Represent Variables in the Form of a Table
There is more to life than histograms!
It is also possible to present variables in the form of a table. It’s not as pretty, of course, but in some cases, this representation is better suited, or supplements, a graphic representation. We will look at four cases, corresponding to the four variable types.
Let's Start With Some Vocabulary
So that the two of us can communicate, you and I, we need to adopt a common language. So we are going to name the different objects we will be manipulating in this chapter.
Here we are working with the bank statement sample, which is made up of transactions. Note that will represent the number of banking transactions: this is our sample size.
Next, the variable we will be analyzing will be referred to as .
is not particularly concrete: it’s just a variable. For example, amount is a variable.
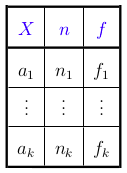
Our data set contains a number of different values for the amount variable: 1.43, 80, 2.20, etc. No more theory now - all practice! We’ve got real values in front of us. The number of values in our sample is . So we can express these values as ( ).
When referring to variables, it’s best to use a capital letter. However, when referring to observations of the variable, lower case letters are used. Here, ( ) is an observed realization of the random variable .
Discrete Quantitative and Qualitative Variables
If is qualitative (or even discrete quantitative), it can take a number of categories. For example, categ can take the categories “GROCERIES,” “RENT,” “TRANSPORTATION,” etc. We will refer to these categories as {}, where indicates the number of categories.
Continuous Quantitative Variables
To present continuous quantitative variables, we will group the values of variable X into bins, which will be k in number. These bins will be expressed as follows:
Representing Variables in the Form of a Table
Qualitative Variables
For qualitative variables, simply count the number of values for each category. This number is referred to as the occurrence of the category.
So, for a category (where is between and of course!), the occurrence is expressed as . If we add up the occurrences of all of the categories, we get : the sample size.
If we divide the number of occurrences by , we get the frequency, which is a number between 0 and 1. As I’m sure you’ve guessed, if we add together the frequencies of all of the categories, we get 1!
Here is how a qualitative variable is normally presented formally, using the example of the categ variable:
categ |
|
|
OTHER | 212 | 0.688312 |
GROCERIES | 39 | 0.126623 |
TRANSPORTATION | 21 | 0.068182 |
RESTAURANT | 16 | 0.051948 |
PHONE BILL | 7 | 0.022727 |
BANK FEE | 7 | 0.022727 |
RENT | 6 | 0.019481 |
Quantitative Variables
Discrete Variables
For discrete quantitative variables, we can take the preceding table and add a column to it providing the cumulative frequency. The cumulative frequency of a category ai is simply the sum of the frequencies of all of the categories that are less than or equal to . It is expressed as . Here is an example using the quart_month variable:

quart_month |
|
|
|
1 | 86 | 0.279221 | 0.279221 |
2 | 76 | 0.246753 | 0.525974 |
3 | 75 | 0.243506 | 0.769481 |
4 | 71 | 0.230519 | 1.000000 |
Continuous Variables
For continuous variables, simply replace {} with bins, as we saw earlier. Here’s what that would look like, using the amount variable:

amount |
|
|
|
[...] | [...] | [...] | [...] |
[-120.0, -90.0[ | 2 | 0.006494 | 0.048701 |
[-90.0, -60.0[ | 11 | 0.035714 | 0.084416 |
[-60.0, -30.0[ | 28 | 0.090909 | 0.175325 |
[-30.0, 0.0[ | 237 | 0.769481 | 0.944805 |
[0.0, 30.0[ | 3 | 0.009740 | 0.954545 |
[...] | [...] | [...] | [...] |
Now for the code...
In Python, the code is pretty simple. All you need (almost) is one line of code per column. Here is the code that generated the summary table for the quart_month variable.
occurrences = data["quart_month"].value_counts()
categories = occurrences.index # the occurrences index contains the categories
tab = pd.DataFrame(categories, columns = ["quart_month"]) # creation of table based on categories
tab["n"] = occurrences.values
tab["f"] = tab["n"] / len(data) # len(data) returns the sample sizeTo calculate the occurrence, we use value_counts() for the variable we want to look at. This method returns a Series object whose values are occurrences, and whose index contains the categories (lines 1 and 2).
Based on our categories, we create the tab table (line 4), to which we add an occurrence column (line 5) and then a frequencies column (line 6).
To calculate cumulative frequencies, you need only 2 lines more. One line sorts the values, the other calculates the sum of the cumulative frequencies:
tab = tab.sort_values("quart_month") # sorts values of variable X (increasing)
tab["F"] = tab["f"].cumsum() # cumsum calculates the cumulative sum
