Choisissez le bon stockage pour votre couche de données
Nous avons passé les deux premières parties de ce cours à séparer les couches en utilisant le MVC. Maintenant, dans cette partie du cours, nous allons nous pencher sur les différentes options à notre disposition pour implémenter ces couches. Dans ce chapitre, nous allons regarder plusieurs options pour la couche de données.
Lorsque l'on sépare la couche de données, on peut la modifier sans risquer d'impacter le reste du système. N’oubliez pas que, dans notre application, les objets du modèle n’appellent plus directement la couche de données. Nous avons maintenant une couche de données qui les appelle :
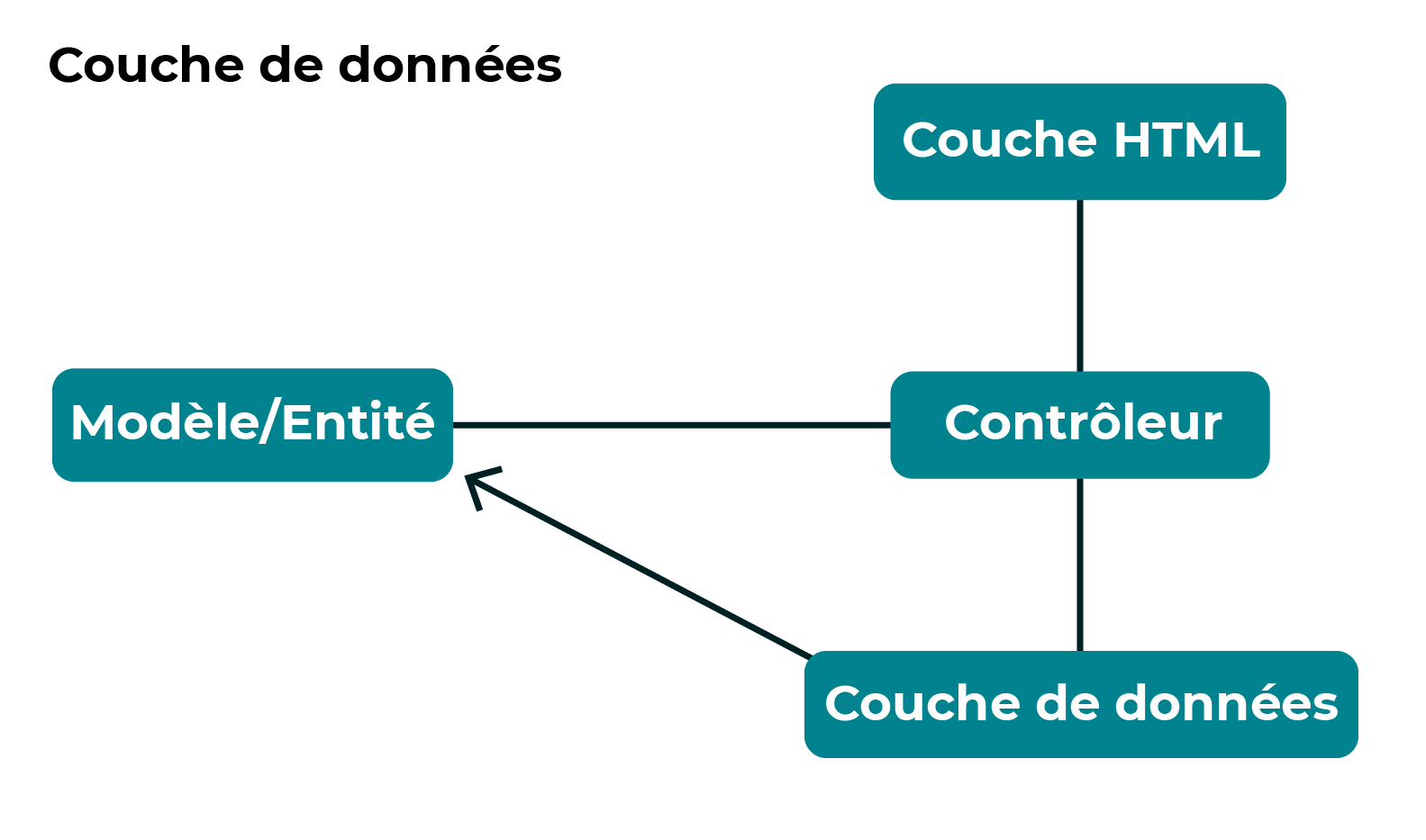
Lorsque nous avons commencé à utiliser le framework Spring Boot, la seule chose que nous avions à faire à nos classes de modèle était d’ajouter une annotation (@Entity), et de paramétrer des getters et setters. Lorsqu’un objet est nécessaire, le framework le crée, puis appelle les setters appropriés pour initialiser l’objet. Lorsque l’objet est modifié, les getters sont appelés, et les valeurs sont stockées.
Rappelez-moi, comment ce stockage est effectué ?
Simplement en utilisant le framework Spring Boot !
Mais souvent, nous avons besoin de manipuler les données de manière plus sophistiquée.
Vous vous souvenez de notre user story « trouver les clients ayant des impayés » ? L’ajout de cette fonctionnalité à notre classe de repository client était facile. Nous avons ajouté une méthode qui effectue cette recherche précise. Donc oui, techniquement, il s’agit d’un « read». Cela dit, l’appelant de cette méthode n’avait pas besoin de se préoccuper des contraintes SQL pour accomplir sa tâche. Il était caché aux yeux de l’élément appelé par le biais de la méthode (c’est-à-dire une API).
Nous allons explorer les avantages de l’utilisation d’une API pour gérer une architecture web découplée dans la prochaine section.
Limitez ce que peuvent faire les autres couches avec une API
Le fait de placer la couche de données derrière une API renforce la règle selon laquelle aucune autre couche ne gère de données. Si nous permettons à d’autres couches de parler directement à notre source de données, nous allons rencontrer des problèmes. Il n’y a pas de contrôle d’application des règles.
Qu’entendez-vous par "contrôle d’application des règles "?
Je vais prendre un exemple pour vous l’expliquer. Dans l’application originale, nous avons vu que n’importe quelle classe pouvait ouvrir une connexion SQLite, et écrire des données dans n’importe quelle table. La classe Client pouvait accéder à la table PILOT et y apporter un changement.
Voici une ligne de l’implémentation Client.java d’origine :
ResultSet rs = AirbusinessDb.getResultSet("SELECT * from clients");Elle accède bien sûr à la table CLIENTS.
En revanche, il n’y a aucun contrôle d’application des règles qui garantisse que cette ligne n’accède à aucune des autres tables de notre base de données. Cela signifie que nous pouvons facilement nous retrouver avec une valeur stockée illégale ou incorrecte. Par exemple, les tables CLIENTS et PILOTS ont tous deux un champ nommé téléphone. Sans contrôle d’application des règles, nous pouvons écrire une requête de modification de l’adresse du client comme celle-ci :
“UPDATE pilots SET telephone= ‘new telephone’ WHERE id = 5”;Oups. 😅
Nous avions la tête ailleurs, et nous avons accidentellement écrit « PILOTS » (pilotes) comme nom de table.
Bon, mais ce n’est pas bien grave, si ?
C’est encore pire qu’il n’y paraît !
À l’avenir, nous souhaiterons contacter ce pilote. Lorsque nous récupérerons son numéro de téléphone, nous allons en fait nous retrouver à appeler un client. C’est gênant… Et cela va nous prendre du temps avant de comprendre pourquoi nous joignons un client au lieu du pilote. Comme le SQL est disséminé partout, nous allons devoir rechercher toutes les fonctions d’insertion (insert) et de mise à jour (update) ! Ce n’est pas trop catastrophique avec cette petite application, mais imaginez une grosse application avec des centaines de déclarations de ce type. 😬 Une fois le problème trouvé, nous examinerons probablement nos autres déclarations SQL pour nous assurer que nous n’avons pas commis cette même erreur ailleurs.
J’ai travaillé sur des systèmes de ce type et, à moins d'être rémunéré à l’heure, ce n’est pas très amusant. 😠
Alors, en quoi une API peut-elle aider ?
Après avoir séparé la couche, et créé les classes de repository, l’erreur ci-dessus ne peut pas se produire. La classe repository du client n’accède qu’à la table CLIENTS.
Un autre avantage non négligeable : nous pouvons indiquer quelles données sont obligatoires pour une opération de données, et quelles données sont optionnelles.
Dans les opérations de données que les autres couches appellent, nous pouvons regarder les paramètres entrants. Si des champs obligatoires manquent ou sont incorrects, nous pouvons retourner une erreur significative à l’appelant, plutôt que de procéder à un appel qui échouera, ou pire, renseignera des champs à des valeurs illégales.
Nous en voyons un exemple avec les annotations sur certains des champs de nos classes du modèle. Par exemple, dans Client.java, nous avons :
@NotBlank(message = "First Name is mandatory")
private String firstName;Maintenant que vous avez vu l’intérêt d’utiliser une API pour gérer votre couche de données, voyons comment l’implémenter.
Implémentez une couche de données avec une API
Souvenez-vous : nous avions besoin de lister tous les clients avec des impayés. Nous avons donc ajouté ce qui suit au ClientRepository :
@Query("SELECT c FROM Client c WHERE c.outstandingBalance > 0.0")Étant donné que les classes du repository ont été séparées des entités qu’elles contrôlent, il est facile d’ajouter de nouvelles recherches et manipulations. Elles iront simplement dans les classes repository et contrôleur. Nous ne modifions pas du tout les classes entités du modèle !
Voyons ça de plus près :
Nous allons ajouter la fonctionnalité pour une user story totalement nouvelle qui est apparue au cours des discussions avec Air Business :
« En tant que mécanicien en chef, je veux voir tous les problèmes de maintenance non résolus, afin de pouvoir planifier les interventions des mécaniciens. »
De la même façon que nous l'avons fait pour la fonctionnalité qui liste les clients avec des impayés, nous allons ajouter cette nouvelle fonctionnalité en ajoutant :
un bouton à l’écran de maintenance.
une requête à la classe MaintenanceRepository.
un endpoint d’API à la classe MaintenanceController.
Étape 1 : Ajoutez un bouton à l’écran de maintenance
Modifiez le fichier src/main/resources/maintenance.html et ajoutez cette ligne sous l’autre déclaration de bouton :
<a href="/maintenance/unfixed" class="btn btn-primary">Not Fixed</i></a></p>Exécutez à nouveau l’application pour vous assurer que le bouton apparaît sur l’écran de maintenance.
Si vous cliquez dessus, cela provoquera une erreur. Pourquoi ? Parce que nous n’avons pas écrit le code « unfixed» dans le contrôleur pour l’instant.
Étape 2 : Ajoutez une requête à la classe MaintenanceRepository
Modifiez le fichier MaintenanceRepository et ajoutez la méthode suivante :
List<MaintenanceIssue> findByFixed(String fixed);Lorsque nous appelons cette méthode depuis la classe de contrôleur, nous passons une chaîne vide pour trouver les éléments sans valeur pour la date de réparation.
Étape 3 : Ajoutez un endpoint d’API à la classe MaintenanceController
Modifiez le fichier MaintenanceController et ajoutez les lignes suivantes :
@RequestMapping("/maintenance/unfixed")
public String unFixed( Model model) {
model.addAttribute("maintenance", maintenanceRepository.findByFixed(""));
return "maintenance";
}Et c’est aussi simple que ça : nous avons une nouvelle fonctionnalité dans note API ! Nous avons ajouté un nouvel endpoint (maintenance/unfixed), qui recherche les problèmes de maintenance sans date de réparation.
Choisissez une source de données
Le plus gros avantage dont nous bénéficions lorsque nous plaçons les données dans leur propre couche est la flexibilité. Toutes les autres couches qui ont besoin de la couche de données ne savent en fait rien sur le stockage concret des données. Elles ont uniquement besoin de savoir comment parler à la couche : via l’API. En revanche, nous devons toujours choisir comment stocker nos données.
Quelles options s’offrent à nous pour les sources de données ?
Nous avons les bases de données :
relationnelles SQL
orientées de colonnes
orientées documents
Regardons chacune d’entre elles.
Option 1 : Choisissez les bases de données relationnelles et le SQL
Si les données à gérer sont très structurées, alors nous pouvons nous reposer sur une base de données SQL, qui est une solution fiable.
Nous pourrions avoir besoin d’ajouter une table ou une colonne à notre modèle de temps en temps, mais globalement le format des données reste le même. Si telle est votre situation, choisissez cette technologie qui a fait ses preuves.
J’ai eu à modéliser une base de données qui allaient devoir stocker des tickets de ventes : un ticket de vente est très structuré et cette structure évolue très peu dans le temps (vous êtes d’accord que nos tickets de caisse sont à peu près les mêmes depuis 30 ans !) : il y un en-tête avec des informations diverses, et des lignes, qui ont chacune une quantité et une référence à un produit. Ici, la donnée est donc bien organisée, peu changeante et il y aura souvent besoin de joindre une donnée en-tête avec ses lignes, voire même de joindre un produit avec toutes ses lignes de vente : le SQL est ici une solution adaptée.
Les questions liées à la taille comptent parmi les inconvénients des bases de données relationnelles. De nombreuses implémentations allouent la même quantité d’espace (mémoire et disque) à une ligne qui a des champs vides, qu’à une ligne remplie de données. Par conséquent, si vos données se retrouvent avec de nombreux « espaces vides », il vous faudra peut-être envisager l’option suivante de notre liste.
Option 2 : Utilisez une base de données orientée colonnes
Les plus courantes sont :
Cassandra
HBase
Accumulo
DynamoDB
Hypertable
Si nos données ne sont pas tout à fait propres et nettes, nous pouvons opter pour une approche plus flexible orientée colonnes. Elle ressemble à l’approche par colonnes d’une base de données SQL, mais les colonnes ont beaucoup plus de flexibilité dynamique. Chaque ligne n’a pas besoin d’avoir la même structure de colonnes que toutes les autres.
Par exemple, les données de posts de blog ou le flux de données d’un appareil médical fonctionnent bien avec les bases orientées colonnes.
J’ai eu à développer un site de petites annonces de matériel sportif. En fait, non ! Au début, il s’agissait de petites annonces de vélo uniquement. Mais ensuite bien-sûr, les annonces se sont élargies aux rollers, trottinettes, monocycles, etc. Joindre les données entre elles n'étaient pas forcément nécessaire. Par contre, la typologie des annonces s’est avérée très variable et évolutive : un vélo électrique a une puissance, alors qu’un vélo non. Des rollers ont une pointure, alors qu’une trotinette non. L’option NoSQL était ici pertinente !
Option 3 : Utilisez une base de données orientée documents
Enfin, si nos données ne se conforment à aucune structure, nous pouvons utiliser une base de données orientée documents. En voici certains exemples courants :
CouchDB
MongoDB
Marklogic
Terrastore
OrientDB
RavenDB
Jackrabbit
Par exemple, si nous avons un dossier de données médicales, nous pouvons stocker les données en fonction du numéro d’identifiant du patient, faisant office de clé.
Nous pouvons facilement ajouter des métadonnées supplémentaires :
la date
l’emplacement du patient au moment de l’enregistrement
une série de radios
un diagnostic,
des recommandations de traitement du médecin.
Ce type d’archives n’a pas de forme à proprement parler que l'on peut saisir facilement dans une base de données relationnelle. Par conséquent, si vos données partent dans tous les sens, la base de données orientée documents constitue probablement votre meilleure option.
Implémentez une source de données SQLite
Nous utilisons actuellement une source de données en mémoire dans notre application Spring Boot. Nous allons plutôt utiliser SQLite comme source persistante (option 1), car l’application d’origine l’utilisait, et nous pouvons tirer profit de toutes les données héritées qui y sont stockées.
Nous suivrons ces étapes :
Ajoutez des dépendances SQL à notre fichier POM.
Ajoutez le dialecte spécifique à SQL.
Modifiez le fichier application.properties pour inclure SQLite.
Ajoutez un fichier persistence.xml aux ressources.
Modifiez l’attribut ID de toutes les classes d’entités.
Allons-y.
Ajoutez des dépendances SQL à notre fichier POM
Remplacez la dépendance com.h2database avec ce qui suit dans le fichier pom.xml :
<dependency>
<groupId>org.xerial</groupId>
<artifactId>sqlite-jdbc</artifactId>
<version>3.34.0</version>
</dependency>
<dependency>
<groupId>com.zsoltfabok</groupId>
<artifactId>sqlite-dialect</artifactId>
<version>1.0</version>
</dependency>Ajoutez des classes spécifiques à SQLite
SQL est un langage normé. Cela veut dire que chaque “organisme” qui l’implémente le fait un peu différemment. De plus, Spring Boot ne sait pas de lui-même comment interagir spécifiquement avec SQLite. Nous avons besoin d’un ou deux fichiers qui lient SQLite, notre modèle, et Spring Boot les uns aux autres.
Créez un package nommé « com.airbusiness.airbusinessmvc.sqlite ».
Créez une classe nommée SQLiteDialect.java qui étend org.hibernate.dialect.Dialect dans le paquet.
Regardez dans le repo GitHub pour voir ce qui appartient à cette classe. Il s’agit surtout de méthodes de recherches.
Ajoutez une classe nommée
SQLiteColumnSupport.javaqui étendorg.hibernate.dialect.identity.IdentityColumnSupportImpldans le package.Puis, ajoutez les lignes de code suivantes. Elles disent à Spring Boot comment traiter nos colonnes d’identifiants (qui sont toujours des entiers), et comment incrémenter l’identifiant à chaque fois que nous avons une ligne :
@Override
public boolean supportsIdentityColumns() {
return true;
}
@Override
public String getIdentitySelectString(String table, String column, int type) throws MappingException {
return "select last_insert_rowid()";
}
@Override
public String getIdentityColumnString(int type) throws MappingException {
return "integer";
}Modifiez le fichier application.properties pour inclure SQLite
Modifiez le fichier src/main/resources/application.properties pour inclure ce qui suit :
# DB PROPERTIES #
spring.datasource.url = jdbc:sqlite:airbusiness.db
spring.datasource.driver-class-name = org.sqlite.JDBC
# pretty print the sql queries to stdout
spring.jpa.properties.hibernate.format_sql=true
spring.jpa.show-sql=trueAjoutez un fichier persistence.xml aux ressources
Regardez dans le repo GitHub pour voir ce qui doit aller dans le fichier. Il s’agit de paramètres pour SQLite.
Modifiez l’attribut ID de toutes les classes d’entités
Modifiez Client.java, MaintenanceIssue.java, Pilot.java, Plane.java et Reservation.java de façon à ce que l’annotation de chaque attribut ID puisse être correctement généré automatiquement pour SQLite. Changez le type de génération (GenerationType) d’AUTO à IDENTITY. Le code devrait ressembler à ce qui suit :
@Id
// @GeneratedValue(strategy = GenerationType.AUTO)
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;Voyons comment cela s’applique à l’un de nos extraits d’origine (ci-dessous) :
public class Client {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;Avec la modification, nous obtenons :
public class Client {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;Et maintenant, notre application sauvegarde et récupère à nouveau des données depuis une base de données SQL !
En résumé
Les autres couches ne doivent pas contrôler directement la couche de données. Pour éviter cette situation, on écrit une API qui reflète les intentions de la couche de données.
Il faut choisir une façon adaptée de stocker vos données :
Une base SQL si les données sont propres et bien organisées.
Une base NoSQL orientée colonnes si les données sont organisées, mais changeantes.
Une base de données orientée documents si le format des données est totalement libre.
Et maintenant, gérons un peu la communication entre nos différentes couches !
