Initiez-vous aux méthodes séquentielles et au Boosting
Dans cette seconde partie, intéressons-nous à la seconde famille de méthodes ensemblistes, les méthodes séquentielles.
Les méthodes séquentielles, qu'est-ce que c'est ?
Imaginez le problème suivant : on veut déterminer si un champignon est toxique ou pas, à partir de certaines caractéristiques (couleur, taille, odeur, etc).

Pour cela, nous disposons d’un jeu de données d’entraînement contenant un vecteur d’observations de différents champignons X, ainsi qu’un label binaire indiquant s’il est effectivement toxique.
Un modèle de classification C(X) retourne la prédiction binaire “toxique” ou “non toxique”. Ça peut être n’importe quel modèle de classification étudié précédemment (réseau de neurones, SVM, etc). De la même manière que les algorithmes de bagging, les algorithmes de boosting utilisent des algorithmes de classification dits “faibles” qui performent à peine mieux qu’un classifieur aléatoire.
On entraîne donc un premier classifieur sur le jeu de données. Comme il effectue un certain nombre d’erreurs, on décide d’augmenter le poids associé aux observations qui induisent en erreur, afin de leur donner plus d’importance dans l’entraînement. On entraîne ainsi un second classifieur avec ce nouveau jeu de données pondéré, ce qui lui permet de se concentrer sur ces observations qui induisent en erreur . On crée de la sorte une suite de classifieurs qui s’appuient chacun sur les erreurs effectuées par le classifieur précédent pour repondérer un nouveau dataset sur lequel s’entraîner.
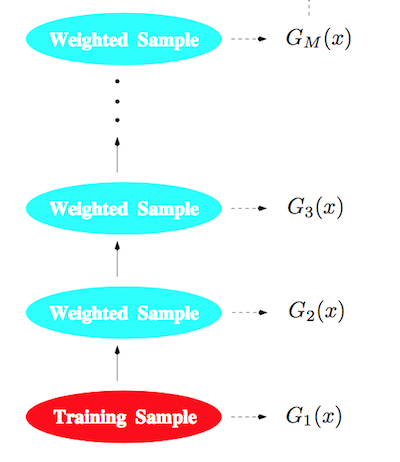
On peut maintenant combiner ces différents classifieurs afin d’obtenir notre classifieur final le plus performant.
Adaboost
Pour obtenir ce classifieur final, il nous suffit d’effectuer la somme pondérée des différents classifieurs.
Comme un classifieur binaire retourne une réponse binaire, on récupère le signe de cette somme
Il manque quelque chose. C’est dommage de donner autant d’importance à chacun des classifieurs, même ceux qui performant mal au global. Voyons ce qu’on peut faire. Chaque classifieur possède son taux d’erreur sur le jeu de données pondéré :
Pour accorder une plus grande importance à ceux qui ont le taux d’erreur global le plus faible, on pondère notre somme par le poids .
On a donc notre classifieur final
Il nous reste une dernière question... Comment pondérer le jeu de données à chaque étape ? Chaque classifieur est entraîné sur un jeu de donnée pondéré qui accorde plus d’importance aux observations qui ont induit en erreur le classifieur précédent. On va donc utiliser notre poids . Pour chaque observation , on pondère par le poids
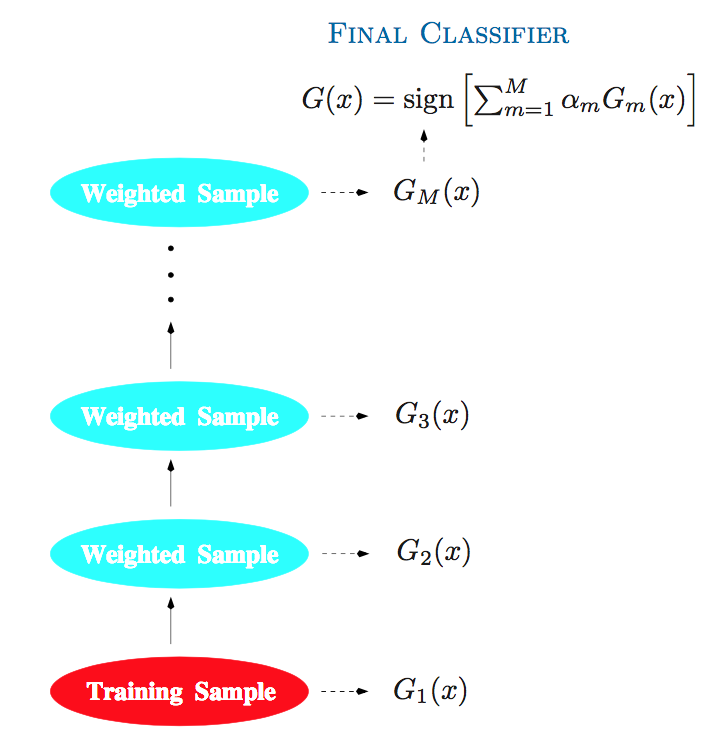
L’algorithme final du Adaboost pour une classification binaire est donc :

L’Adaboost peut aussi être utilisé en régression ou en classification multiclasse, mais le principe reste le même.
Je rappelle les différents choix et hyperparamètres qui caractérisent l’algorithme :
la fonction de perte utilisée
le type de classifieur. Le plus utilisé est l’arbre de décision mais on pourrait techniquement utiliser un réseau de neurones ou un SVM.
la taille M de la séquence de classifieurs.
Boosting d'arbres aléatoires
Avec l’Adaboost, on va le plus souvent utiliser nos bons vieux apprenants faibles que sont les arbres aléatoires. Mais on va même faire encore plus simple que ça, on va utiliser ce qu’on appelle en anglais des stumps c’est-à-dire des arbres qui ne font qu’une seule séparation, avec un seul noeud !
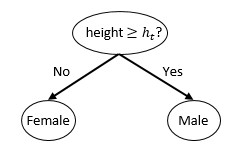
Conclusion
Maintenant qu'on a une meilleure idée de la technique du boosting originale, on peut passer à la plus utilisée de nos jours : le gradient boosting !
