Implémentez vos entités et les interfaces repository
Nous y voilà !  Nous allons implémenter la couche Java de communication avec la base de données !
Nous allons implémenter la couche Java de communication avec la base de données !
Carlib Assurances nous a missionnés pour la réalisation de sa nouvelle application, pour gérer les produits d’assurance auto.
Vous manipulerez donc les données suivantes :
Les catégories
Chaque produit d’assurance peut être associé à plusieurs catégories.
Par exemple : Standard (les produits classiques), Promotion (des produits avec une offre spéciale), Professionnelle, etc.
Les produits
Ils regroupent les différents produits d’assurance proposés par Carlib : Assurance tous risques, Assurance au tiers, Assurance au km.
Les commentaires
Carlib autorise ses clients à laisser des commentaires sur les produits.
Dans la partie précédente, vous avez mis en place une base de données qui est structurée et qui possède un échantillon de données.
Vous avez également créé le projet Java, et réalisé la connexion entre l’application et la base de données.
Une question se pose désormais : comment interagir avec la base de données ?
Pour y répondre, nous devons comprendre plus précisément le fonctionnement de Spring Data JPA.
Le fonctionnement de Spring Data JPA
Ce framework ORM met en pratique le design pattern DAO : Data Access Object. Ce patron de conception propose d’implémenter la communication avec la source de données via la structure suivante :
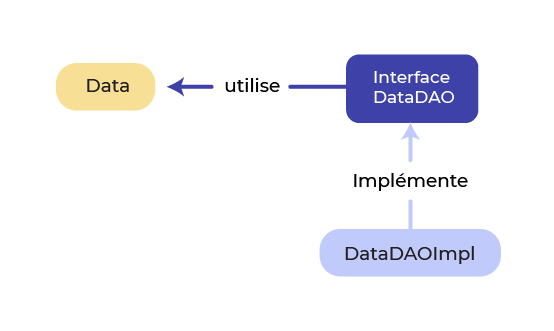
Le concept est le suivant :
Une donnée est modélisée via une classe (ci-dessus, Data).
Les opérations sur la base de données concernant cette donnée sont spécifiées via une interface (ci-dessus, DataDAO).
Les opérations sont implémentées dans une classe (ci-dessus, DataDAOImpl).
Et Spring Data JPA dans tout ça ?
Bonne question ! Spring Data JPA nous demande de respecter ce principe en :
Implémentant des classes qui représentent nos données. Ce sont nos entités. (Cf. classe Data dans le schéma ci-dessus).
Créant des interfaces pour manipuler ces entités. Ce sont des repositories. (Cf. interface DataDAO dans le schéma ci-dessus).
Et c’est tout !
Attends, il manque la classe DataDAOImpl du schéma ??
Oui… mais non ! Effectivement, elle manque, en ce sens où vous n’avez pas à la créer ; mais non, car c’est Spring Data JPA qui s’en charge de façon transparente ! Et c’est vraiment bien pour nous, car en réalité cette classe est la plus longue et la plus complexe à implémenter. C’est pour ça que Spring Data JPA est aussi prisé sur le marché : le gain de temps est considérable pour nous développeurs !
Cela fait beaucoup d’apports théoriques et peu de pratique ; si vous êtes un peu confus, ne vous inquiétez pas !
Passons à la pratique pour comprendre ces concepts, allez, c’est parti ! 
Implémentez les entités
Notre première étape est d’implémenter les entités qui représentent nos données. Pour les définir, suivez cette règle : pour chaque entité, il existe une table. Cependant attention, la réciproque n’est pas vraie, il n’y a pas forcément une entité pour chaque table, par exemple dans le cas des tables des jointures.
J’en profite d’ailleurs pour vous indiquer que vous rencontrerez 2 types de situations lorsque vous implémenterez des entités :
Vous implémentez une application pour une base de données qui existe déjà. De ce fait, vous allez généralement faire correspondre vos entités aux tables existantes.
Vous implémentez une application, mais la structure de la base de données n’a pas encore été définie. Dans ce cas, sachez que les frameworks ORM sont capables de générer la structure d’une base de données en fonction des entités déjà créées !
Cette deuxième possibilité est bien souvent une facilité pour les développeurs. Cela leur évite d’avoir à manipuler la base de données ! Encore un bon point pour Spring Data JPA. 
Dans ce cours, la structure de la base de données nous a déjà été livrée, nous sommes donc dans le cas 1.
Alors, reprenons ensemble le schéma de la base de données :
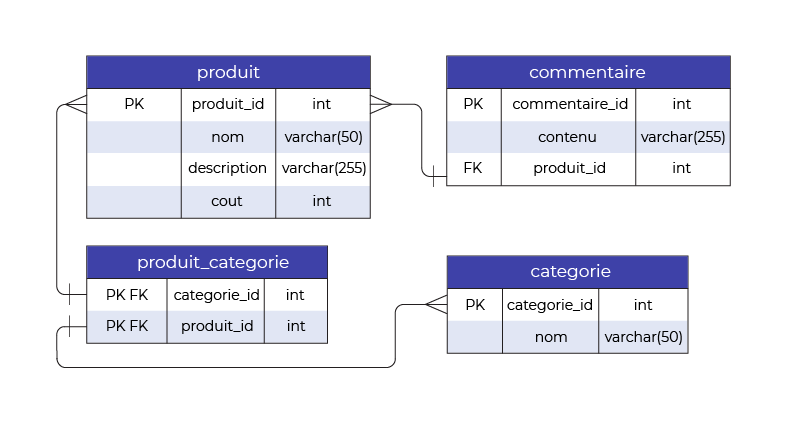
En excluant la table de jointure, nous avons 3 entités à modéliser : Product, Comment et Category.
Laissez-moi vous montrer comment implémenter la classe Product dans le screencast suivant :
Reprenons le code ensemble :
package com.openclassrooms.datalayer.model;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "produit")
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "produit_id")
private int productId;
@Column(name = "nom")
private String name;
@Column(name = "description")
private String description;
@Column(name = "cout")
private int cost;
// Add getters & setters
}
Arrêtons-nous sur ses spécificités :
@Entity est une annotation qui indique que la classe correspond à une table de la base de données.
@Table(name=”produit”) indique le nom de la table associée.
L’attribut productId correspond à la clé primaire de la table, et est donc annoté @Id.
D’autre part, comme l’id est auto-incrémenté, j’ai ajouté l’annotation @GeneratedValue(strategy = GenerationType.IDENTITY).
Enfin, les attributs sont annotés avec @Column pour faire le lien avec le nom du champ de la table.
À vous de jouer !
Maintenant que vous savez comment implémenter une entité, à vous de jouer ! Je vous propose d’implémenter les entités Catégorie et Commentaire.
Vous avez fini ?
N’hésitez pas à consulter le repository GitHub du cours à la branche p2c1, qui contient toutes les entités implémentées.
Passons à la suite !
Implémentez les interfaces Repository
Nous devrions maintenant implémenter le code qui exécute les actions pour communiquer avec la base de données. Autrement dit, un code qui soit capable d’exécuter des requêtes SQL, étant donné que le SQL est le langage utilisé pour communiquer avec une base de données.
Mais rappelons-le, Spring Data JPA nous évite cette tâche ! En lieu et place, il nous permet d’écrire uniquement des interfaces, et c’est lui qui nous fournira l’implémentation de ces dernières.
Retrouvez-moi dans ce screencast pour découvrir le fonctionnement de ces fameuses interfaces avec Spring Data JPA :
Reprenons le code que j’ai écrit :
package com.openclassrooms.datalayer.repository;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
import com.openclassrooms.datalayer.model.Product;
@Repository
public interface ProductRepository extends CrudRepository<Product, Integer> {
}
Laissez-moi vous expliquer ce code :
@Repository est une annotation Spring pour indiquer que la classe a pour rôle de communiquer avec une source de données (en l'occurrence la base de données).
L’interface étend CrudRepository. C’est une interface qui est fournie par Spring. Elle spécifie des méthodes pour manipuler votre entité. Elle utilise la généricité pour que son code soit applicable à n’importe quelle entité, d’où la syntaxe “CrudRepository<Produit, Integer>”.
La liste des méthodes disponibles est à retrouver dans la documentation Spring.
Retenons donc que Spring Data JPA fournit des interfaces (comme CrudRepository) que nous allons étendre pour créer nos propres interfaces adaptées aux entités de notre projet.
À vous de jouer !
Écrivez les interfaces pour Category et Comment !
N’hésitez pas à consulter le repository GitHub du cours à la branche p2c1 qui contient le code correspondant.
Implémentez la couche métier
Avant de clore ce chapitre, je vais vous demander d’ajouter une dernière classe. En architecture logicielle, il est très fréquent d’avoir une couche métier.
Dans le cas du projet Carlib Assurances en question, on pourrait se passer de cette couche métier. Cependant, même pour des projets à petite échelle, je vous recommande de suivre les bonnes pratiques quant à la structure du code. Il s’agit à cette étape de notre progression de créer 3 classes au sein du package com.openclassrooms.datalayer.service :
ProductService.java ;
CommentService.java ;
CategoryServicce.java.
Chaque classe aura l’annotation @Service (une autre spécialisation de @Component).
À vous de jouer !
Voici ProductService, je vous laisse faire les 2 autres. 
package com.openclassrooms.datalayer.service;
import org.springframework.stereotype.Service;
@Service
public class ProductService {
}
Pour la correction, je vous laisse regarder le repository GitHub du cours à la branche p2c1.
En résumé
Spring Data JPA se base sur le design pattern DAO pour la structure des classes et interfaces.
Vos données seront représentées en entités au sein de votre code. Une entité est une classe Java avec des attributs et des getters/setters.
Nul besoin d’implémenter les requêtes SQL pour interagir avec la base de données, par contre Spring Data JPA permet d’écrire des interfaces qui étendent l’interface CrudRepository. C’est le design pattern Repository.
Pour suivre l’architecture en couche, la couche métier est mise en place. Elle permet d’appliquer des traitements spécifiques sur les données avant l’interaction avec la base de données.
Nous allons pouvoir interagir avec la base de données ! Commençons par récupérer des données, c’est parti !
