Réalisez les machines à vaste marge (SVM) pour la classification
L'objectif du cours est de :
comprendre les séparateurs à vaste marge (support vector machine),
mettre en œuvre cette méthode pour la classification binaire et multi-classe,
maîtriser l'utilisation de l'astuce du noyau pour adapter les SVM à des problèmes non-linéaires.
Nous allons étudier les SVM (support vector machine ou séparateur à vaste marge) pour la classification. Nativement, les SVM cherchent à estimer une fonction de score qui maximise la séparation entre les classes, c'est-à-dire la marge. Les SVM se prêtent aussi à une généralisation du modèle de classification à des problèmes non-linéaires en utilisant le formalisme des noyaux. Pour rentrer dans le sujet, commençons par la notion de marge.
Comprenez la notion de marge
Démarrons par un problème de classification binaire, dont l'objectif est précisé ci-dessous.
Prenons un problème de classification comme sur la figure 1.
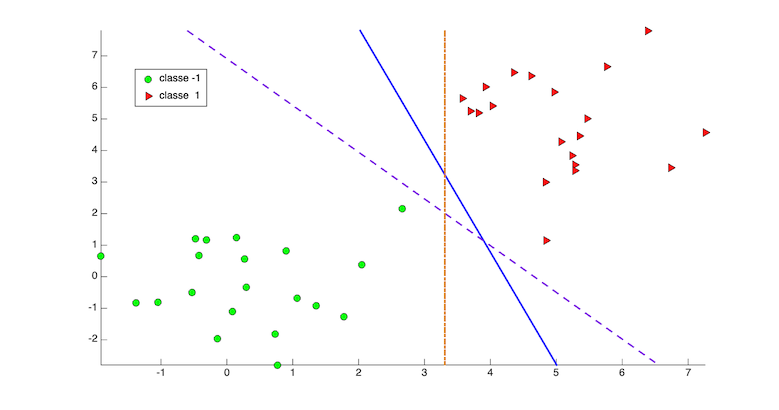
On peut trouver plusieurs hyper-plans de séparation parfaite des classes. Laquelle choisir ? Il faut privilégier la solution qui maximise la marge entre les points des deux classes.
Comment définir la marge ?
Quelques notions de géométrie permettent de montrer que la distance du point à l'hyper-plan d'équation (la frontière de séparation) est . Si nous définissons notre fonction de classification telle que
, alors la . La figure 2 montre cette marge.
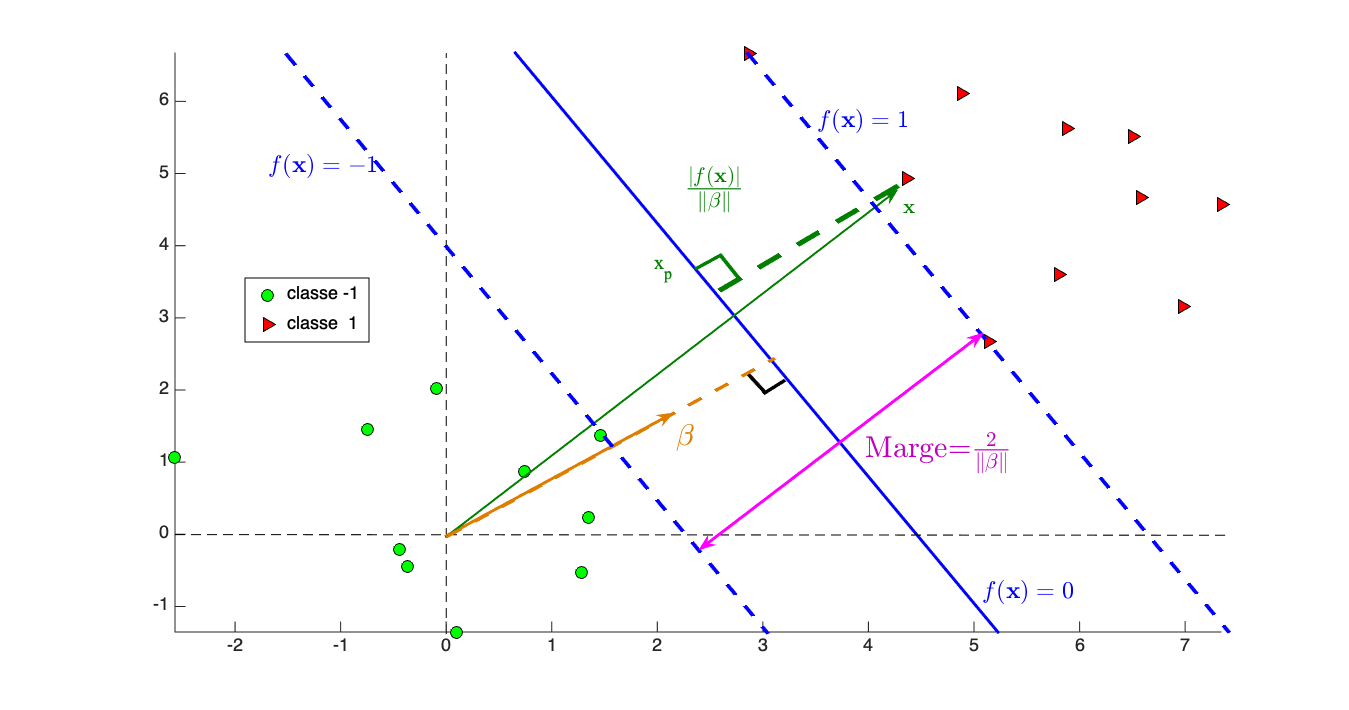
Maximisez la marge
Pour trouver notre fonction de classification, il faut :
maximiser la marge ,
s'assurer que tous les points sont bien classés, c'est-à-dire compte tenu de la définition de l'équation (1).
Gérez les erreurs de classification
L'exemple de la figure 2 est un cas idéal. En pratique, tous les points ne peuvent pas être classés correctement. Il faut alors relâcher les contraintes et autoriser avec le terme d'erreur .
Ces termes d'erreurs (voir la figure 3) doivent être intégrés dans la formulation du problème SVM en trouvant un compromis entre la maximisation de la marge et le contrôle des erreurs.
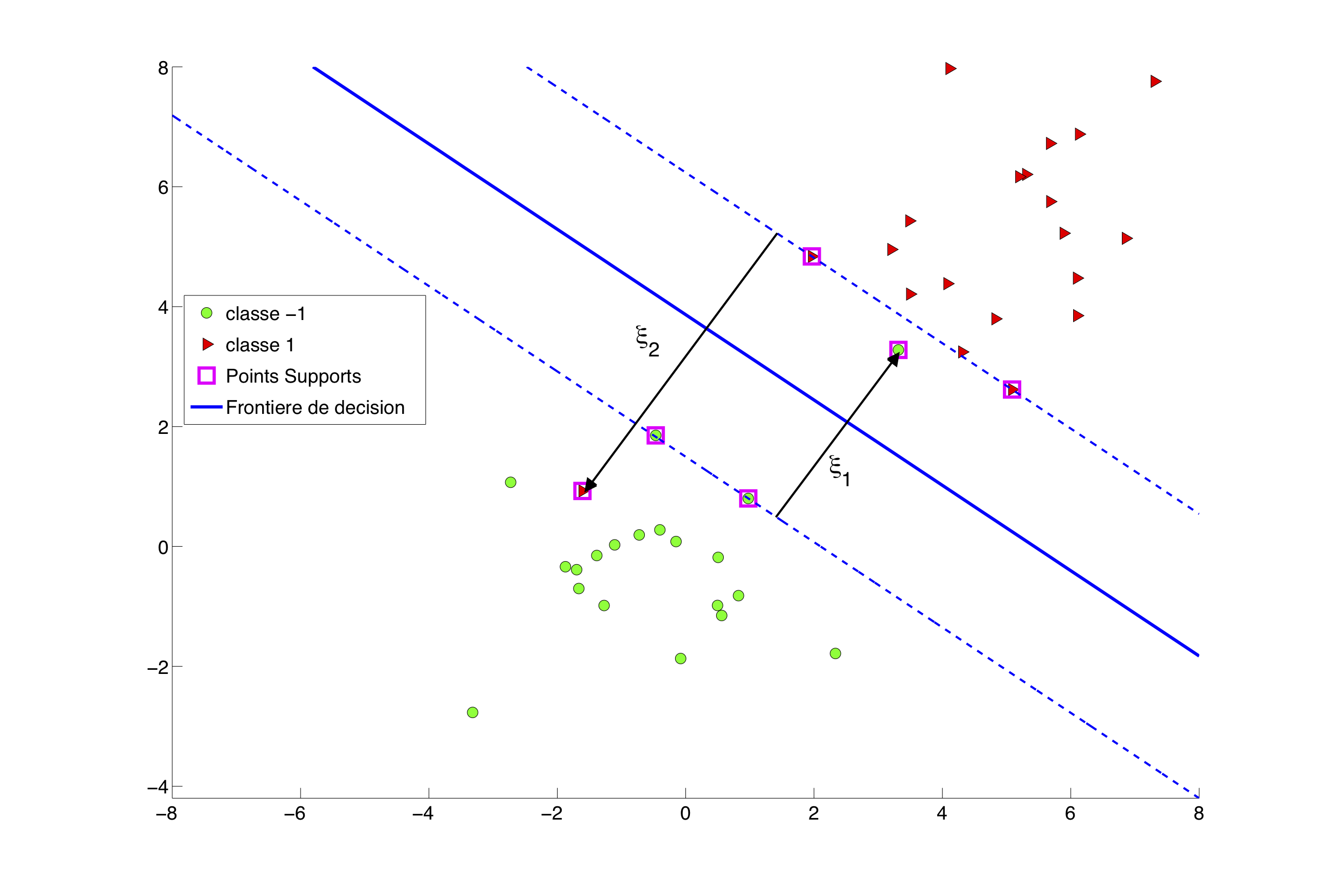
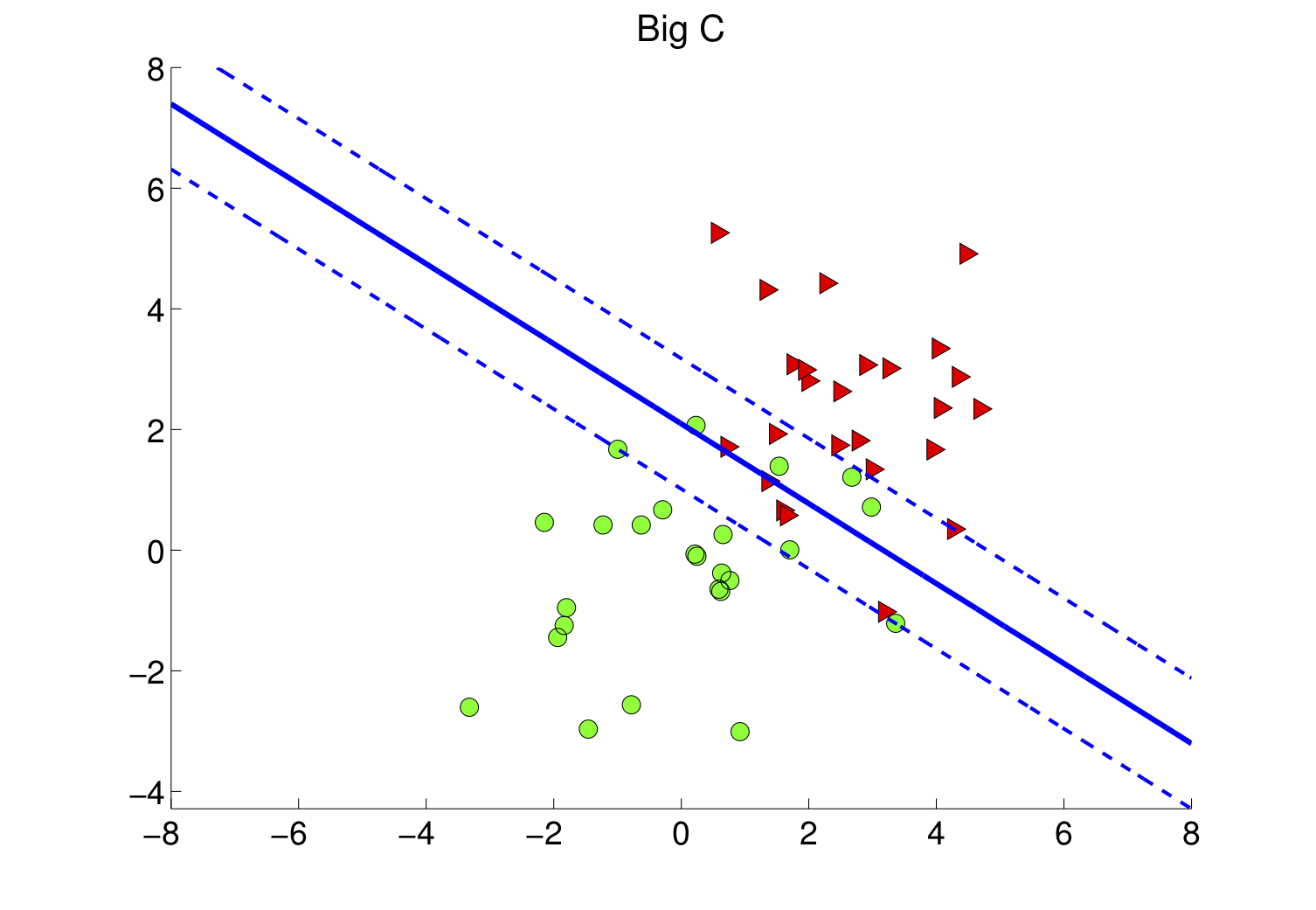
Le choix de influence la taille de la marge et les erreurs de classification comme sur les figures 4-a et 4-b.
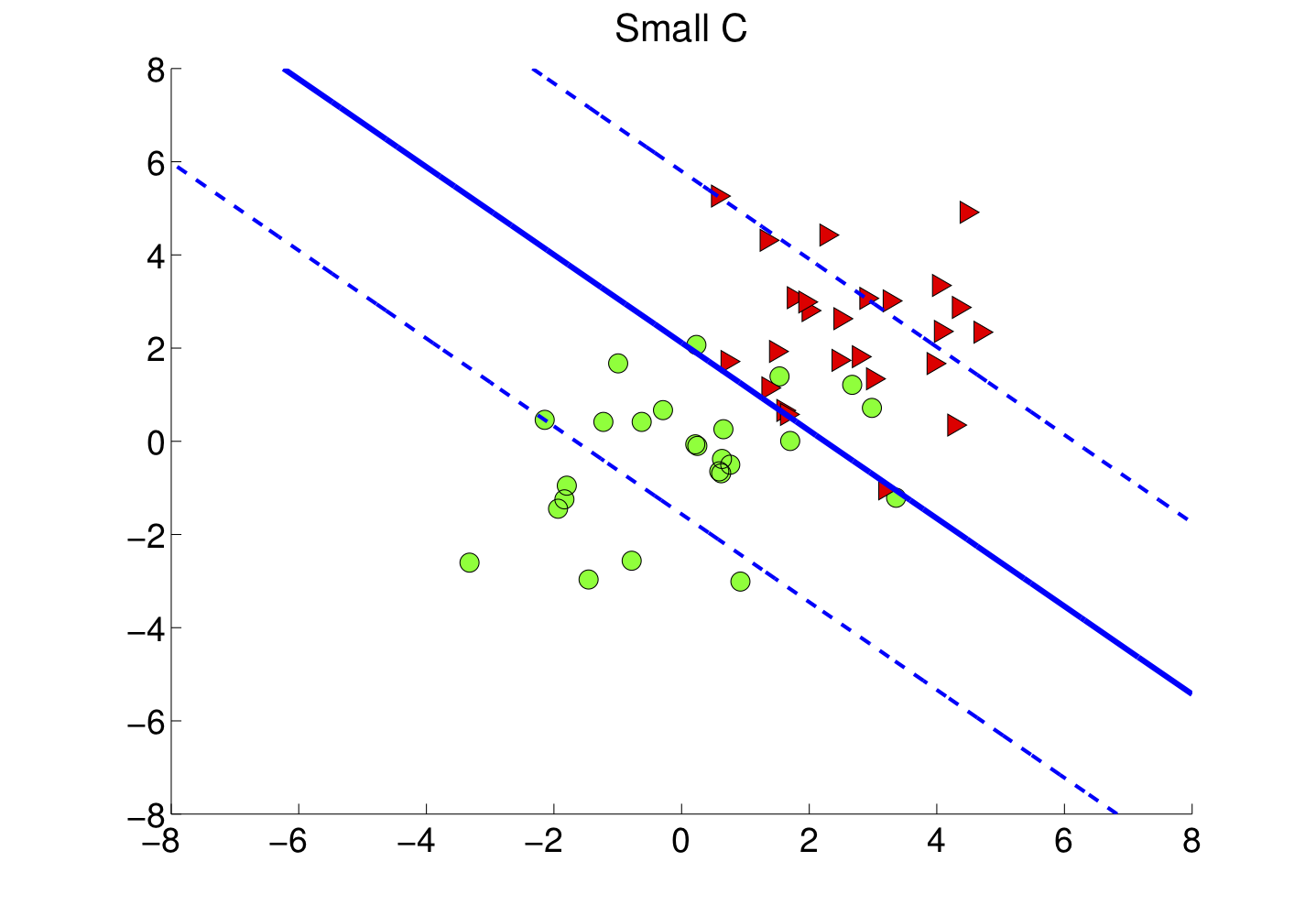
Comprenez la résolution du problème SVM
Le problème (2) est un problème d'optimisation avec contraintes inégalités. Pour le résoudre, l'idée est de se débarrasser des contraintes en le transformant en un problème sans contraintes. Pour cela, à chaque inégalité on associe un paramètre positif dit de Lagrange et on définit la fonction lagrangienne comme
avec et , les paramètres de Lagrange (inconnus) associés respectivement aux inégalités (2a) et (2b). Le problème résultant consiste en
c'est-à-dire à minimiser le pire cas où les contraintes ne seraient pas satisfaites, les paramètres de Lagrange agissant comme des sortes de pénalités si ces contraintes ne sont pas respectées. Typiquement, si la contrainte (2a) correspondante est strictement vérifiée, c'est-à-dire ; est différent de 0 dans le cas contraire.
Comme notre problème initial (2) est convexe avec des contraintes affines, la théorie de l'optimisation nous dit que
Du coup, les conditions d'optimalité du problème de minimisation de par rapport à , et donnent respectivement :
Il nous suffit donc de connaitre les pour obtenir .
Si nous remplaçons les conditions d'optimalité dans et en utilisant la remarque ci-dessus, nous pouvons éliminer , et de dont l'expression dépendra uniquement des . Ceci conduit au problème d'optimisation :
C'est quoi les points supports ?
Après résolution du problème dual, on peut montrer que les coefficients peuvent être classés en trois groupes :
Les points qui sont bien classés et hors de la marge auront leur .
Les points qui sont mal classés ou à l'intérieur de la marge sont caractérisés par .
Les points se trouvant sur la marge auront .
Une conséquence directe est que dans l'expression (3a), le vecteur n'est déterminé que par quelques points, ceux pour lesquels les coefficients sont non nuls : ce sont les points supports de la solution (voir la figure 3).
Assemblons les pièces du puzzle
Pour apprendre un modèle SVM à partir de données d'apprentissage, il nous faut :
choisir le paramètre ,
résoudre le problème dual pour avoir ; en déduire par la formule (2a) et .
Notre fonction de classification est
où représente l'ensemble des points supports.
La classe du point est prédite par .
Comment choisir C ?
Le paramètre de régularisation doit être déterminé par une procédure de sélection de modèle, par exemple par validation croisée (voir le chapitre "Bien apprendre, c'est généraliser : comprenez le principe de généralisation").
Apprenez une fonction de classification non-linéaire
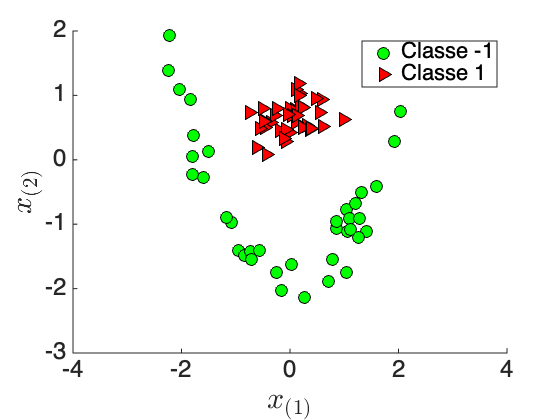
Que se passe-t-il si nous devons classifier les données de la figure 5-a ?
Il est évident que nous ne pouvons pas trouver un modèle SVM linéaire capable de classer correctement ces points. Pourtant, nous voyons qu'une fonction de classification quadratique (une parabole) peut parfaitement séparer les deux classes.
Pour cela, réalisons la projection des points en dimension 3 ( figure 5-b) par la fonction non-linéaire :
avec la jème variable du vecteur . 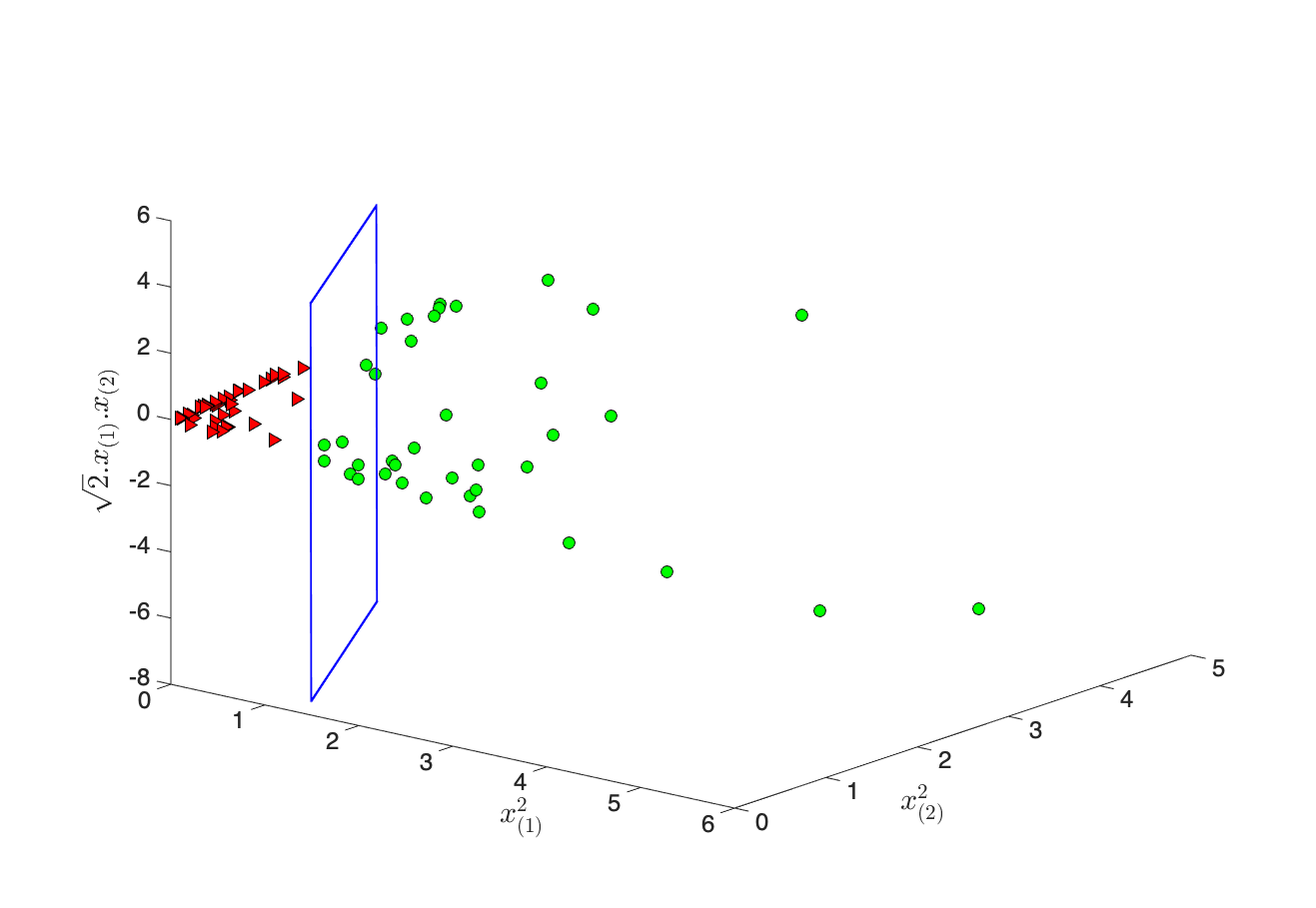 Figure 5-b : Projection non-linéaire des points. En bleu, la fonction de décision linéaire en 3D.
Figure 5-b : Projection non-linéaire des points. En bleu, la fonction de décision linéaire en 3D.
On peut apprendre avec les points un SVM linéaire (en bleu sur la figure 5-b) qui sépare correctement les deux classes. Dans l'espace d'origine , la frontière de décision que nous obtenons est une fonction non-linéaire (figure 5-c) des points .
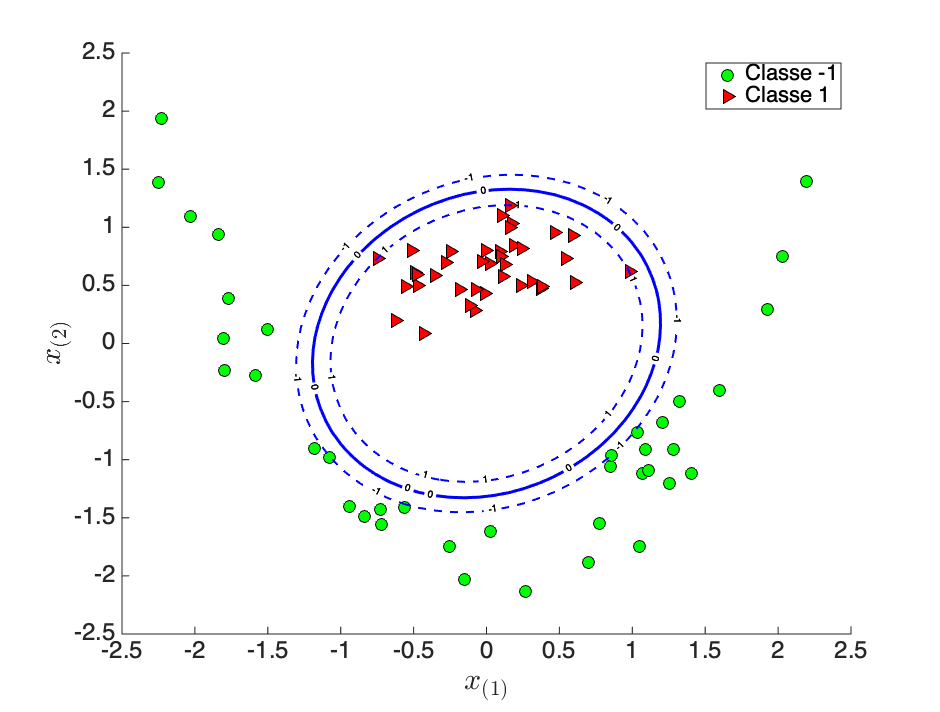
L'astuce du noyau
Qu'est-ce que cela change ?
Si nous adaptons le principe du SVM linéaire aux données projetées et apprenons un SVM, nous obtenons alors le modèle suivant :
L'élément clé est la fonction noyau , qui permet d'obtenir la fonction de séparation non-linéaire (sans connaitre explicitement parfois la fonction de mapping ).
Réglez les paramètres de la fonction noyau
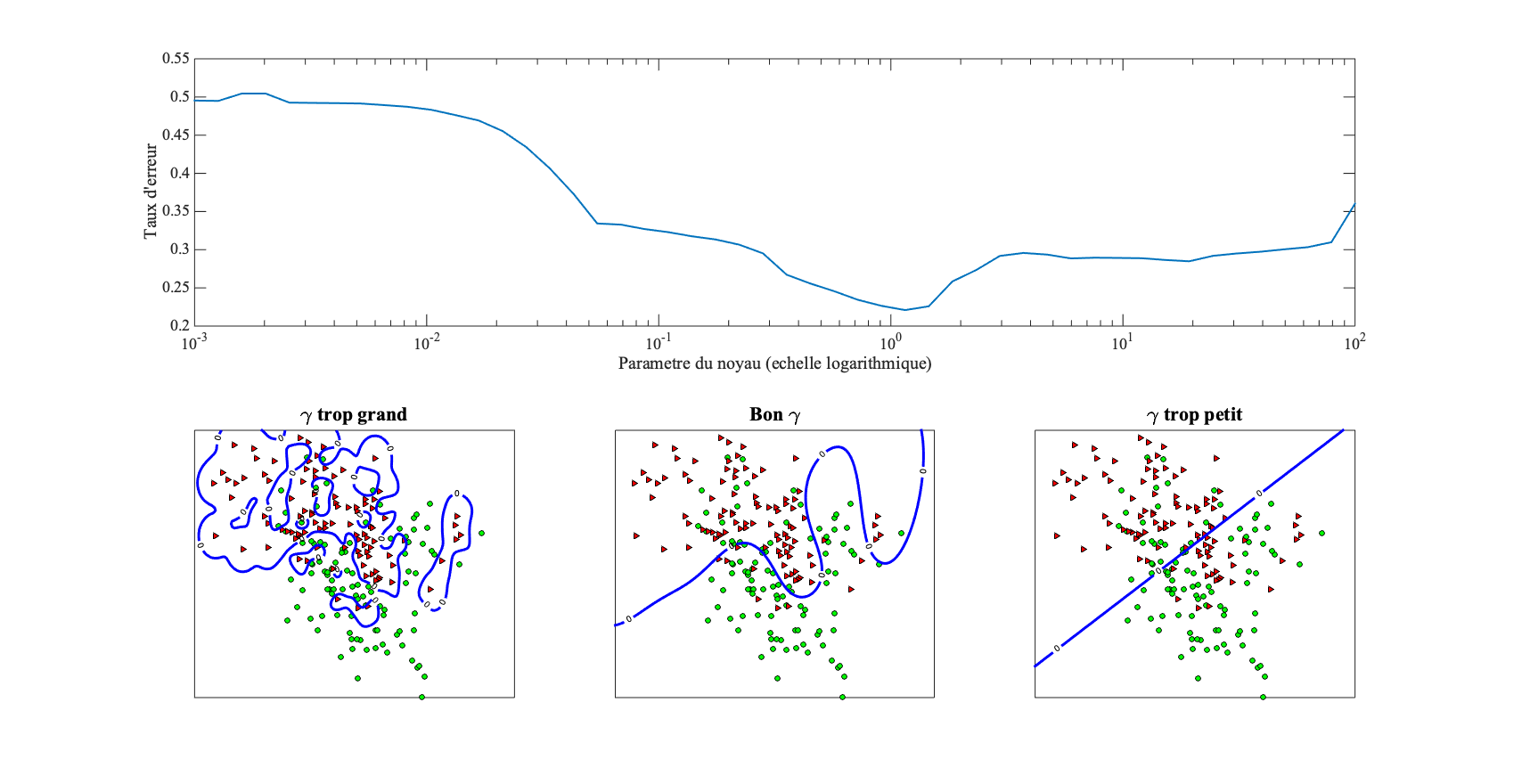
Le noyau dépend d'hyper-paramètres dont le réglage se fait par validation croisée comme pour . La figure 6 analyse l'influence du paramètre du noyau sur la qualité de la fonction de classification en termes de frontière de séparation et du taux d'erreur sur des données de validation.
Généralisez le SVM au cas multi-classe
Comme pour la régression logistique, nous supposons avec le nombre de classes. Que ce soit en linéaire ou non-linéaire, nous pouvons passer du cas binaire au multi-classe par l'une des stratégies usuelles suivantes :
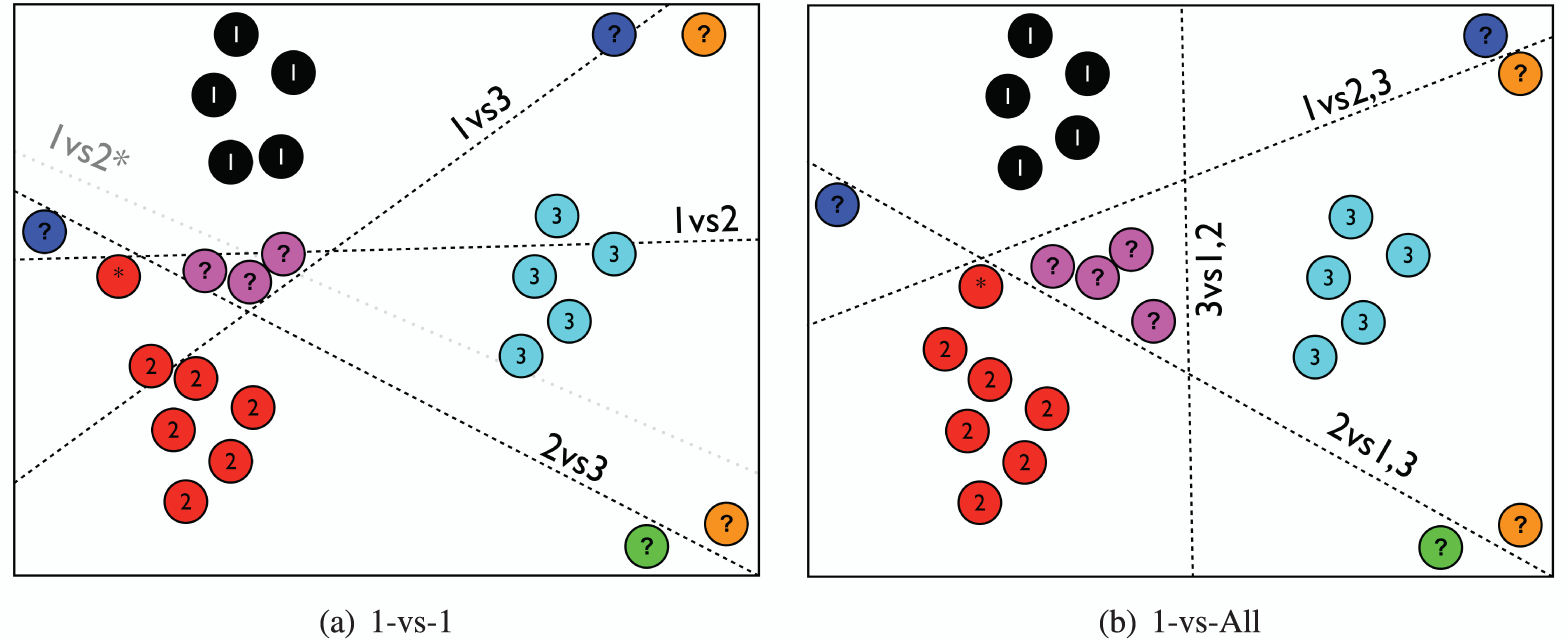
Un contre tous (one vs rest) : apprendre un SVM par classe (ladite classe contre les autres), calculer son score, et prédire la classe de score maximal (winner takes it all). Cela nécessite d'apprendre classifieurs.
Un contre un (one vs one) : apprendre autant de classifieurs SVM que de paires de classes, prédire avec chaque classifieur et prédire la classe plébiscitée. On requiert classifieurs.
La figure 7 montre les frontières de décision obtenues pour ces deux stratégies.
En résumé
Ce chapitre sur la méthode de classification SVM a permis :
de comprendre la notion de marge, qui sous-tend sa formulation,
d'appréhender le problème d'optimisation sous-jacent,
de se familiariser avec la notion de noyau, qui est un outil mathématique puissant pour étendre au cas non-linéaire une fonction de classification linéaire,
de savoir comment généraliser le concept aux problèmes de classification multi-classe.
Une question non abordée dans le chapitre est le choix de la fonction noyau. Notez qu'il existe de nombreux travaux scientifiques sur la construction de noyaux adaptés à un problème donné. De plus, l'utilisation de ces noyaux permet de réaliser la classification de données complexes comme les graphes, les histogrammes ou les séries temporelles.
Dans le prochain chapitre , nous allons analyser la complexité algorithmique des différentes méthodes d'apprentissage statistique étudiées et leur passage à l'échelle pour traiter de grandes quantités de données.
