Comprenez l'enjeu de l'analyse en composantes principales
Qu'allons-nous voir dans cette 2e partie ?
Cette partie est assez conséquente, mais passionnante ! Vous y découvrirez la plus emblématique des méthodes factorielles : l'analyse en composantes principales, très souvent appelée PCA (pour Principal Component Analysis). Ici, nous l’appellerons ACP.
L’ACP est cruciale et stratégique pour un data analyst. Il est donc très important de bien la comprendre. Elle nécessite un minimum de pratique pour analyser les données correctement. Si la compréhension est approximative, elle mène alors très facilement à des analyses erronées, imprécises.
Cette partie est composée de :
1 chapitre, simple à appréhender : Comprenez l'enjeu de l'ACP ;
1 chapitre un peu plus mathématique, où l'on plonge dans la « machinerie » interne de l’ACP : il est important pour la compréhension des 2 chapitres suivants ;
4 chapitres qui traitent du vif du sujet :
1 chapitre sur le cercle des corrélations,
1 chapitre sur la projection des individus sur le premier plan factoriel,
1 chapitre sur le choix du nombre de composantes,
1 chapitre de pratique : il est important pour la pratique, car il donne quelques exemples concrets d'analyses.
L'enjeu de l'ACP
Nous avons parlé précédemment du nuage de points par lequel on représente les individus.
C’est ce nuage que nous souhaitons étudier, et donc visualiser. Mais comme nous l’avons déjà évoqué, nous avons un petit souci pour visualiser ce nuage de points. En effet, il a souvent plus de 2 dimensions, alors que nos écrans sont en 2 dimensions. Un écran ou une feuille de papier sont des plans.
Pour visualiser des points dans un espace à dimensions (avec ) sur un plan, la solution est d’effectuer une projection orthogonale.
Le mot projection vous évoque peut-être une projection de cinéma, ou bien le fait de lancer un objet sur un mur, comme le font certains artistes quand ils projettent de la peinture sur une toile.
Dans les 2 cas, il s’agit de la même chose : pour le cinéma, on projette une image (l’image d’un acteur).
Dans la réalité, cet acteur est à 3 dimensions (non, un être humain n’est jamais plat !), mais l’image projetée sur l’écran est en 2 dimensions, car l’écran de cinéma est un plan. De même, la toile du peintre est aussi plane, alors que les gouttes de peinture qui y sont projetées sont à peu près sphériques, donc en 3D.
La projection mathématique, c’est la même chose : c’est représenter des points à dimensions dans un espace plus « petit », c’est-à-dire à dimensions, avec .
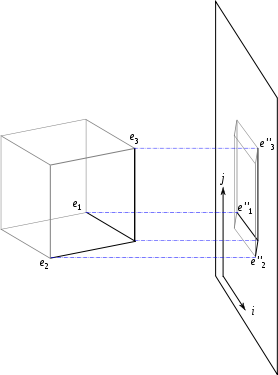
(Source : Wikipedia, projection orthogonale)
Eh oui ! Reprenons l’exemple du cinéma. Imaginons que l’acteur soit face à la caméra et qu’il tienne dans ses mains une règle graduée en centimètres, face à la caméra. La règle est à la même distance de la caméra que l’acteur.
Sur l’écran de cinéma, vous pouvez facilement savoir quelle distance sépare les 2 yeux de l’acteur grâce à la règle graduée. Vous pouvez également mesurer l’espacement entre ses 2 oreilles ou même la taille de l’acteur. Vous avez donc une bonne appréhension d’au moins 2 dimensions : la largeur et la hauteur.
Cependant, pour la 3e dimension (la profondeur), c’est plus compliqué. En effet, vous ne pouvez pas mesurer avec précision la distance entre le ventre de l’acteur et son dos, ni même la distance entre le bout de son nez et le reste de son visage. Pour mesurer ces 2 longueurs, il faut placer la règle dans le sens de la profondeur, et il vous est impossible d’appréhender avec précision cette profondeur sur un écran de cinéma. C’est pour cela que l’on dit qu’il y a une perte d’information : vous perdez l’information de la profondeur.
Perdre de l’information, c’est frustrant !
Oui ! Il faut essayer de perdre le moins d’information possible.
Cela tombe bien, car pour un même objet (l’acteur, par exemple), il y a plusieurs projections possibles : en fonction de là où se place la caméra. La caméra peut se placer au-dessus de l’acteur, ou de profil, de face, ou même en contre-plongée, un peu en biais, etc.
Mais avez-vous déjà vu un film dans lequel les acteurs sont filmés constamment du dessus, ou même du dessous ?


« Non », me direz-vous, car on ne verrait rien ! Rien, ou en tout cas, pas grand-chose.
Effectivement, on verrait moins bien que quand les acteurs sont filmés de face. Dire « on ne voit pas grand-chose » équivaut à dire « on perd beaucoup d’information » . Vu de dessus, on perd par exemple l’information de l’expression du visage : l’acteur est-il heureux ? triste ?

Il y aurait donc des projections qui seraient meilleures que d’autres ?
Tout à fait, il y a des projections pour lesquelles on voit moins bien que d’autres, avec lesquelles on perd plus d’information que d’autres.
Tout l’enjeu est donc de trouver une projection pour nos données qui perde le moins d’information possible.
Pourquoi voit-on mieux un acteur de face que de dessus ?
La principale raison est que la forme de l’être humain est allongée : notre hauteur est plus grande que notre largeur. Ainsi, l’image d’un acteur sera plus « allongée » s’il est filmé de face plutôt que d'en haut. Son image sera plus « étalée » à l’écran.
Une image « étalée » ? Cela me rappelle quelque chose !
Oui, nous avons déjà vu cette notion précédemment : c’est la notion d'inertie.
Des points très étalés ont une grande inertie.
Le principe de l'ACP
Pour commencer simplement, nous chercherons une projection sur un axe (à 1 dimension) plutôt que sur un plan.
La question est de savoir comment positionner cet axe dans l’espace pour que la projection orthogonale du nuage de points sur celui-ci soit la plus étalée possible.
Nous appellerons cet axe premier axe principal d’inertie, que l'on note .
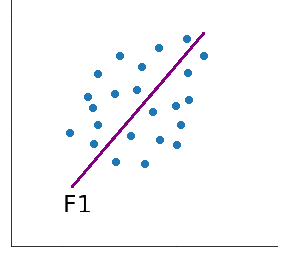
Par cette projection sur le premier axe , nous perdons de l’information. Pour en perdre moins, on peut ensuite chercher un second axe d’inertie principal, .
Mais pour ce second axe, nous fixons une règle : il doit être « perpendiculaire » au premier.
Si l’espace de nos données est à 2 dimensions, alors nous n’avons pas le choix : il n’y a qu’une seule direction possible pour ce second axe (c’est la direction donnée par votre équerre quand vous la posez sur le 1er axe d’inertie). Mais si nous sommes à plus de 2 dimensions, il y a plusieurs solutions.
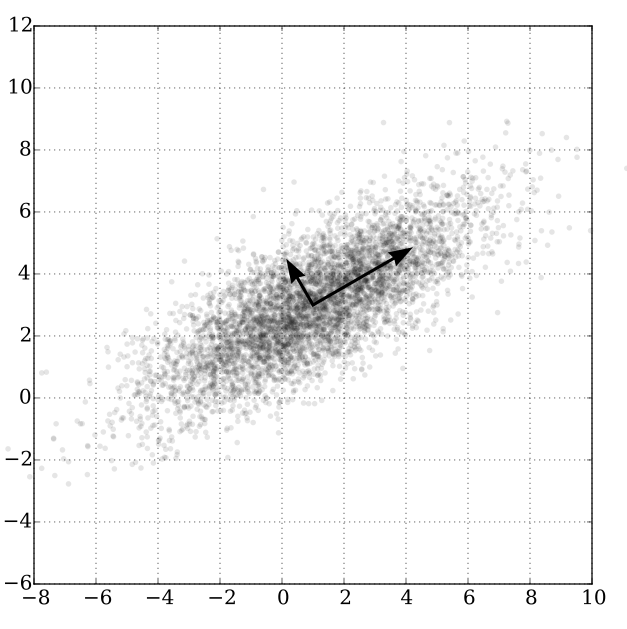
Une fois la direction de ce second axe trouvé, on cherchera le 3e ( ), avec la contrainte qu’il soit orthogonal à tous les précédents : au second, mais aussi au premier. Ensuite, nous chercherons le 4e, orthogonal à tous les précédents, etc.
Pas des variables qui sortent de nulle part, non ! Mais des variables qui sont calculées à partir des variables déjà existantes (c’est-à-dire les variables de notre échantillon, que nous appelons « variables initiales »).
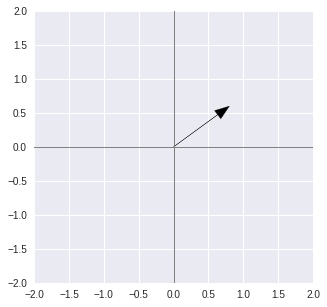
Il faut savoir que les axes principaux d'inertie sont des combinaisons linéaires des variables initiales. Par exemple, si nous travaillons avec un échantillon décrit par 2 variables et , alors on peut obtenir un axe principal d’inertie que l’on peut considérer comme une nouvelle variable , qui sera par exemple de cette forme :
| x | y | F1 |
individu 1 | 1 | 2 | 2 |
individu 2 | 0 | 3 | 1.8 |
individu 3 | -1 | 1 | 0.2 |
... | ... | ... | ... |
Pour représenter cet axe principal d’inertie, il suffit de tracer le vecteur de coordonnées (0.8, 0.6) :
Centrer et réduire
N’aurions-nous pas oublié quelque chose ?
Observez ces 2 échantillons, représentant tous deux les mêmes pommes :
Échantillon 1 :
poids (g)
diamètre (mm)
100
70
95
65
Échantillon 2 :
poids (g)
diamètre (cm)
100
7
95
6,5
Ces deux échantillons sont identiques, sauf que l’un exprime le diamètre des pommes en millimètres et l’autre en centimètres.
Que ce soit sur le premier échantillon ou sur le second, l’inertie pour la variable poids est la même (la variance empirique est de 6,25). Cependant, l’inertie pour la variable diamètre est bien plus grande dans le premier cas que dans le second (la variance empirique est de 6,25 dans le premier cas et 0,0625 dans le second).
Dans le premier cas, quand on va chercher le premier axe principal d’inertie, les variables poids et diamètre influenceront de manière égale le calcul de l’axe (elles ont toutes deux une variance de 6,25). Mais dans le second cas, la variable poids « pèsera beaucoup plus lourd » que la variable diamètre dans le calcul, car 6,25 est bien plus grand que 0,00625 ! C’est problématique, car finalement, le premier et le second cas représentent exactement les mêmes pommes !
Ce problème est très classique, car il est très fréquent que les variables d’un échantillon ne soient pas exprimées dans la même unité (simplement parce qu’elles ne représentent pas la même chose) ! Mais on peut ruser pour comparer des variables qui représentent des quantités différentes : faire en sorte que leurs moyennes soient toutes égales et que leurs variances le soient aussi.
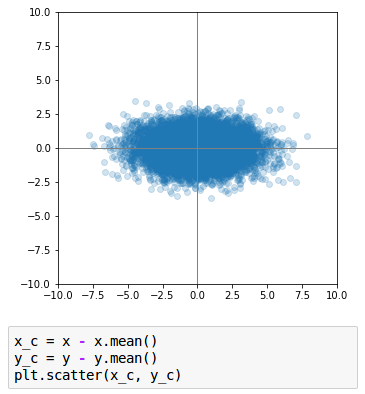
La première opération s’appelle le centrage. Pour effectuer un centrage sur des observations, il faut soustraire à toutes ces observations leur moyenne.
Le fait de centrer les données ne change en rien la forme du nuage de points : ce n’est donc pas dérangeant pour ce que nous souhaitons étudier ici. Centrer les données ne fait que déplacer (par une translation) le nuage de points de telle manière que son centre de gravité coïncide avec l’origine du repère.
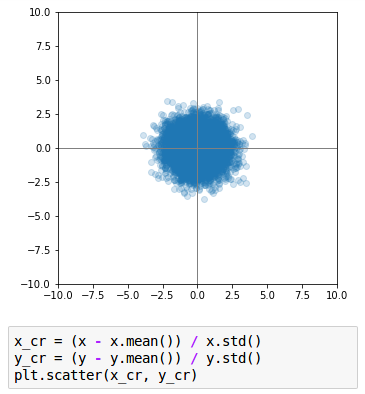
La seconde opération s’appelle la réduction. Après avoir centré les données, si on les divise par leur écart-type (l’écart-type est la racine carrée de la variance), alors on obtient des valeurs dont la variance vaut 1.
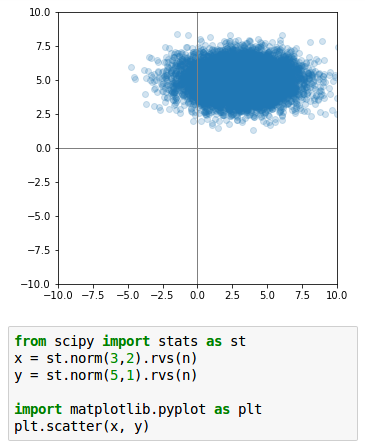
Voici une petite illustration : ces points sont disposés selon une forme elliptique. Une ellipse est un « cercle aplati ». Ici, il est aplati selon l’axe horizontal, ce qui signifie que la variance de la variable représentée en abscisse est plus grande que celle de la variable représentée en ordonnée. En effet, elle est de 2 en abscisse et de 1 en ordonnée :
Après centrage des données, le centre de l’ellipse a pour coordonnées :
Quand on réduit, l’ellipse devient alors un cercle, car la variable en abscisse a maintenant la même importance que celle en ordonnée : il n’y a plus d’aplatissement !
Voici donc la formule du centrage-réduction, où l'on centre et réduit pour obtenir :
( est la moyenne de , et son écart-type)
Appliquons ce calcul au diamètre de nos pommes. Si le numérateur de cette fraction est exprimé en centimètres, alors le dénominateur l’est également. Si l'on veut maintenant convertir en millimètres, on est obligé de multiplier le numérateur par 10, et le dénominateur par 10. Finalement, ces deux 10 s’annulent !
En pratique
Grace à pandas , numpy et scikit-learn , on peut effectuer ces opérations très simplement.
Commençons par importer nos librairies :
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
Définissons nos données :
# Notre matrice de base :
X = [[12, 30, 80, -100],
[-1000, 12, -23, 10],
[14, 1000, 0, 0]]
# Version numpy :
X = np.asarray(X)
# Version pandas :
X = pd.DataFrame(X)Avec pandas , on peut calculer la moyenne et l'écart-type de chaque dimension :
# On applique la methode .describe() pour avoir la moyenne et la .std(), et la méthode .round(2) pour arrondir à 2 décimales après la virgule :
X.describe()On peut ensuite « scaler » nos données :
# On instancie notre scaler :
scaler = StandardScaler()
# On le fit :
scaler.fit(X)
# On l'entraine :
X_scaled = scaler.transform(X)
# On peut faire les 2 opérations en une ligne :
X_scaled = scaler.fit_transform(X)
# On le transforme en DataFrame :
X_scaled = pd.DataFrame(X_scaled)
# On peut appliquer la méthode .describe() et .round()
X_scaled.describe().round(2)Vous pouvez confirmer que la moyenne est à 0 et l'écart-type est à 1.
En résumé
Nous avons 2 objectifs principaux lors d'une ACP : étudier la variabilité des individus et le lien entre les variables.
On voudra, entre autres choses, créer des dimensions synthétiques calculées à partir des dimensions initiales.
On souhaite réduire le nombre de dimensions, mais en perdant le moins d'information possible.
Ce travail consiste en fait à maximiser la variance de nos données, au travers de la création de nos nouvelles dimensions.
Pour ce faire, il est important de ramener les données dans des échelles de grandeur similaires, où la moyenne de chaque dimension est à 0, et l'écart-type est de 1.
On parle de centrer-réduire nos données.
Pour en savoir plus, suivez-moi au prochain chapitre !
