Configurez votre projet Java
Dans le chapitre précédent, vous avez pu :
Installer la base de données MySQL.
Générer la structure minimale du projet, et l’importer dans votre IDE.
Ce chapitre vous permettra de connecter l’application Java à la base de données. Ce lien que nous allons créer entre les 2 est facilité par Spring Boot et Spring Data JPA.
L’une des caractéristiques de Spring Boot est de favoriser la configuration pour réduire la quantité de code à écrire. De ce fait, pour connecter la base de données avec Spring Boot, il vous suffira d’écrire de la configuration. Vous n’aurez pas de code à implémenter.
Configurez et testez votre projet
Lors de la génération de la structure minimale du projet, le répertoire /src/main/resources contient un fichier par défaut nommé applications.properties.
Ce fichier est considéré par Spring comme étant une source de propriétés. Cela signifie qu’au démarrage de l’application, ce fichier sera lu, et les informations présentes pourront être exploitées par le code de l’application.
En l’occurrence, la documentation de Spring nous apprend qu’en fournissant certaines propriétés, le framework exécutera le code nécessaire à la connexion de la base de données. Il s’agit concrètement d’ouvrir une connexion JDBC sécurisée vers la base de données.
Très bien, donc pas de code mais des propriétés. Lesquelles exactement ??
Sachez tout d’abord qu’il en existe de très nombreuses (si vous avez fait un tour sur le lien de la documentation, vous avez dû vous en rendre compte 
 ) ; donc je vais vous montrer le minimum nécessaire.
) ; donc je vais vous montrer le minimum nécessaire.
Retrouvez-moi dans le screencast ci-dessous :
Voici le fichier que nous avons obtenu lors du screencast :
spring.datasource.url=jdbc:mysql://localhost:3306/carlib?serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=root
spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5DialectReprenons une à une les propriétés que je vous ai présentées :
spring.datasource.url : Nous indiquons ici l’URL de connexion à la base de données. Cette URL possède plusieurs informations clés, comme :
jdbc:mysql : le protocole utilisé (un protocole peut être comparé à une langue, c’est un langage que 2 applications vont utiliser pour se comprendre).
localhost : le ‘host’, c'est-à-dire le poste où la base de données est installée. En l'occurrence, votre base de données étant sur le même poste que l’application que vous développez, vous pouvez spécifier ‘localhost’.
3306 : c’est le port de la base de données sur votre poste. Attention, ce port peut varier selon l’installation réalisée.
/carlib : c’est le nom de la base de données.
?serverTimeZone=UTC : ce paramètre supplémentaire permet de résoudre une erreur courante avec le driver MySQL.
spring.datasource.username : Nom de l’utilisateur pour se connecter à la base de données.
spring.datasource.password : Mot de passe de l’utilisateur spécifié précédemment.
spring.jpa.properties.hibernate.dialect : Spécifie au framework ORM le dialecte SQL à utiliser, cela permet d’optimiser les traitements du framework.
Mais… mais… Pourquoi y a-t-il une référence à Hibernate ? Je croyais qu’on faisait du Spring Data JPA ?
C’est une très bonne question ! Et je la saisis pour aller un peu plus dans le détail de ce framework. Rappelons que les frameworks ORM se basent sur JPA, une spécification (c'est-à-dire des règles à suivre). Les frameworks vont ensuite implémenter cette spécification (suivre ces règles) et fournir un code utilisable.
Hibernate est une implémentation JPA (tout comme EclipseLink ou OpenJPA). Spring Data JPA n’est pas tout à fait une implémentation JPA. C’est une autre couche entre la spécification JPA et une implémentation JPA. Cela s’appelle une abstraction.
Visuellement, on pourrait représenter cette structure selon une pile comme dans le schéma suivant :
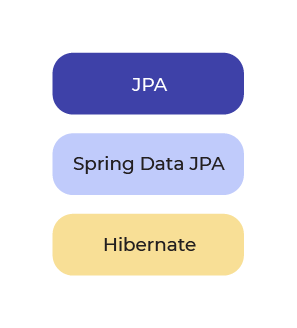
JPA est en haut de la pile car c’est la spécification.
Spring Data JPA vient ensuite, c’est un niveau d’abstraction, opérationnel.
Hibernate est une implémentation, c’est donc le plus bas niveau.
Pourquoi Spring Data JPA existe alors ? Hibernate ne suffit pas ?
Spring Data JPA existe en raison du leitmotiv de Spring : nous simplifier la vie !
Utiliser une implémentation JPA comme Hibernate n’est pas forcément une tâche aisée. Cela demande d’appréhender beaucoup de codes.
Spring Data JPA vient donc s'interférer entre la spécification JPA et Hibernate pour nous permettre d’utiliser cette implémentation sans devoir en apprendre toutes ses complexités. Et bien évidemment, en maintenant la performance !
Magnifique, non ? 
Maintenant que tout est clair (enfin je l’espère  ), nous sommes prêts à tester la connexion à la base de données. Rien de plus simple, nous allons démarrer notre projet et observer son comportement. Ce dernier nous révèlera si la connexion à la base de données est opérationnelle ou non.
), nous sommes prêts à tester la connexion à la base de données. Rien de plus simple, nous allons démarrer notre projet et observer son comportement. Ce dernier nous révèlera si la connexion à la base de données est opérationnelle ou non.
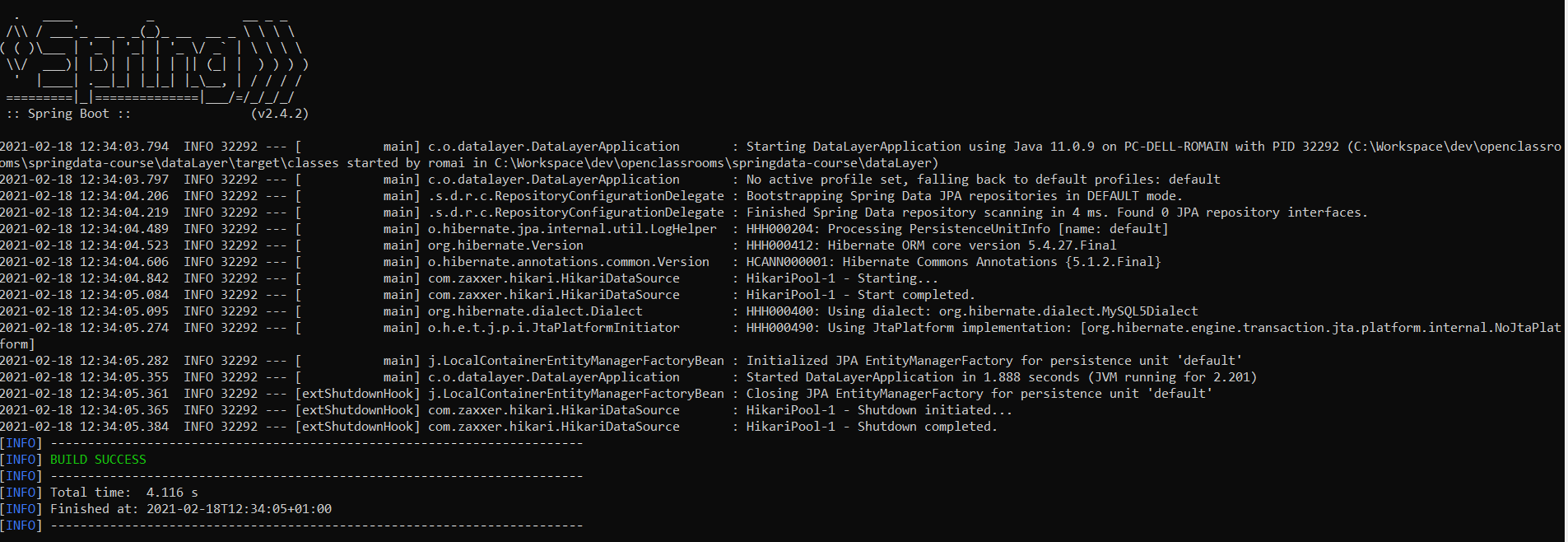
Je vous invite à ouvrir un invite de commande, à vous placer dans le répertoire du projet, puis à taper la commande Maven : mvn spring-boot:run.
Si votre configuration est valide, vous devriez obtenir un résultat qui ressemble au suivant avec un “BUILD SUCCESS”. 
Dans le cas où la configuration est erronée ou si la connexion a échoué, vous aurez un “BUILD FAILURE”.
J’en ai simulé un pour l’exemple, en supprimant toutes les propriétés du fichier application.properties :
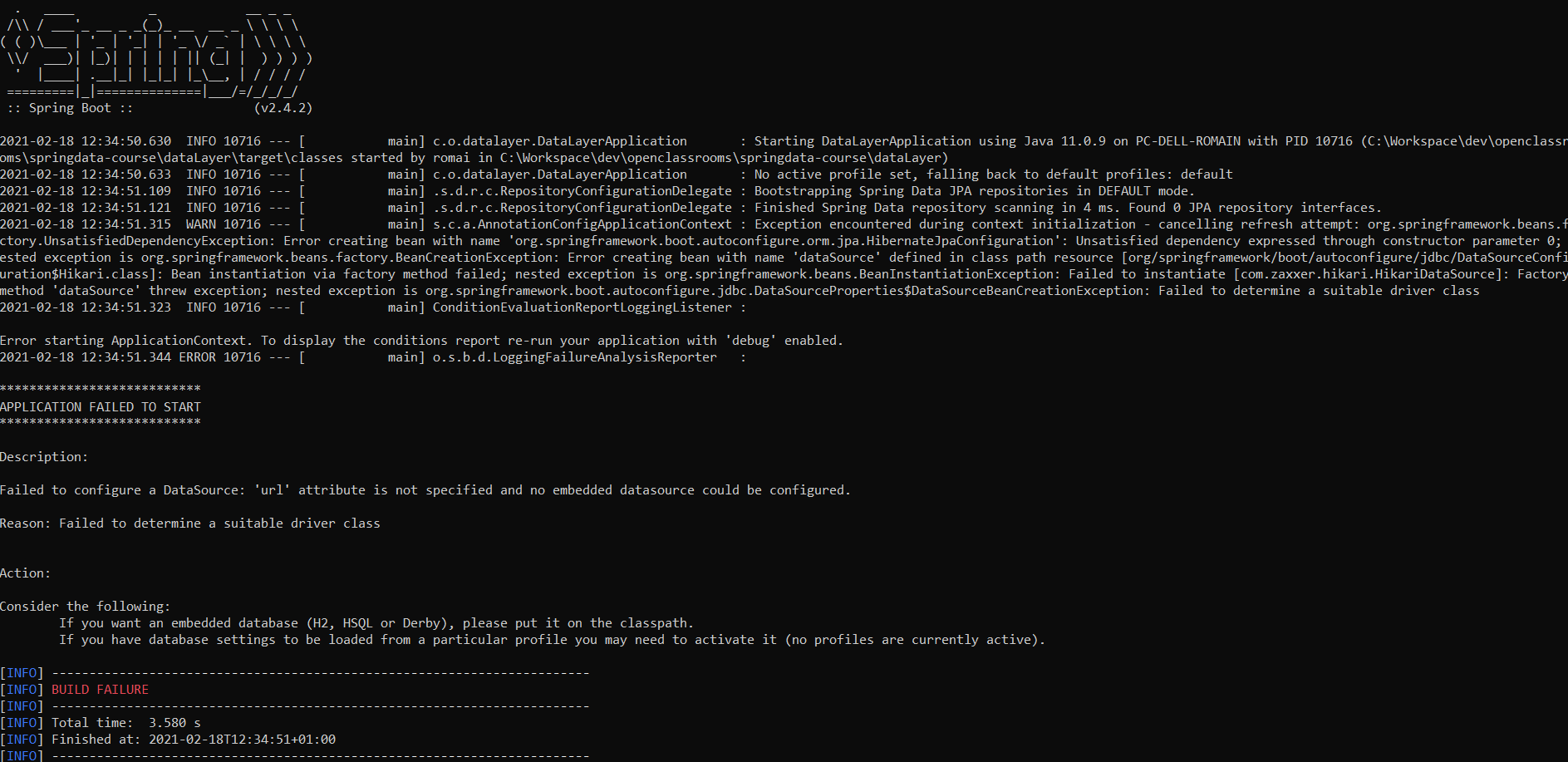
Je ne peux pas vous simuler tous les cas d’erreurs, mais soyez bien vigilant à l’URL, au nom d’utilisateur et au mot de passe, et bien évidemment à ce que votre base de données soit démarrée !
Externalisez les identifiants de connexion
Avant de conclure la première partie de ce cours, je vais vous montrer une dernière chose.
Mettons-nous en situation de production. La base de données est en production et l’application Java également.
Jusque là, ça va ! Mais voilà, les administrateurs système vous informent que votre précieuse base de données va être déplacée sur un autre serveur. C’est une catastrophe ! 
Je ne vois pas trop ce qu’il y a de grave là-dedans ?
Bon d’accord, je surréagis peut-être. Cependant, nous avons bien un problème !
D’accord, mais lequel ?
La mise en production de votre application Spring Boot signifie que vous avez packagé l’application dans un JAR. Ce JAR a ensuite été exécuté sur un serveur de production.
Et ce même JAR embarque la configuration d’accès à la base de données ! Si la base de données change de serveur, alors l’URL d’accès devra certainement être mise à jour. Et c’est là le problème : une fois le JAR construit, on ne peut plus accéder au fichier application.properties qui est embarqué dedans !
Bon certes, alors je modifie le fichier application.properties dans le projet, je re-construis le JAR et je remplace l’ancien, non ?
Idée valide, oui, mais ne trouvez vous pas que c’est un peu complexe pour une simple mise à jour d’un fichier de propriétés ? 
Laissez-moi vous proposer quelque chose de plus efficace ! Un peu avant, je vous avais présenté le fichier application.properties comme étant une source de propriétés pour Spring.
Spring Boot, par défaut, prend en compte de nombreuses autres sources de propriétés, comme :
Des arguments via la ligne de commande.
Les variables d’environnement.
Des fichiers de propriétés externes au JAR packagé.
Je vais donc vous montrer comment externaliser la configuration via 2 méthodes :
Avec les variables d’environnement.
Via un fichier de propriétés externes au JAR.
Ces 2 méthodes font partie des solutions pour éviter de reconstruire le JAR à chaque mise à jour nécessaire de la configuration (comme lorsqu’on déplace la base de données sur un autre serveur !).
Retrouvez-moi dans le screencast ci-dessous :
Alors, qu’en pensez-vous ? Assez simple, non ?
Je dois reconnaître que ce genre de facilité m’a particulièrement fait apprécier Spring Boot. Ce n’est pas surprenant que ce soit un framework incontournable en Java actuellement !
Reprenons ces 2 méthodes :
Variables d’environnement
Quel que soit votre système d’exploitation, vous pouvez ajouter de nouvelles variables d’environnement. Dans mon cas, sur Windows j’ai utilisé le menu “Modifier les variables d’environnement système”. Puis pour tester, j’ai ajouté une variable nommée “spring.datasource.password” avec la valeur “root”. Bien évidemment, cela peut être fait avec toutes les propriétés.
Et voilà, le tour est joué ! Votre application ira lire les variables d’environnement au démarrage, et la connexion à la base de données s’effectuera sans problème !
Fichier de propriétés externes au JAR
La documentation de Spring Boot indique que l’on peut placer le fichier application.properties dans un répertoire config situé dans le répertoire où l’application est exécutée.
L’arborescence donnerait alors quelque chose comme :
root_folder/
config/
application.properties
dataLayer.jar
Au démarrage du JAR, l’application ira lire le fichier, et les propriétés seront prises en compte. Voilà une excellente façon d’externaliser la configuration. C’est ma préférée. 
Enfin, il est également intéressant de noter que l’externalisation de la configuration renforce la sécurité de votre développement.
Rappelons d’ailleurs que bien souvent, le plus précieux au sein d’une application ce n’est pas le code, mais bien les données !
Vous comprenez donc qu’écrire en dur dans le code les informations de connexion à la base de données est une mauvaise pratique ! L’externalisation de la configuration est la solution à cette mauvaise pratique. 
C’est ainsi que nous terminons ce chapitre et la première partie du cours.
En résumé
La connexion à la base de données est facilitée par Spring.
La configuration doit contenir au minimum :
l'URL ;
le nom d'utilisateur du compte BDD ;
le mot de passe du compte utilisateur ;
le dialecte SQL.
La configuration peut être externalisée en dehors du JAR packagé, par exemple :
dans des variables d’environnement ;
dans un fichier applications.properties placé dans un répertoire config.
Pour apprendre à interagir avec la base de données, suivez-moi dans la deuxième partie du cours ! 
