Anticipez les défaillances matérielles avec une solution RAID logicielle
Vous savez maintenant monter un serveur Linux et gérer des partitions ext4. Si on se projette dans l’optique d’offrir un service de partage de fichiers sur notre réseau local, les deux problématiques qui vont se poser sont :
la fiabilité des données car on ne voudrait pas perdre les données ;
la performance du système car on veut offrir un service rapide et efficace.
Dans ce chapitre, vous allez découvrir les technologies RAID qui ont été créées spécialement pour ça.
Euh, c’est quoi une techno RAID ?
RAID est l’acronyme de Redundant Array of Independent Disks, soit en français regroupement redondant de disques indépendants. C’est un ensemble de techniques qui permet de répartir le stockage de données sur plusieurs disques. Une fois le système mis en place, cette répartition des données est transparente pour l’utilisateur qui ne voit qu’un volume de stockage unique.
Il existe différents niveaux de RAID en fonction de la façon dont les données sont réparties sur les disques. Chaque système a ses avantages et inconvénients et je vais vous présenter les principaux niveaux.
Le RAID 0 pour agréger des disques
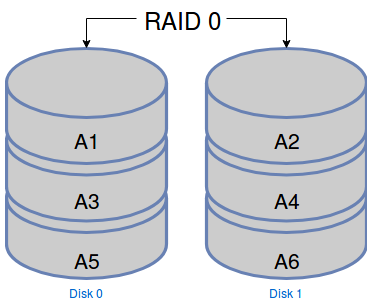
Dans le RAID 0, chaque fichier est réparti par petits bouts sur plusieurs disques. À chaque fois que vous allez lire ou écrire sur votre volume RAID, vos disques durs physiques vont pouvoir travailler en parallèle et les performances vont être bien meilleures que si vous n’aviez qu’un seul disque. Un autre avantage de ce système c’est qu’il n’y a pas de place perdue. Si on a trois disques de 10Go, on aura un volume de stockage utile de 30Go.
L’inconvénient majeur de ce système, c’est que si vous perdez un seul disque de votre volume, vous perdez définitivement l’ensemble des données. Il est donc déconseillé de stocker des données permanentes sur un RAID 0.
Le RAID 1 pour stocker des données en miroir
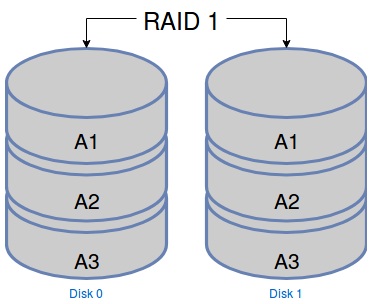
Dans le RAID 1, tous vos disques sont des copies exactes et chaque fois qu’on écrit un fichier, il est écrit sur chacun des disques. L’avantage majeur de ce système, c’est la fiabilité car tant qu’il vous reste au moins un disque, vous n’avez pas perdu de données.
En revanche, ce système n’apporte pas d’amélioration de performance en écriture puisqu’on doit tout écrire sur chaque disque. C’est aussi un système très coûteux en espace de stockage car avec trois disques de 10Go, on n’aura qu’un volume de stockage utile de 10Go.
Le RAID 10, un bon compromis entre fiabilité et performances
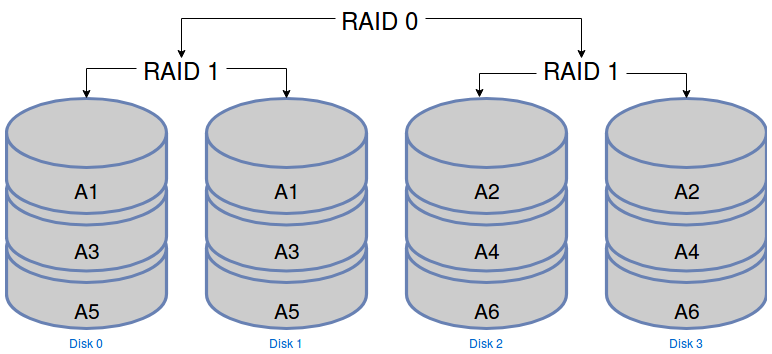
Le RAID 10 est en fait un mélange des deux RAID que nous venons de voir. Il faut d’ailleurs comprendre le 10 comme 1+0. Dans ce système, les disques sont regroupés par grappes en RAID 1 et les fichiers sont répartis sur plusieurs grappes en RAID 0. Il vous faut donc au moins 4 disques pour mettre en place ce type de RAID.
Il offre à la fois :
un bon niveau de fiabilité puisqu’on ne perd aucune donnée tant qu’il reste au moins un disque dans chaque grappe,
et un bon niveau de performance puisque les lectures/écritures sont réparties sur plusieurs disques.
L’optimisation de stockage est moyenne. Avec 4 disques de 10Go, vous aurez un volume de stockage utile de 20Go.
Le RAID 5, fiabilité, performance mais beaucoup de calculs
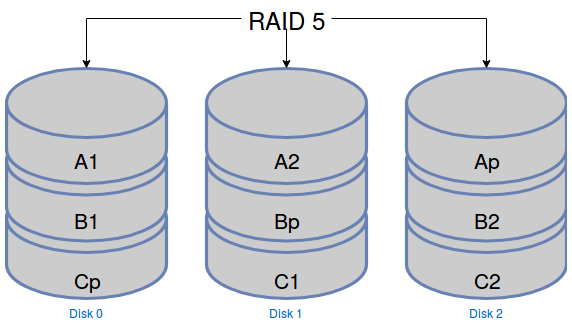
Pour faire du RAID 5, vous aurez besoin d’au moins 3 disques. Cette technique est plus complexe mathématiquement et consiste à répartir les données sur tous les disques en rajoutant des “blocs de parité”. Chaque bloc écrit sur un disque est donc :
soit un bloc de parité : si on le perd, on n’a pas perdu de données et on peut recalculer ce bloc à partir des blocs de données des autres disques,
soit un bloc de données : si on le perd, on peut le retrouver à partir des blocs de données restants et du bloc de parité.
Ce système permet d’améliorer les performances puisque :
les écritures sont réparties sur plusieurs disques,
il permet également une certaine fiabilité puisqu’on peut se permettre de perdre un disque sans perdre de données.
il optimise l’espace de stockage par rapport au RAID 10 puisqu’avec 4 disques de 10Go, vous aurez un volume de stockage utile de 30Go.
Par contre, peu importe le nombre total de disques, vous ne pourrez pas vous permettre de perdre plus d’un disque. Surtout, le calcul des blocs de parité entraîne des calculs processeur non-négligeables pour les écritures et peut augmenter fortement le temps de reconstruction en cas de perte d’un disque.
Il existe d’autres niveaux de RAID mais ils sont moins couramment employés. Avec ces niveaux-là, vous avez une bonne idée de ce qu’il est possible de faire et vous comprenez que tout est question de compromis entre la fiabilité, les performances et le coût.
En pratique, il y a plusieurs façons de gérer un volume RAID :
le RAID matériel : certains serveurs sont équipés d’un contrôleur matériel qui gère le RAID. Le réglage se fait généralement au niveau du Bios de l’ordinateur et les performances sont souvent très bonnes. De plus, vous n’avez rien à régler au niveau de votre système d’exploitation qui verra le volume RAID comme un disque dur.
le fake-RAID ou RAID pseudo-matériel : c’est la version bon marché du contrôleur matériel. C’est une puce qui gère le RAID en utilisant le processeur et la mémoire principale de l’ordinateur. En général, je vous conseille d’éviter.
le RAID logiciel : dans ce cas, le RAID est géré par votre système d’exploitation. C’est une méthode utilisable sur tout matériel, très souple d’utilisation mais qui consomme une petite partie des ressources système.
Pour finir ce chapitre, je vous propose de mettre en place une solution RAID 1 logicielle afin de sécuriser les données de notre serveur.
Mettez en place un RAID 1 logiciel pour sécuriser vos données
Vous allez mettre en place une solution RAID 1 avec trois disques :
un disque de données,
un disque de copie des données,
un “hot spare”, c’est-à-dire une disque de rechange à chaud qui pourra automatiquement prendre la place d’un des deux disques précédents en cas de défaillance.
Pour cela, vous devez d’abord supprimer les entrées liées à votre partition/dev/sdb dans votre fichier /etc/fstab (parce qu’on va tout casser pour mettre en place le RAID). Éteignez votre serveur vm-serveur, rajoutez deux disques de 1Go dans VirtualBox et redémarrez le serveur.
Créez votre volume raid par la commande :
$ sudo mdadm --create /dev/md0 --level=raid1 --raid-devices=2 /dev/sdb /dev/sdc --spare-devices=1 /dev/sdd
Ici, on crée le périphérique /dev/md0 (les volumes RAID ont des noms de type /dev/md* ), on lui dit que c’est du RAID 1, qu’il y a 2 disques en RAID /dev/sdb et /dev/sdc et un disque en “spare” /dev/sdd
Pour fixer les paramètres de votre RAID et éviter que votre périphérique ne change de nom au prochain démarrage, je vous conseille de rajouter la ligne suivante dans le fichier /etc/mdadm/mdadm.conf après le commentaire # definitions of existing MD arrays :
ARRAY /dev/md0 level=raid1 num-devices=2 spares=1 UUID=0e529b88:199915ed:e6e104c5:38db1f03 devices=/dev/sdb,/dev/sdc,/dev/sdd
Vous pouvez trouver votre UUID et d’autres détails sur votre RAID par la commande :
$ sudo mdadm --query --detail /dev/md0 /dev/md0: Version : 1.2 Creation Time : Wed Jun 30 19:08:33 2021 Raid Level : raid1 Array Size : 1046528 (1023.00 MiB 1072.69 MB) Used Dev Size : 1046528 (1023.00 MiB 1072.69 MB) Raid Devices : 2 Total Devices : 3 Persistence : Superblock is persistent Update Time : Wed Jun 30 19:08:38 2021 State : clean Active Devices : 2 Working Devices : 3 Failed Devices : 0 Spare Devices : 1 Name : vm-serveur:0 (local to host vm-serveur) UUID : 0e529b88:199915ed:e6e104c5:38db1f03 Events : 17 Number Major Minor RaidDevice State 0 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc 2 8 48 - spare /dev/sd
Le système de démarrage de votre système a sa propre copie du fichier/etc/mdadm/mdadm.conf. Pour que les modifications sur ce fichier soient prises en compte au prochain démarrage, vous devrez également lancer la commande :
$ sudo update-initramfs -u
Vous pouvez ensuite formater et utiliser votre volume RAID comme n’importe quelle partition :
$ sudo mkfs -t ext4 /dev/md0 #Formatage $ sudo mount -t ext4 /dev/md0 /var/data1 #Montage $ sudo touch /var/data1/mon_premier_fichier_sur_raid #Création d’un fichier vid
Un des gros intérêts du RAID 1 étant de nous prémunir contre les défaillances matérielles, voyons donc ce qui se passe en cas de perte d’un disque.
Reconstruisez votre RAID suite au défaut d’un disque
En cas de perte d’un disque, le RAID permettra à votre système de fonctionner sur la copie valide. Il faudra quand même réagir rapidement et remplacer le disque défaillant avant de perdre votre dernière copie des données. Comme vous avez prévu un disque de rechange, ce processus sera en partie automatisé mais il faudra quand même penser à remettre un disque de rechange.
Pour essayer, vous pouvez simuler la perte du disque /dev/sdb et vérifier que le disque /dev/sdd prend bien le relai automatiquement :
$ sudo mdadm --manage /dev/md0 --fail /dev/sdb $ sudo mdadm --query --detail /dev/md
Les données sont alors copiées du disque restant sur le nouveau disque actif. On parle de reconstruction du RAID. Vous pouvez également suivre les différentes étapes de ce processus dans le fichier de log /var/log/syslog .
Il nous reste à retirer le disque défectueux du RAID :
$ sudo mdadm --manage /dev/md0 --remove /dev/sdb
Il faut alors changer physiquement le disque. Certains contrôleurs disques permettent de le faire à chaud et d’autres nécessitent d’éteindre la machine. Une fois le disque changé, vous pouvez réintégrer le nouveau disque au volume RAID :
$ sudo mdadm --manage /dev/md0 --add /dev/sdb
Vous avez maintenant une partition de données de 1Go comme à la fin du chapitre 2 mais votre installation peut maintenant supporter la perte de deux disques durs avant de perdre des données. Dans le chapitre suivant, vous allez à nouveau diviser votre partition de données en deux mais vous utiliserez cette fois LVM et vous verrez que ce sera bien plus facile.
En résumé
Le RAID permet de gérer la répartition de vos données sur plusieurs disques.
Il existe différents niveaux de RAID selon la manière dont sont réparties les données.
Chaque niveau de RAID présente un compromis performance/fiabilité/coût différent.
Vous connaissez maintenant les niveaux RAID 0, 1, 10 et 5.
Vous avez fiabilisé votre partition de données par du RAID 1.
