Effectuez une classification hiérarchique
Dans ce chapitre, nous allons voir un autre type de partitionnement : la classification hiérarchique.
Fonctionnement de la classification hiérarchique
Regardez ces données : combien de clusters y voyez-vous ?
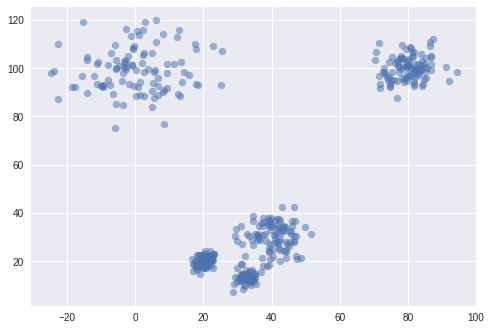
Certains diront 5, d'autres 4, ou encore 3. En effet, il y a 5 groupes bien distincts, mais deux d'entre eux sont très rapprochés : on peut donc considérer qu'ils ne forment qu'un seul cluster et répondre 4. Ces deux clusters très proches sont également relativement proches d'un troisième : si on les regroupe, on considère donc qu'il y a 3 clusters.
En fait, il n'y a pas vraiment de bonne réponse : tout dépend du contexte et des objectifs poursuivis.
On comprend ici l'aspect hiérarchique : ceux qui auront répondu 3 ont eu une vue très générale, alors que ceux qui ont répondu 5 ont préféré avoir une analyse plus fine, plus en profondeur. C'est donc le niveau de profondeur qui détermine une hiérarchie : avec une analyse générale, on voit 3 clusters, mais si l'on creuse un peu plus, on peut diviser l'un de ces 3 clusters en 2 sous-clusters. En allant un peu plus loin, on peut encore diviser l'un de ces 2 sous-clusters en 2 autres. Cette notion de "sous-clusters" est résumable par un arbre :
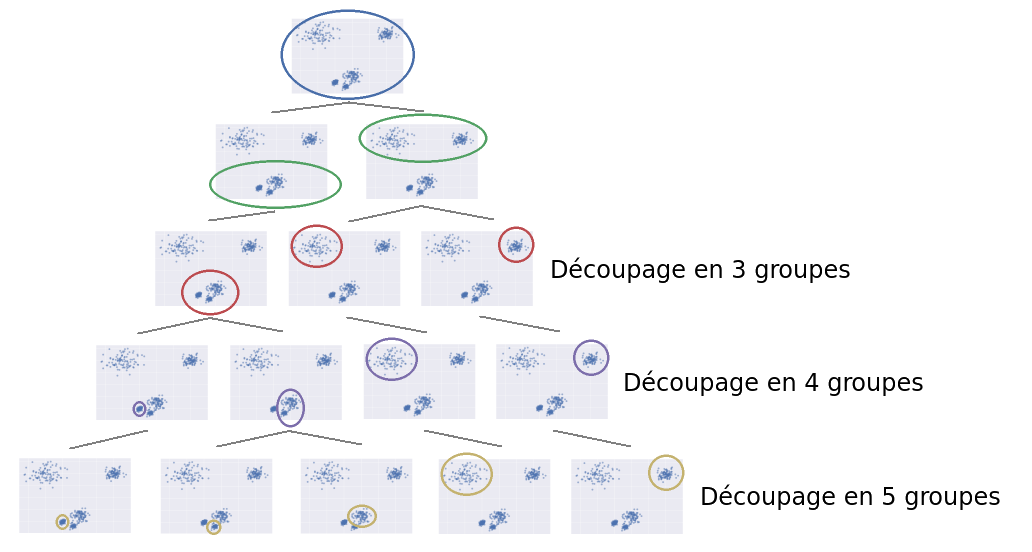
La notion de profondeur est visible ici à travers l'axe vertical. En effet, on peut "couper" l'arbre plus ou moins haut. Si on le coupe peu profondément, on trouve 3 clusters. Si l'on descend un peu plus bas, on en trouve 5.
Cela ne vous rappelle rien ? Quelques souvenirs de cours de biologie au collège, par exemple ?
Regardez par exemple ce graphique :
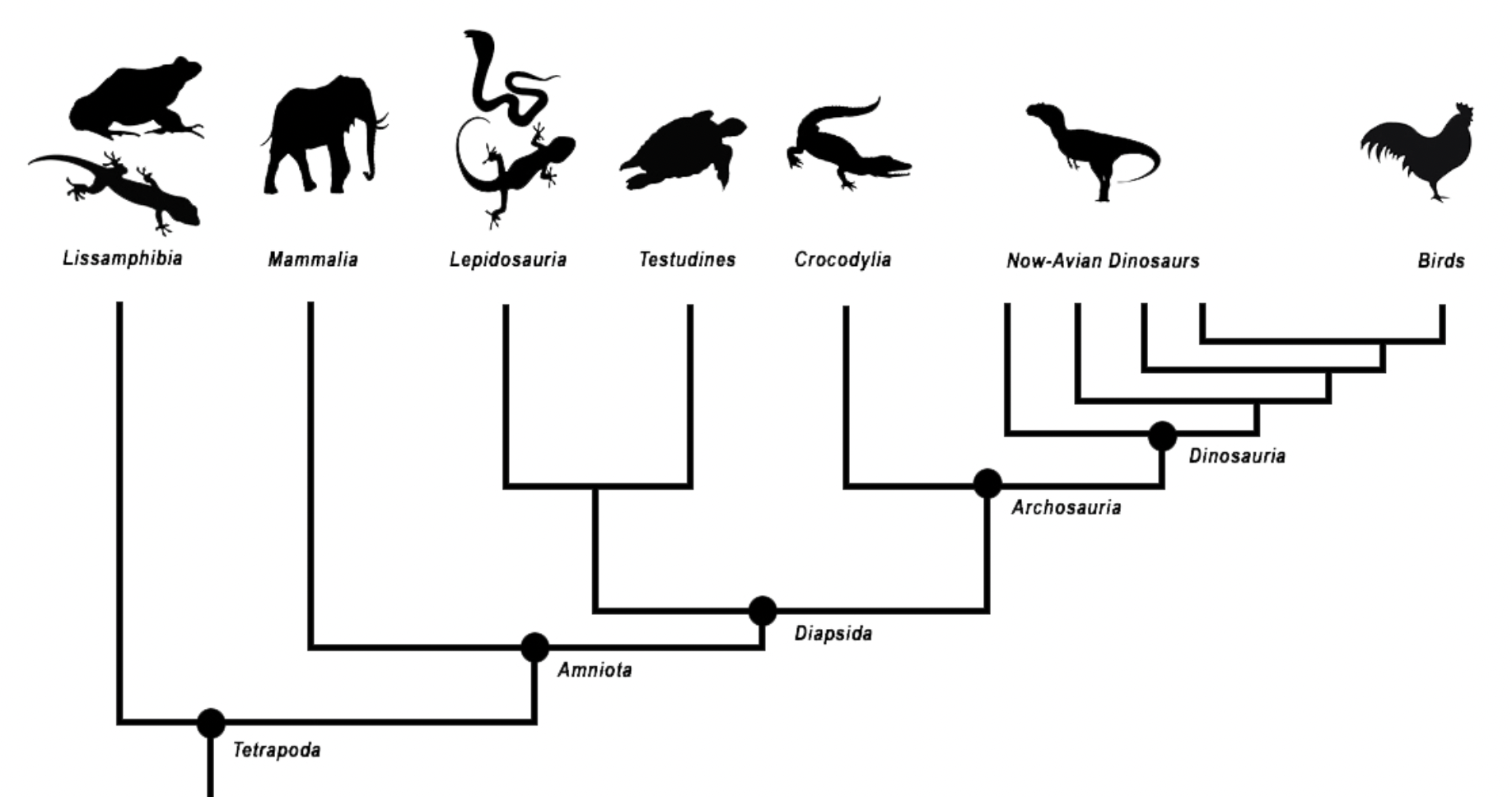
Vous pouvez trouver l'image originale sur Wikipedia.
{kind=link}
C'est une classification hiérarchique aussi ! Il s'agit plus précisément du "Cladogramme des tétrapodes illustrant la position phylogénétique des mammifères".
Si vous n'avez rien compris, c'est normal ! Mais chaque classe "parent" a deux classes "enfants", les points sont des nœuds et les classes finales sont des feuilles.
Ce qui est important, c'est que c'est un arbre qui regroupe les espèces les plus similaires les unes aux autres de façon hiérarchique.
Essayons un autre exemple :
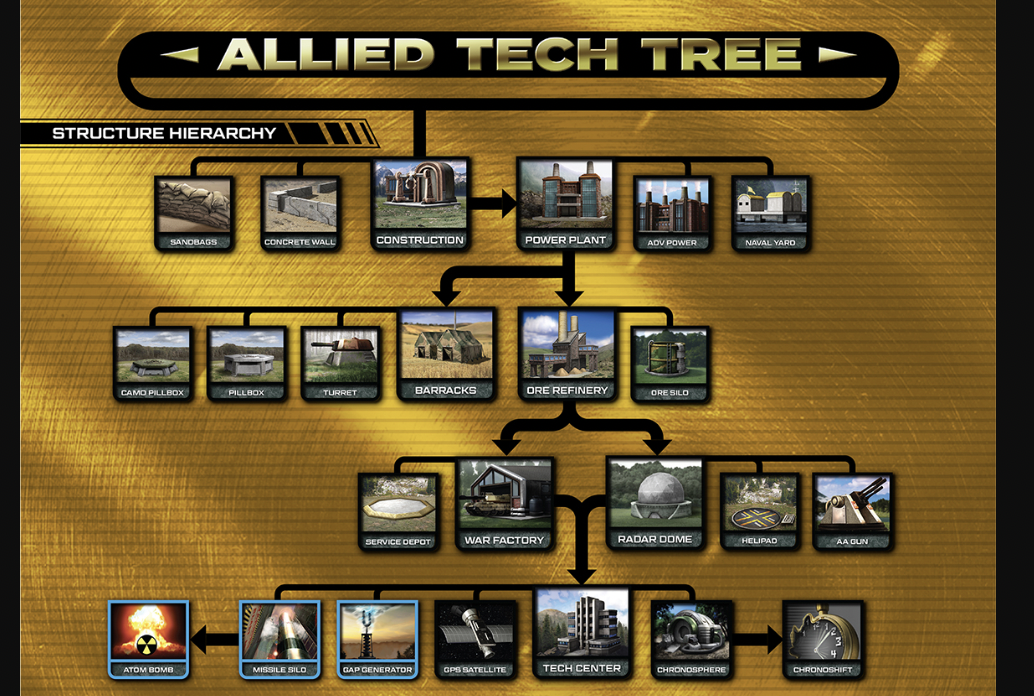
Voilà l'image originale, iI s'agit de l'arbre des technologies d'un vieux jeu vidéo.
Est-ce une autre forme de classification hiérarchique ? Eh bien, pas au sens où nous l'entendons. Certes, cela y ressemble grandement. Mais certaines technologies n'ont qu'un(e) seul(e) fils/fille (construction -> powerplant), et on trouve parfois deux technologies qui pointent vers la même (war factory et radar dome -> tech center). Cela n'est pas possible dans notre problématique de clustering.
C'est lié à la méthode même de classification qui regroupe récursivement les individus deux à deux.
Maintenant que nous en savons plus, petite question : "Quid de votre arbre généalogique"? Vous pouvez prendre un papier et un stylo, refaire votre arbre généalogique et réfléchir à la question :).
Classification ascendante et descendante
Il y a deux approches pour créer une partition hiérarchique :
l'approche ascendante, aussi appelée clustering agglomératif : on considère tout d'abord que chaque point est un cluster. Il y a donc autant de clusters que de points. Ensuite, on cherche les deux clusters les plus proches, et on les agglomère en un seul cluster. On répète cette étape jusqu'à ce que tous les points soient regroupés en un seul grand cluster ;
l'approche descendante, aussi appelée clustering divisif : c'est l'inverse. On part d'un grand cluster contenant tous les points, puis on le divise successivement jusqu'à obtenir autant de clusters que de points.
On obtient donc une arborescence qui a un cluster tout en haut, et qui se divise petit à petit jusqu'à avoir autant de clusters que de points. On appelle cette arborescence un dendrogramme.
Le dendogramme
Le dendrogramme est un outil absolument incontournable quand on fait une classification hiérarchique. Rassurez-vous, le terme a l'air compliqué et il n'est pas facile à prononcer, mais il désigne un concept très simple.
En effet, le dendrograme c'est tout simplement l'arbre qui regroupe les différents clusters.
Voici un exemple de dendrogramme :
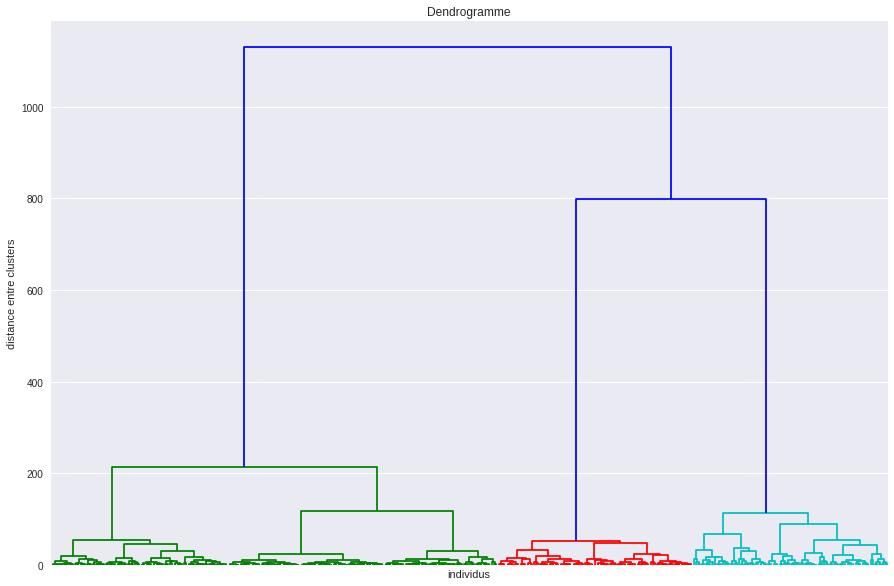
La clé ici, c'est la distance entre clusters, sur l'axe des y . Plus elle est grande, plus il y a de clusters.
Tout en haut de cet axe il n'y a un qu'un cluster, et tout en bas de cet axe il y a autant de clusters que d'individus. Si maintenant on veut faire une partition avec 2 clusters, il suffit de "couper" l'arbre à une hauteur de 1 000. Si on veut 3 clusters, on coupe à 600, 4 clusters à 200, etc., etc.
Il reste encore bien des choses à dire, mais nous les couvrirons dans une vidéo annexe.
Dernier point sur le dendrogramme, si vous avez beaucoup de points, le bas du dendrogramme risque d'être illisible, c'est pourquoi on ne représente parfois que le haut de l'arborescence.
Tu nous as parlé de distance entre clusters. Mais concrètement, c'est quoi la distance entre clusters ?
Très bonne question ! Nous allons traiter ce point tout de suite...
Méthode des liens et méthode de Ward
Que ce soit avec l'approche ascendante ou descendante, on a besoin de mesurer la distance entre 2 clusters.
La distance entre 2 points, c'est assez intuitif. Mais comme un cluster est composé de plusieurs points, il y a différentes manières de considérer une distance entre 2 clusters. On les appelle les méthodes de lien (linkage methods), car ce sont elles qui permettent de lier les clusters lorsque l'on construit petit à petit l'arborescence.
On a :
Le lien simple (simple linkage) : on considère que la distance entre 2 clusters est la distance entre leurs 2 points les plus proches. Cela est équivalent à dire "deux clusters sont proches si au moins deux de leurs points sont proches".
Le lien complet (complete linkage) : on considère que la distance entre 2 clusters est la distance entre leurs 2 points les plus éloignés. Cela équivaut donc à dire "deux clusters sont proches si tous leurs points sont proches".
Le lien moyen : on considère que la distance entre 2 clusters est la moyenne de toutes les distances entre les points d'un cluster et les points de l'autre cluster. Pour la calculer, on énumère toutes les paires de points possibles d'un cluster à l'autre, puis on calcule la distance de chaque paire, puis on calcule la moyenne.
Le lien centroïdal : on considère que la distance entre 2 clusters est la distance entre les centroïdes de ceux-ci.
Les méthodes de lien permettent de garantir que les clusters sont bien séparés, car on prend en compte la distance entre les clusters.
Cependant, elles ne garantissent pas que les clusters soient resserrés sur eux-mêmes (c'est la notion d'inertie intraclasse). Pour résoudre cela, il existe la méthode de Ward qui, à chaque itération, c'est-à-dire à chaque fois que 2 clusters sont regroupés en 1, cherche à minimiser l'augmentation d'inertie intraclasse due au regroupement des 2 clusters.
Avantages et inconvénients
Contrairement au k-means, la classification hiérarchique ne nécessite pas de déterminer un nombre de classes au préalable. En effet, en jouant sur la profondeur de l'arbre, on peut explorer différentes possibilités et choisir le nombre de classes qui nous convient le mieux.
Ce choix peut se faire en regardant les inerties intraclasse et interclasse, ou en utilisant d'autres critères. Nous pouvons choisir un nombre de classes en observant le dendrogramme.
Cependant, il y a des chances pour que l'algorithme de classification hiérarchique mette du temps avant de vous fournir son résultat. En effet, à chaque itération (c'est-à-dire à chaque fois que l'on divise un cluster en 2 pour l'approche descendante, ou que l'on regroupe 2 clusters pour l'approche ascendante), il faut recalculer les distances de toutes les paires de points possibles entre les 2 clusters en question !
Cela nécessite beaucoup de temps et beaucoup d'espace mémoire. On dit que cet algorithme a une forte complexité algorithmique en temps et en espace, c'est-à-dire que vous manquerez peut-être de temps ou d'espace mémoire, même avec un jeu de données de taille moyenne.
Le clustering hiérarchique est donc plus adapté aux petits échantillons.
Oui, mais tu nous disais que le clustering pouvait justement servir à réduire les dimensions du jeu de données (en regroupant des lignes) si celui-ci est trop gros. Si l'on ne peut pas utiliser la classification hiérarchique sur un gros échantillon, à quoi cela sert-il ?
Effectivement. Mais il y a une petite astuce qui permet de combiner les avantages d'un algorithme rapide mais qui offre peu de flexibilité, comme le k-means, avec le confort d'une classification hiérarchique. Si par exemple vous avez un échantillon contenant 10 000 individus, vous pouvez commencer par les regrouper en 50 clusters, en extraire les 50 centroïdes, puis appliquer un clustering hiérarchique sur ces 50 centroïdes. Avec le dendrogramme, vous pourrez ainsi choisir le nombre de clusters (compris entre 1 et 50) qui vous convient !
En pratique
Commençons par les imports :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from scipy.cluster.hierarchy import dendrogram, linkageOn charge nos données. Ici on prendra le dataset iris fourni par scikit-learn :
# On charge le dataset iris :
iris = datasets.load_iris()
# On extrait X :
X = iris.data
# On peut le transformer en DataFrame :
X = pd.DataFrame(X)
# Cela permet d'appliquer la méthode .head :
X.head()Grâce à la librairie scipy, on peut calculer nos distances très simplement. Cette matrice de distance est notée en général Z :
Z = linkage(X, method="ward")Ensuite, on peut afficher notre dendrogramme. Dans l'exemple ci-dessous, on spécifie qu'on ne veut que 10 clusters affichés, pour ne pas avoir un arbre illisible.
fig, ax = plt.subplots(1, 1, figsize=(12, 8))
_ = dendrogram(Z, p=10, truncate_mode="lastp", ax=ax)
plt.title("Hierarchical Clustering Dendrogram")
plt.xlabel("Number of points in node (or index of point if no parenthesis).")
plt.ylabel("Distance.")
plt.show()Allez plus loin
Pour ceux qui veulent plonger dans le code, je vous invite à consulter ce notebook.
Si vous souhaitez approfondir la compréhension du fonctionnement de la classification hiérarchique, nous vous conseillons l'excellente vidéo de François Husson.
En résumé
La classification hiérarchique est un algorithme de clustering très utilisé.
Elle peut être ascendante ou descendante.
Il n'est pas nécessaire de spécifier un nombre de clusters initial pour lancer l'algorithme.
Pour visualiser le partitionnement des données, on utilise un dendrogramme.
La classification hiérarchique est un algorithme déterministe, elle produira toujours le même dendrogramme.
On peut spécifier plusieurs méthodes de calcul des distances afin de produire différents clusters. On utilise en général la méthode de Ward.
Ce nombre de clusters peut se déterminer à posteriori en prenant en compte la profondeur du dendrogramme.
C'est un algorithme qui peut être très long. En effet, pour la classification ascendante par exemple, il faut calculer les distances des points 2 à 2, puis regrouper 2 points et recommencer...
Il ne convient pas pour de trop grands jeux de données.
Vous êtes prêt à découvrir maintenant comment interpréter votre partition ? Alors, suivez-moi au prochain chapitre !
