernier fragment !)
FO : 555
Magnifique ! Nous avons réalisé notre première fragmentation !
Cependant, pour nous assurer que nous n’avons pas fait d’erreur de calcul, nous allons faire une petite vérification.
Le fragment offset du dernier fragment représente toutes les données des fragments précédents. Si l’on y ajoute le nombre de ses données, on devrait tomber sur le nombre de données total. Vérifions cela :
(555*8)+1140=4440+1140=5580 octets
Ce qui correspond bien à ce que nous attendions !
Notons au passage une information importante que nous avons utilisée :
Mais même si l’exemple précédent peut vous paraître complexe, il est en réalité très simple. Et nous allons dès maintenant nous attaquer à une fragmentation plus complexe. Si vous n’être pas encore très à l’aise avec celle-ci, refaites cet exercice en changeant la taille du datagramme d’origine, par exemple.
Un second exercice plus complexe
Nous allons maintenant rajouter un peu de piment à notre exercice ! Pour cela, c’est très simple, nous allons considérer le même réseau que précédemment, mais la MTU sur le second réseau ne sera plus de 1 500, mais de 820.
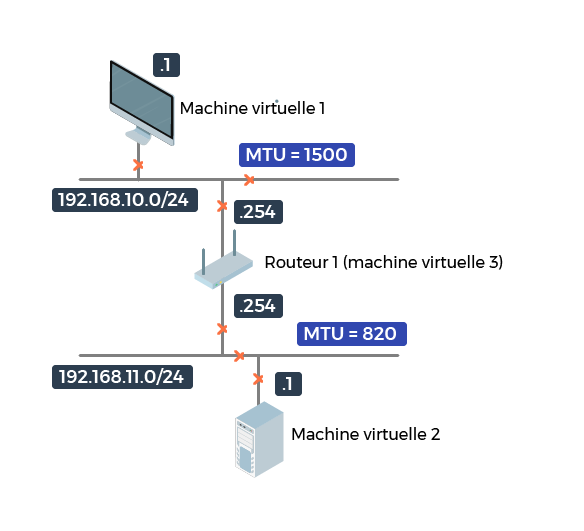
Et cela va malheureusement considérablement nous compliquer la vie !
En effet, la machine 1 connaît la MTU de son propre réseau, qui est à 1 500. Mais elle n’a aucune connaissance de la MTU du second réseau et va donc faire son découpage du datagramme avec la MTU à 1 500.
Le découpage va donc être, dans un premier temps, le même que le précédent, et la machine 1 va envoyer ces fragments sur le réseau.
Mais une fois arrivée au routeur 1, la table de routage de celui-ci va lui dire de les envoyer sur le second réseau qui a une MTU de 820 ! Et là, le routeur a deux choix :
soit il réassemble les fragments et les découpe une nouvelle fois ;
soit il découpe directement les fragments reçus en fragments plus petits.
Et c’est en fait la seconde solution qui est utilisée en réseau, car aucun matériel réseau n’a le droit de réassembler des fragments, sauf la machine destinatrice (et les firewalls parfois pour des raisons de sécurité).
Le routeur va donc découper chacun des fragments qu’il a reçus en fonction de la nouvelle MTU à 820. Les nouveaux fragments vont donc avoir un maximum de 800 octets de données.
Le découpage des fragments contenant 1 480 octets de données va donc être comme ceci :
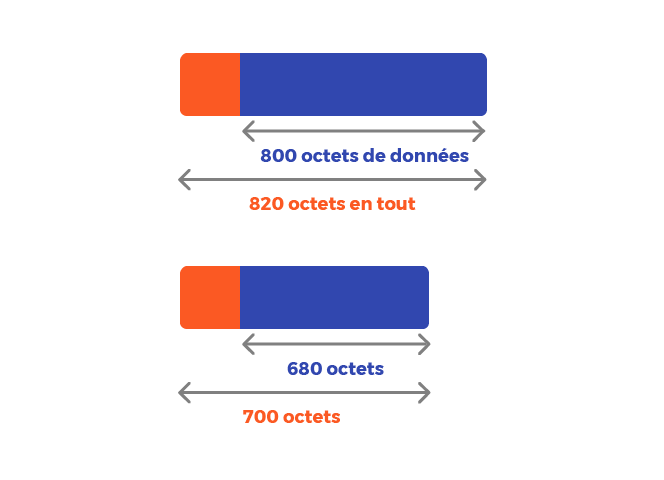
Et ce, pour les trois premiers gros fragments. Il nous reste encore à découper le dernier fragment qui contient 1 140 octets de données :
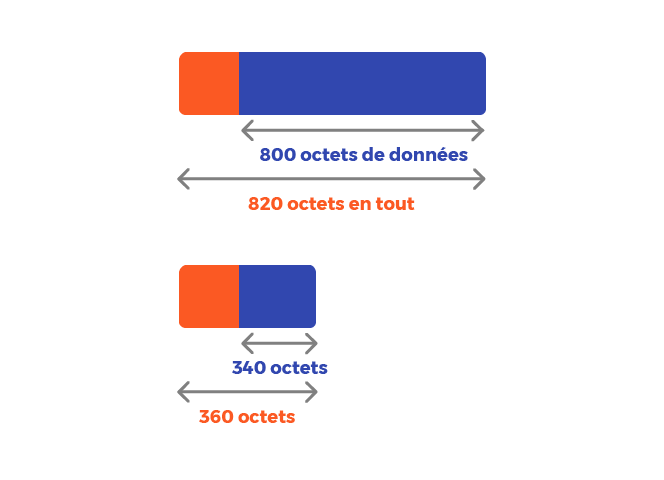
Nous allons donc avoir en tout 8 fragments.
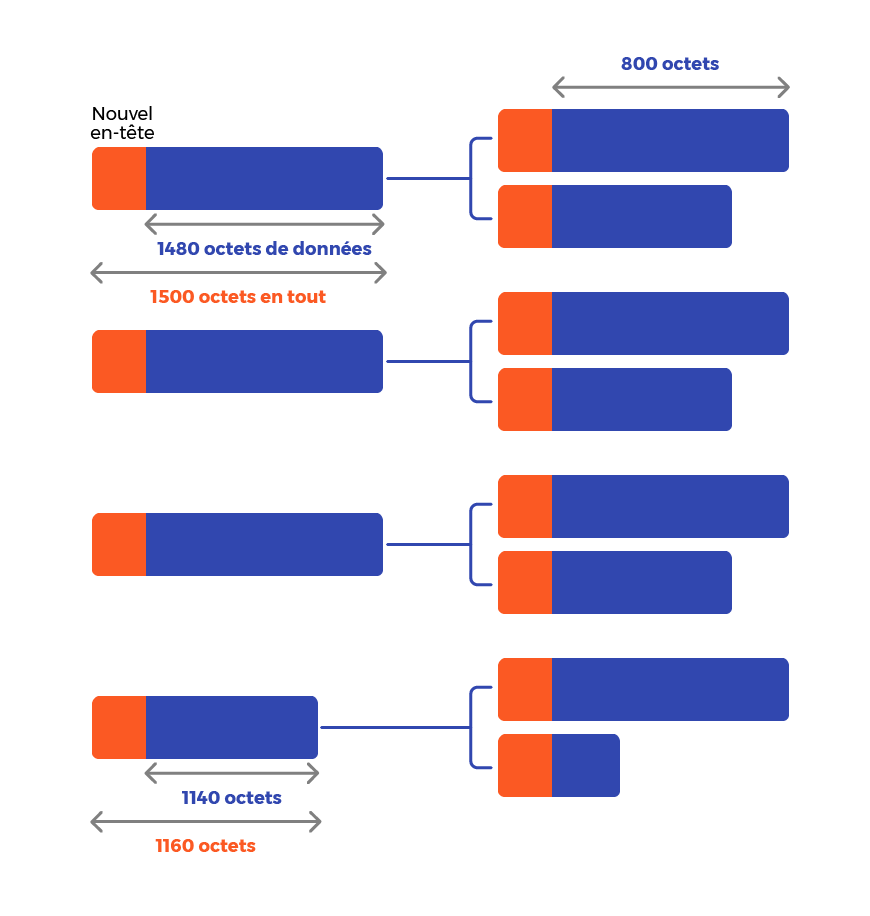
Étudions le contenu de chacun, en présentant d’abord le datagramme d’origine :
IPID : 8652
Flags : MF=0
FO : 0
Qui va donc être découpé en 4 fragments une première fois lors de l’envoi de la machine 1, puis en 8 fragments au passage par le routeur R1.
Le premier fragment contenant 800 octets de données :
IPID : 8652
Flags : MF=1
FO : 0
Le second fragment contenant 680 octets de données :
IPID : 8652
Flags : MF=1
FO : 100 (car le fragment précédent contient 800 octets)
Troisième fragment :
IPID : 8652
Flags : MF=1
FO : 185
Quatrième fragment :
IPID : 8652
Flags : MF=1
FO : 285
Cinquième fragment :
IPID : 8652
Flags : MF=1
FO : 370
Sixième fragment :
IPID : 8652
Flags : MF=1
FO : 470
Septième fragment :
IPID : 8652
Flags : MF=1
FO : 555
Huitième fragment :
IPID : 8652
Flags : MF=0
FO : 655
Nous pouvons faire notre petit calcul pour vérifier que tout cela est bien correct en tenant compte du dernier fragment offset à 655 et des 340 octets de données contenues dans le dernier fragment :
(655*8)+340=5240+340=5580 octets
Parfait ! Cela correspond bien à ce que nous attendions !
Deux petites remarques au passage, que nous avons abordées, et qui sont importantes pour bien comprendre la fragmentation :
Pour ceux qui ne se sentent pas encore tout à fait à l’aise, je vous propose un dernier petit exercice à faire par vous-même avant d’en lire la correction.
Exercice d’entraînement
On prend le schéma réseau précédent, mais avec des MTU différentes, 1 140 pour le premier réseau et 420 pour le second :
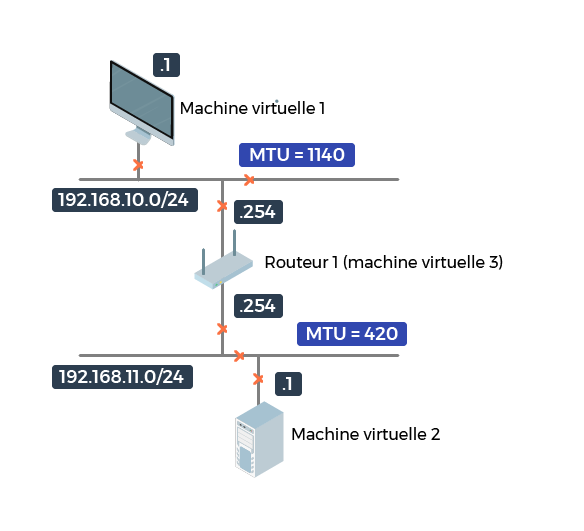
Et la machine 1 souhaite envoyer un datagramme de 4 260 octets à la machine 2.
Écrivez tous les fragments reçus par la machine 2.
Vous pourrez voir la correction à la fin de ce chapitre.
Ce qu’il faut en retenir
Cependant, vous pourriez être en mesure de vous demander à quoi cela va bien pouvoir vous servir.
Certes, la fragmentation est gérée automatiquement et ne génère quasiment jamais de problèmes au niveau réseau.
Cependant, ce que vous venez d’apprendre vous sera utile pour mieux comprendre les mécanismes réseau, et potentiellement ce que vous pouvez observer sur le réseau. Par ailleurs, nous allons aborder la sécurité à la fin de cet ouvrage, et nous verrons que pour faire de la sécurité, il est souvent nécessaire de connaître dans les plus petits détails le fonctionnement d’un protocole ou d’un système.
Il n’est donc pas négligeable de bien connaître le fonctionnement détaillé du protocole IP pour pouvoir étudier en détail ses failles potentielles, les comprendre et pourquoi ne pas en imaginer de nouvelles !
D’ailleurs, nous allons maintenant aborder une attaque liée à la fragmentation. Ainsi, vous verrez qu’avoir des connaissances profondes du fonctionnement d’un système est le meilleur moyen d’imaginer comment contourner son fonctionnement normal pour faire de la sécurité.
Pour aller plus loin
Pour ceux qui le souhaitent, et seulement ceux qui se sentent très à l’aise, je vous propose de réfléchir à une question.
Nous avons parlé précédemment du MTU path discovery. Je vous invite alors à vous renseigner sur ce mécanisme, et à vous demander ce que cela aurait pu changer sur nos précédents exercices.
Correction de l’exercice
Avant de commencer l’exercice, vérifiez bien que les MTU que l’on vous a fournis vous permettent d’avoir un nombre de données qui est un multiple de 8.
Ici, c’est bien le cas pour une MTU de 1 140 (1 120 est un multiple de 8) et pour 420 (400 étant un multiple de 8).
Dans un premier temps, il faut fragmenter le datagramme d’origine selon la MTU de 1 140 octets, ce qui nous donne 4 fragments.
3 fragments comportant 1 120 octets de données, et un dernier fragment de 4240-(1120*3)=880 octets.
Écrivons les informations de fragmentation contenues dans leurs en-têtes :
Fragment 1 :
IPID : 12534
Flags : MF=1
FO : 0
Fragment 2 :
IPID : 12534
Flags : MF=1
FO : 140
Fragment 3 :
IPID : 12534
Flags : MF=1
FO : 280
Fragment 4 :
IPID : 12534
Flags : MF=0
FO : 420
Dans un second temps, ces fragments arrivent au routeur 1 qui doit les fragmenter de nouveau pour qu’ils puissent aller sur le second réseau dont la MTU fait 420 octets.
Chaque gros fragment va donc être découpé en trois fragments, deux premiers contenant 400 octets de données, et le dernier contenant 1120-(400*2)=320 octets de données
Le dernier fragment de 880 octets de données va aussi être fragmenté en trois, deux fragments de 400 octets de données, et un dernier de 80 octets de données.
Ce qui nous donne finalement 12 fragments :
Fragment 1 :
IPID : 12534
Flags : MF=1
FO : 0
Fragment 2 :
IPID : 12534
Flags : MF=1
FO : 50
Fragment 3 :
IPID: 12534
Flags : MF=1
FO : 100
Fragment 4 :
IPID: 12534
Flags : MF=1
FO : 140
Fragment 5 :
IPID: 12534
Flags : MF=1
FO : 190
Fragment 6 :
IPID: 12534
Flags : MF=1
FO : 240
Fragment 7 :
IPID: 12534
Flags : MF=1
FO : 280
Fragment 8 :
IPID: 12534
Flags : MF=1
FO : 330
Fragment 9 :
IPID: 12534
Flags : MF=1
FO : 380
Fragment 10 :
IPID: 12534
Flags : MF=1
FO : 420
Fragment 11 :
IPID : 12534
Flags : MF=1
FO : 470
Fragment 12 :
IPID : 12534
Flags : MF=0
FO : 520
Et comme d’habitude, nous pouvons vérifier notre calcul :
(520*8)+80=4160+80=4240 octets, ce qui correspond bien au nombre de données du datagramme d’origine !
