Choisissez entre une BDD relationnelle ou NoSQL
Appréhendez la structure de vos données
Vous avez déjà utilisé un tableur comme Excel, Google Sheet, ou LibreOffice Calc ? Alors bravo ! Vous savez manipuler des données dites structurées.
Sur un tableur, il y a des lignes et des colonnes.
En général, on y indique sur chaque ligne chacune des entités que l’on enregistre, et en colonne les caractéristiques de chacune de ces entités.
C’est le cas dans notre jeu de données :
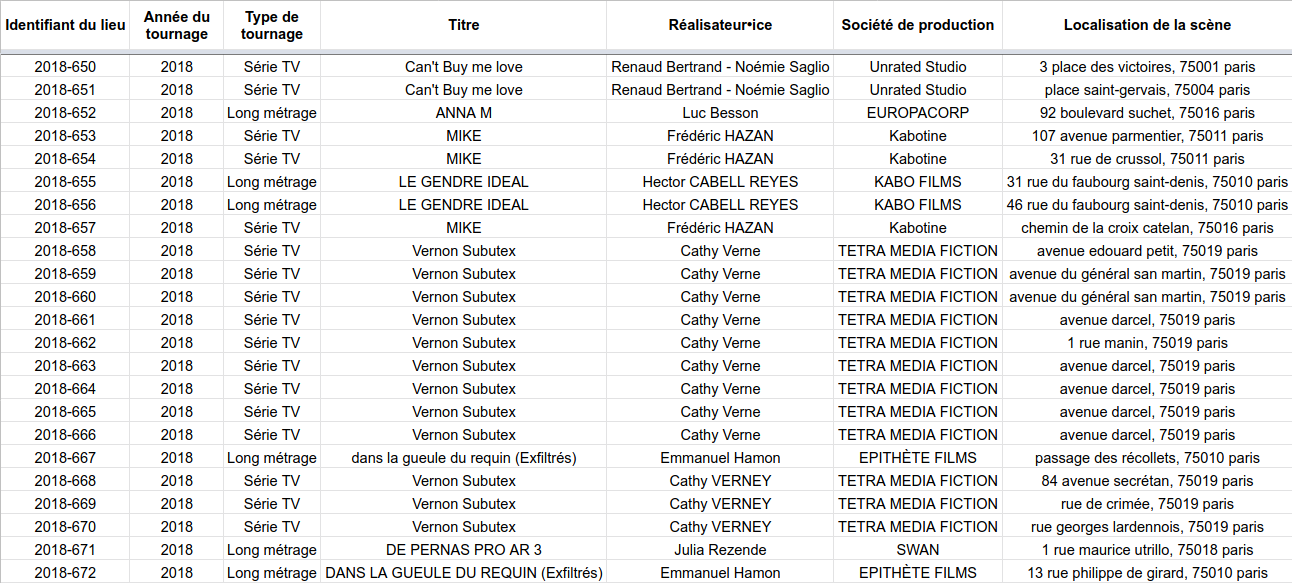
Ce que l’on représente, ce sont des lieux de tournage. On met donc :
Pour chaque ligne, les lieux de tournage.
Et, en colonnes, on indique les caractéristiques de ces lieux de tournage : date, adresse, film, réalisateur, etc.
Ici, c’est clair, net et précis : on sait à l’avance quelles caractéristiques on a pour chaque lieu de tournage (date, adresse, etc.), et on peut donc facilement déterminer le nom des colonnes. En plus, tous les lieux de tournage ont une « structure » similaire car on peut tous les représenter grâce à ces mêmes caractéristiques/colonnes : vous ne trouverez pas un lieu de tournage sans la caractéristique « adresse », par exemple. Chaque lieu a forcément une adresse.
Mais parfois, c’est plus complexe.
Avez-vous déjà entendu parler du big data ?
Il s’agit d’un phénomène très actuel où une importante quantité de données est produite au quotidien.
En effet, on utilise de plus en plus d’appareils électroniques tels que nos Smartphones, tablettes, etc. Face à ce volume important de données, il a fallu s’adapter et trouver de nouvelles technologies pour stocker ces données, mais aussi pour savoir les représenter, les organiser, et surtout les analyser !
On parle souvent des trois V qui caractérisent le big data :
Volume ;
Vélocité ;
Variété.
Arrêtons-nous sur ce troisième point : la variété. Les formes de données générées par le Web sont de plus en plus diverses : images, vidéos, textes, opinions sur les réseaux sociaux, e-mails, etc. Ces données sont difficiles à représenter sous forme de tableau : on dit donc qu’elles sont peu structurées.
Représentez vos données en fonction de leur structure
Imaginons que vous souhaitiez enregistrer des informations sur des personnes (dans le strict respect du RGPD, bien entendu), de manière structurée. Vous allez donc faire un tableau avec une ligne par personne et une colonne par caractéristique.
En effet, on peut caractériser une personne par son état civil (nom, prénom, date de naissance, etc.), mais aussi par ses comportements sur Internet (quelles pages va-t-elle visiter?), par ses comportements d’achat (quels produits achète-t-elle?), par les personnes avec qui elle interagit (son cercle amical, professionnel, associatif), et il y a encore beaucoup d’autres possibilités !
Beaucoup de caractéristiques possibles, c’est beaucoup de colonnes dans notre tableau.
De plus, vous obtiendrez rarement toutes les caractéristiques d’une personnes d’un coup ; loin de là !
Cela veut dire que :
Pour une ligne donnée, seule une toute petite proportion des colonnes seront remplies ;
Et pour la ligne suivante, d’autres colonnes seront remplies, mais pas forcément les mêmes !
Vous aurez donc un tableau très peu rempli, avec énormément de colonnes. Avouez que sur Excel, ce n’est pas pratique d’avoir une feuille énorme avec très peu de données éparpillées un peu partout !

La variété des données est donc peu compatible avec une représentation en tableau.
Mais alors, comment représente-t-on des données non structurées ?
Il y a une infinité de représentations possibles !
Si on reprend l’exemple des données relatives à une personne, on peut le faire sous une représentation de type Clé-Valeur.
C’est-à-dire que chaque clé est l’intitulé d’une caractéristique (« nom », « prénom », etc) et à chaque clé est associée sa valeur (« Dupont », « Johanna », etc.).
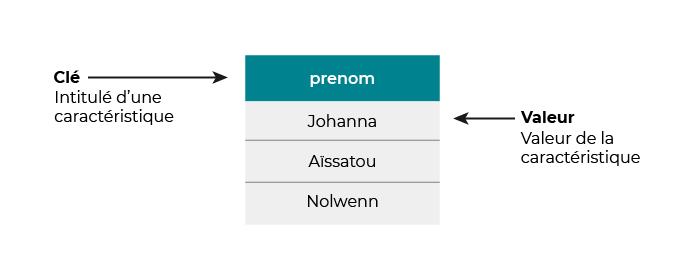
En voici un exemple :
[
{
"identifiant_personne":1,
"nom":"Dupont",
"prenom":"Johanna",
"pages_favorites":
[
"twitter.com",
"mail.google.com",
"lemonde.fr"
],
"achats":{
"culture":{
"livres":
[
{
"ISBN":"9782070612758",
"titre":"Le petit prince",
"auteur_ice":"Antoine de Saint-Exupéry",
"date_achat":"18/12/2029"
},
{
"ISBN":"9782355221224",
"titre":"Sorcières",
"auteur_ice":"Mona Chollet",
"date_achat":"23/01/2029"
}
]
}
}
},
{
"identifiant_personne":2,
"nom":"Nguyen",
"prenom":"Augustin",
"profil_facebook":"www.facebook.com/AugustinoLeRigolo",
"profil_twitter":"twitter.com/AugustinoLeRigolo",
"amis_facebook":
[
"www.facebook.com/RadiaLaRadieuse",
"www.facebook.com/RatonLeLaveurDeVitres",
"www.facebook.com/YvanLeHareng",
"www.facebook.com/EdgarLeCougar"
]
}
]Et pour les données structurées, quel format de fichier faut-il ?
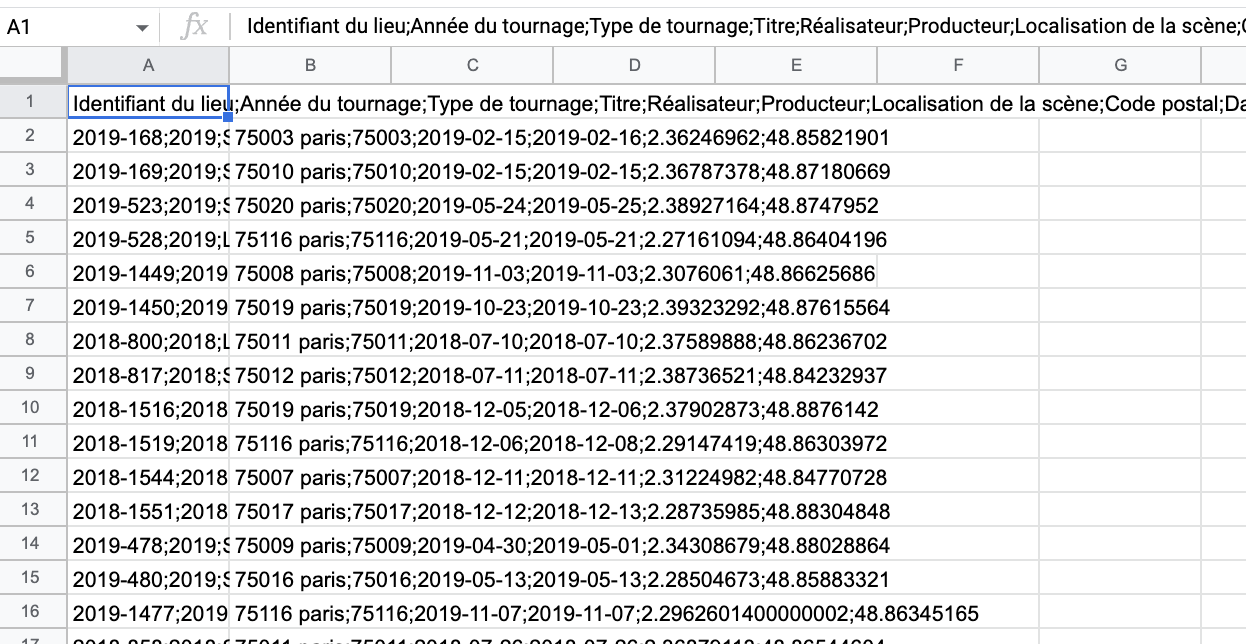
Le plus souvent, on utilise le format CSV (« Comma-separated values »), conçu pour représenter un tableau. La première ligne du fichier donne le nom des colonnes, et les suivantes présentent toutes les données, séparées par des virgules, des point-virgules ou des tabulations :
Identifiant du lieu;Année du tournage;Type de tournage;Titre;Réalisateur;Producteur;
2019-168;2019;Série TV;Fleabag;Jeanne Herry;Banijay Studios France;rue payenne, 7500
2019-169;2019;Série TV;Fleabag;Jeanne Herry;Banijay Studios France;rue bichat, 75010
2019-523;2019;Série TV;Munch saison 3;Laurent TUEL;JLAPRODUCTIONS;7 rue du jourdain,
2019-528;2019;Long métrage;Madame Claude;Sylvie VERHEYDE;Les Compagnons du Cinéma;ru
2019-1449;2019;Long métrage;PAR UN DEMI CLAIR MATIN;Bruno Dumont;3B PRODUCTIONS;plac
2019-1450;2019;Série Web;Tu Préfèreres;Lise Akoka et Romane Gueret;Superstructure;21
2018-800;2018;Long métrage;MERVEILLES A MONTFERMEIL;Jeanne Balibar;FILM(S);rue pasteComme vous le voyez ci-dessus, le séparateur utilisé n'est pas une virgule, mais un point virgule. Cela pourrait également être un caractère comme '\t' qui est le caractère qui marque une tabulation.
Notez donc qu'il y a deux façons d'ouvrir un fichier CSV :
avec un éditeur de texte de type "bloc notes" ou un IDE comme VS Code: vous aurez le texte du fichier CSV en affichage ;
avec un logiciel comme Google Sheet ou Excel : vous aurez les données formatées sous forme de tableur.
Le format CSV n'est pas très connu du grand public, plus habitué aux fichiers Excel classiques, ayant une extension ".xls" par exemple. Mais dans le Web, en Data Science et dans de nombreux domaines, techniques, le format CSV est très utilisé.
Dernier point concernant les fichiers CSV : L'encoding.
Il peut arriver qu'à la lecture d'un fichier CSV ou meme d'un fichier Excel "classique" vous ayez des caractères étranges :
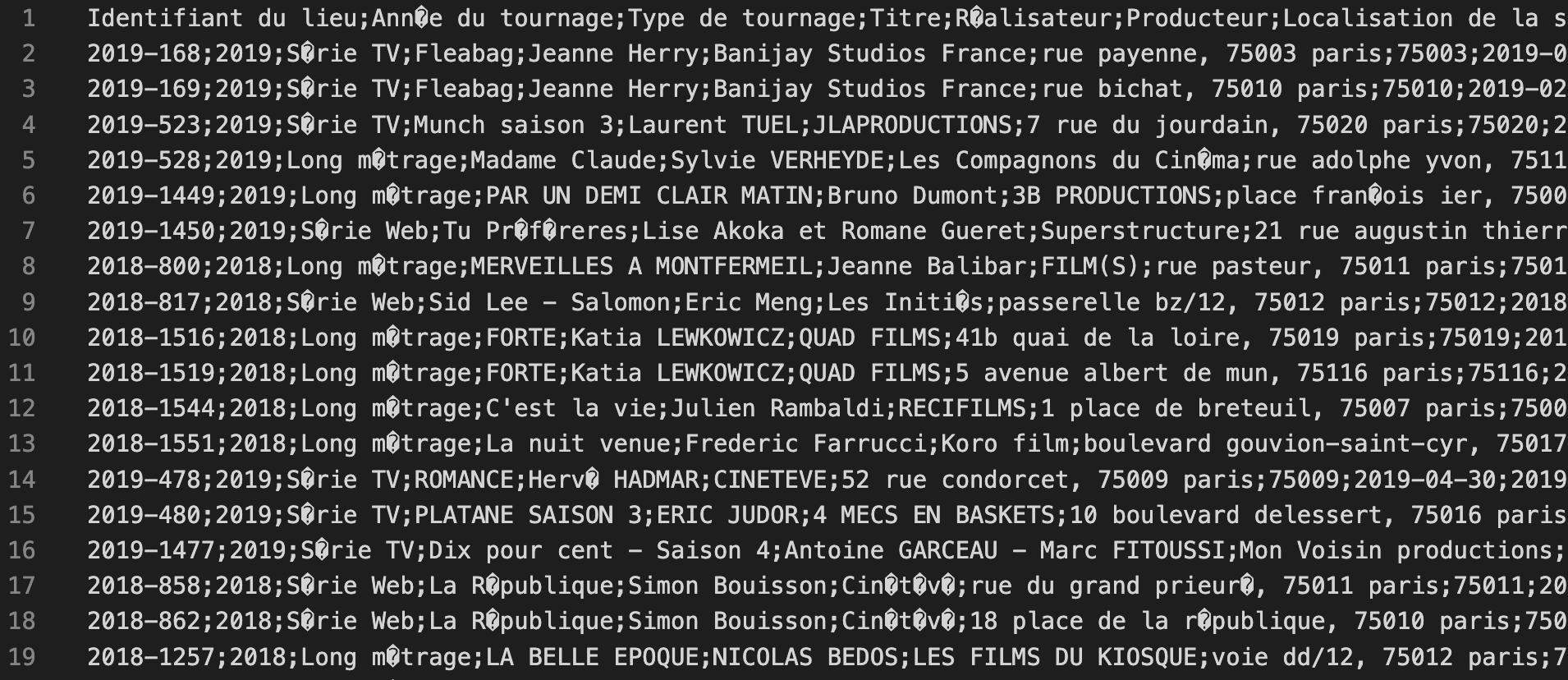
Sachez que cela est généralement dû à un problème d'encoding. L'encoding, c'est la norme utilisée pour transformer les différents caractères que nous utilisons dans une version "informatique".
C'est un sujet assez complexe que nous n'aborderons pas ici en détail, mais sachez que les 3 grandes normes d'encoding sont :
ASCII : l'enconding le plus basique qui ne permet pas d'écrie des accents
Latin-1 : un encoding très utilisé, notamment via Windows et Excel
UTF-8 : un enconding très large et très permissif, très utilisé dans le web et en data
Choisissez votre SGBD en fonction de la structure de vos données
Connaître la structure de vos données vous permet de bien choisir votre SGBD. Si votre SGBD est mal adapté à vos données, alors il sera plus complexe de lui formuler des requêtes pour accéder aux données, et le temps de réponse sera probablement plus long.
Le plus pratique pour stocker des données structurées, c’est d’utiliser une base de données relationnelle.
Pourquoi « relationnelle » ?
Ce terme vient du « modèle relationnel », qui est un moyen de représenter les relations dans un ensemble d’informations. Mais nous verrons cela plus tard, c’est bien d’être curieuse/curieux, mais encore un peu de patience ! ;)
Les SGBD qui gèrent les bases de données relationnelles sont appelés SGBDR. Pour éviter d’avoir un langage différent pour chacun de ces SGBDR, on a créé le langage SQL. Il est commun à la quasi-totalité des SGBDR, et il permet d’insérer, de lire, d’actualiser ou de supprimer des données dans une base relationnelle.
Les plus célèbres SGBDR sont :
PostgreSQL ;
MySQL ;
Oracle ;
SQLite.
Et pour les données non structurées ?
C’est plus complexe, car les données non structurées ont des formes extrêmement variées. Tout dépend de ce que vous voulez y stocker. Les SGBD qui s’écartent du modèle relationnel sont appelés « NoSQL » (c’est-à-dire « Not Only SQL », soit en français « pas uniquement SQL »).
Parmi les SGBD NoSQL, on trouve :
Elasticsearch : très performant pour stocker du texte et y effectuer des recherches.
Neo4j : qui stocke des « graphes », c.-à-d. des données de type « réseaux » constitués d’éléments connectés entre eux : réseaux sociaux, routiers, informatiques, etc.
MongoDB : qui stocke des données au format Clé-Valeur, comme dans l’exemple que nous avons vu plus haut.
Pour nos données (celles des lieux de tournage), quel SGBD utiliser ?
Nous l’avons vu plus haut, nos données sont structurées : on connaît à l’avance comment caractériser chaque lieu de tournage, et ces caractéristiques sont en nombre limité.
On pourra donc utiliser n’importe lequel des systèmes de gestion de bases de données relationnelles cités ci-dessus.
Nous n’apprendrons pas à concevoir la structure de bases NoSQL ?
Non, car par définition, les bases NoSQL contiennent des données beaucoup moins structurées, et le peu de structure qu’elles contiennent se base sur des concepts des BDD relationnelles ;). Donc autant commencer par apprendre les BDD relationnelles, car vous aurez toujours besoin de connaître leur fonctionnement.
Encore aujourd’hui, les BDD relationnelles restent encore de loin les plus répandues et les plus adaptées au fonctionnement de base des logiciels et des applis mobiles ou web.
En résumé
Des données structurées sont des données qui se représentent facilement sous forme de tableau dans lequel il y a une ligne par objet, et où les colonnes représentent les caractéristiques de chaque objet.
Le format CSV peu connu du grand public est un format très utilisé en Web et en Data.
Les bases de données dites relationnelles sont adaptées à des données structurées.
Le langage commun à la quasi-totalité des systèmes de gestion de bases de données relationnelles (SGBDR) est le langage SQL.
Des données non structurées se représentent mal par des tableaux, et il faut donc trouver d’autres modes de représentation.
On utilise pour les données non structurées différentes représentations, souvent basées sur un système clé-valeur.
On utilise pour ce type de données, des bases dites "NoSQL".
C’est très bien : vous savez à présent déterminer que pour accueillir vos données structurées, il vous faut une base de données relationnelle. Maintenant, il va vous falloir structurer cette BDD avant que vous puissiez la remplir.
