Téléchargez les jeux de données analysés dans ce cours
Nous illustrerons les chapitres qui suivent à l’aide de 3 jeux de données.
Échantillon n°1 : Les cours OpenClassrooms
Nous allons utiliser des données que vous connaissez bien : les cours OpenClassrooms que vous avez suivis. La liste de ceux-ci est disponible sur votre page d'accueil : https://openclassrooms.com/dashboard.
Dans cet échantillon, chaque individu est un cours que j'ai suivi. Voici le détail des variables :
titreCours : le titre du cours ;
idCours : l'identifiant du cours ;
inscription : nombre de jours écoulés depuis votre inscription au cours ;
progression : votre progression sur le cours (en pourcentage) ;
moyenneDeClasse : moyenne de la classe aux évaluations (en pourcentage) ;
duree : durée estimée du cours (en heures) ;
difficulte : difficulté estimée du cours (1 : facile... 3 : difficile) ;
nbChapitres : nombre de chapitres ;
nbEvaluations : nombre d'évaluations dans le cours (comprend les quiz et les activités) ;
ratioQuizEvaluation : proportion de quiz par rapport au nombre total d'évaluations (nombre d'évaluations : nombre de quiz + nombre d'activités).
Échantillon n°2 : Le texte de cours OpenClassrooms
Le second provient de la plateforme OpenClassrooms. J’ai tout simplement récupéré le texte de différents cours.
Plus précisément, j'ai récupéré les cours de 12 parcours de formation. Un parcours (ex. : le parcours Data Analyst) est composé de plusieurs cours.
Voici la liste de ces parcours, qui est développée plus en détail dans le fichier courses_info.csv :
thématique Data :
parcours Data Analyst,
parcours Data Architect,
parcours Data Scientist ;
thématique Développement :
Développeur·se d'application – Python,
Développeur·se web junior,
Développeur·se d'application – PHP / Symfony ;
thématique Marketing :
Community Manager,
Responsable Marketing opérationnel et Communication,
Expert·e en stratégie marketing et communication ;
thématique Ressources humaines :
Gestionnaire de paie,
Manager Ressources humaines,
Chargé·e de gestion des ressources humaines.
Dans tous ces textes, nous nous intéresserons aux mots qui les composent.
Mais comment représenter des textes au format dont nous avons l’habitude, c’est-à-dire un tableau avec des lignes et des colonnes ?
En utilisant l’approche « sac de mots », ou « bag of words » en anglais. Elle consiste à représenter les textes en un tableau dans lequel chaque ligne correspond à un texte, et chaque colonne correspond à un mot. Dans chaque case, on indique l’effectif ou la fréquence du mot en question dans le texte. Par exemple, prenons ces 3 textes :
J’aime les statistiques. Surtout les statistiques inférentielles.
J’aime le chocolat noir.
Bonjour !La représentation en bag of words sera la suivante, en représentant les effectifs des mots :
| j | aime | les | statistiques | surtout | inférentielles | le | chocolat | noir | bonjour |
texte 1 | 1 | 1 | 2 | 2 | 1 | 1 | 0 | 0 | 0 | 0 |
texte 2 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 |
texte 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
Pour avoir la représentation avec les fréquences des mots, il faut diviser chaque nombre par le nombre total de mots que contient le texte. Par exemple, la fréquence de « statistiques » dans le texte 1 est de 2/8 = 0,25.
Voici un aperçu du jeu de données bag_of_words.csv, avec les fréquences des mots :
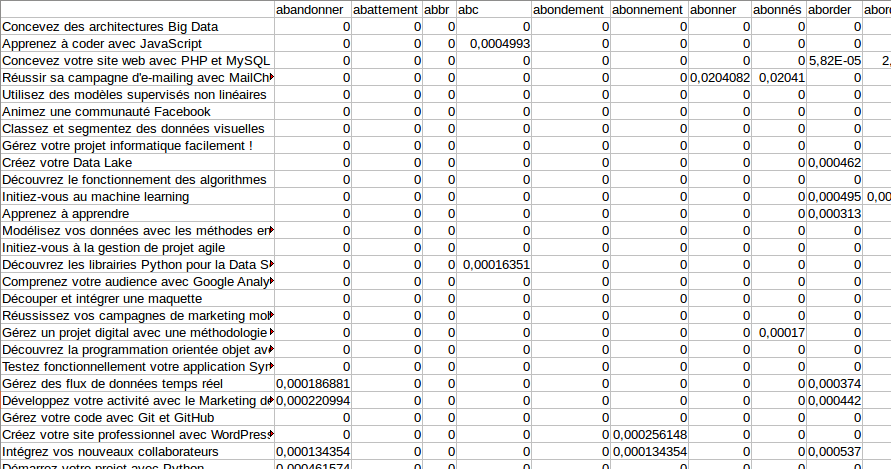
Ce jeu de données contient 9 343 variables (soit 9 343 colonnes) et 105 individus (correspondant aux 105 cours).
Échantillon n°3 : surprise !
Pour le 3e échantillon… j’ai envie de vous laisser la surprise pour plus tard ! Je ne vous dis pas à quoi il correspond. Je vous dis juste qu’il est composé de 5 000 individus et de 3 variables qualitatives, que nous appellerons x, y et z.
Voici juste deux indices, les graphiques de dispersion de :
x et y :
x et z :