Entraînez un réseau de neurones profond
Préambule
Pendant les années 90 et le début des années 2000, le développement de l'apprentissage statistique, partie de l'intelligence artificielle, s'est focalisé sur les algorithmes de machines à vecteurs supports et ceux d'agrégation de modèles.
Pendant une relative mise en veilleuse du développement de la recherche sur les réseaux de neurones, leur utilisation est restée présente de même qu'une recherche fondamentale, en attendant le développement de la puissance de calcul et celle des grandes bases de données, notamment d'images, avec l'avènement du big data.
Le renouveau de la recherche dans ce domaine est principalement dû à Geoffrey Hinton, Yoshua Bengio, et Yann le Cun qui a tenu à jour un célèbre site dédié à la reconnaissance des caractères manuscrits de la base MNIST. La liste des publications listées sur ce site témoigne de la lente progression de la qualité de reconnaissance, de 12 % avec un simple perceptron à 1 couche jusqu'à moins de 0,3 % en 2012, par l'introduction de couches de neurones spécifiques appelées convulational neural network (ConvNet).
Schématiquement, trois grandes familles de réseaux d'apprentissage profond sont développées avec des ambitions industrielles, en profitant du développement des cartes graphiques (GPU) pour paralléliser massivement les calculs au moment de l'apprentissage :
convolutional neural networks (ConvNet) pour l'analyse d'images ;
long-short term memory (LSTM) lorsqu'une dimension temporelle ou plus généralement des propriétés d'autocorrélation sont à prendre en compte pour le traitement du signal ou encore l'analyse du langage naturel ;
autoencoder decoder ou réseau diabolo en apprentissage non supervisé pour, par exemple, le débruitage d'images ou signaux, la détection d'anomalies.
Seul le premier point est développé pour illustrer les principaux enjeux.
Reconnaissance d'images
Cette couche de neurones (ConvNet) illustrée par la figure ci-dessous ou plutôt un empilement de ces couches associé à du max pooling, fait émerger des propriétés spécifiques d'invariance locale par translation.
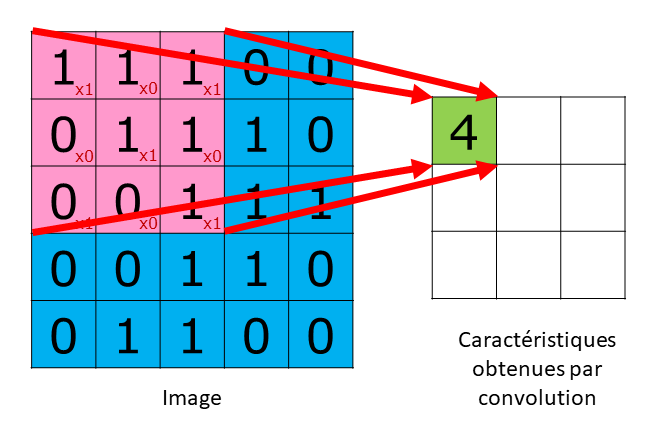
Cette couche applique une somme pondérée locale de chaque pixel au sein d'une fenêtre qui est translatée sur toute l'image. D'autres types de couche (pooling, subsampling) contribuent également à réduire la dimension initiale (nombre de pixels) de l'image.
Ces propriétés sont indispensables à l'objectif de reconnaissance de caractères et plus généralement d'images, qui peuvent être vues avec des positions ou sous des angles différents. C'est dans ce domaine que les résultats les plus spectaculaires ont été obtenus, tandis que l'appellation deep learning était avancée afin d'accompagner le succès grandissant et le battage médiatique associé.
Comme pour les données de reconnaissance de caractères, une progression largement empirique a conduit à l'introduction et au succès d'un réseau empilant des couches de neurones aux propriétés particulières. Cette progression est retracée dans le tableau ci-dessous :
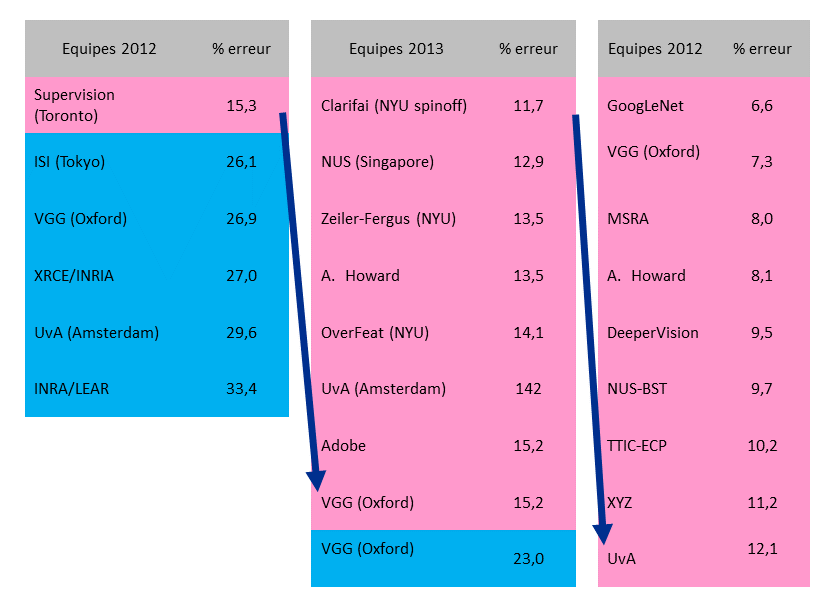
C'est en 2012 qu'une équipe utilise pour la première fois un réseau de neurones profond, contrairement à des traitements spécifiques et ad hoc de l'analyse d'images utilisée jusque là. L'amélioration était telle que toutes les équipes ont ensuite adopté cette technologie pour une succession d'améliorations empiriques. En 2016, une équipe propose un réseau à 152 couches et atteint un taux d'erreur de 3 %, mieux que les 5 % d'un expert humain.
Ce concours est depuis lors abandonné au profit de problèmes plus complexes de reconnaissance de scènes associant plusieurs objets ou thèmes, préalables indispensables à la conduite de véhicules autonomes.
Couches pour l'apprentissage profond
Construire un réseau d'apprentissage profond consiste à empiler des couches de neurones aux propriétés spécifiques dont des exemples sont résumés ci-dessous. Le choix du type, de l'ordre, de la complexité de chacune de ces couches, ainsi que de leur nombre, est complètement empirique, et l'aboutissement de très nombreuses expérimentations nécessitant des moyens de calculs et bases de données considérables :
fully-connected : couche classique de perceptron et dernière couche d'un réseau profond qui opère la discrimination finale entre, par exemple, des images à reconnaître, les couches précédentes construisant, extrayant des caractéristiques (features) de celles-ci ;
convolution : opère une convolution sur le signal d'entrée en associant une réduction de dimension (cf. ci-dessus : figure "Principe élémentaire d'une couche de convolution et application à une image" du paragraphe 2) ;
pooling : réduction de dimension en remplaçant un sous-ensemble des entrées (sous-image) par une valeur, généralement le max ;
normalisation : identique au précédent avec une opération de centrage et/ou de normalisation des valeurs ;
drop out : les paramètres estimés sont les possibilités de supprimer des neurones d'une couche afin de réduire la dimension ;
...
Transfert d'apprentissage
Sans bases de données très volumineuse et moyens de calcul substantiels, il est illusoire de vouloir apprendre un réseau profond impliquant l'estimation de millions de paramètres. Une mise en œuvre simple sur des données spécifiques consiste à opérer du transfert d'apprentissage :
identifier un réseau ou modèle existant appris sur des données similaires : pour les images, considérer par exemple les versions des réseaux inception de tensorFlow ou AlexNet de Caffe ;
supprimer la dernière couche du modèle dédiée à la classification ;
apprendre les poids de cette seule dernière couche sur les données spécifiques.
