Utilisez les itérateurs et les foncteurs

Vous avez appris à ajouter des éléments à l'intérieur, mais vous avez dû rester un peu sur votre faim. Il faut bien sûr apprendre à parcourir les conteneurs et à appliquer des traitements aux éléments. Pour ce faire, nous allons avoir besoin de deux notions, les itérateurs et les foncteurs.
Parcourez les conteneurs grâce aux itérateurs
Dans le cours Apprenez à programmer en C++, nous avons vu que les pointeurs peuvent être assimilés à des flèches pointant sur les cases de la mémoire de l'ordinateur. Ce n'est bien sûr qu'une image, mais elle va nous aider par la suite.
Un conteneur est un objet contenant des éléments, un peu comme la mémoire contient des variables. Les concepteurs de la STL ont donc eu l'idée de créer des pointeurs spéciaux pour se déplacer dans les conteneurs, comme le ferait un pointeur dans la mémoire.
Voici les avantages d'utiliser cette manière de faire :
on déplace l'itérateur en utilisant les opérateurs
++et--, comme pour un pointeur ;on accède à l'élément pointé (ou itéré) via l'étoile
*.
Déclarez un itérateur…
Chaque conteneur possède son propre type d'itérateur, mais la manière de les déclarer est toujours la même. Comme toujours, il faut un type et un nom.
Choisir un nom, c'est votre problème mais, pour le type, je vais vous aider.
Par exemple, pour un itérateur sur un vector d'entiers, on a :
#include <vector>
using namespace std;
vector<int> tableau(5,4); //Un tableau de 5 entiers valant 4
vector<int>::iterator it; //Un itérateur sur un vector d'entiersVoici encore quelques exemples :
map<string, int>::iterator it1; //Un itérateur sur les tables associatives string-int
deque<char>::iterator it2; //Un itérateur sur une deque de caractères
list<double>::iterator it3; //Un itérateur sur une liste de nombres à virguleBon. Je crois que vous avez compris.
… et itérez
Il ne nous reste plus qu'à les utiliser.
Tous les conteneurs possèdent une méthode begin() renvoyant un itérateur sur le premier élément contenu. On peut ainsi faire pointer l'itérateur sur le premier élément. On avance alors dans le conteneur en utilisant l'opérateur ++ .
Il ne nous reste plus qu'à spécifier une condition d'arrêt. On ne veut pas aller en dehors du conteneur. Pour éviter cela, les conteneurs possèdent une méthode end() renvoyant un itérateur sur la fin du conteneur.
On peut donc parcourir un conteneur en itérant dessus depuis begin() jusqu'à end() .
Voyons cela avec un exemple :
#include<deque>
#include <iostream>
using namespace std;
int main()
{
deque<int> d(5,6); //Une deque de 5 éléments valant 6
deque<int>::iterator it; //Un itérateur sur une deque d'entiers
//Et on itère sur la deque
for(it = d.begin(); it!=d.end(); ++it)
{
cout << *it << endl; //On accède à l'élément pointé via l'étoile
}
return 0;
}Simple, non ? Si vous avez aimé les pointeurs (si tant est que ce soit possible), vous allez adorer les itérateurs.
Pour les vector et les deque , cela peut vous sembler inutile : on peut faire aussi bien avec les crochets [] . Mais pour les map et surtout les list , ce n'est pas vrai : les itérateurs sont le seul moyen que nous avons de les parcourir.
Voici un screencast qui montre un exemple d’utilisation des itérateurs sur un vecteur d’entiers. Nous allons tout d’abord créer un vecteur contenant des entiers, et ensuite utiliser une boucle for qui itère sur les éléments du conteneur à l’aide des itérateurs.
Des méthodes uniquement pour les itérateurs
Même pour les vector ou deque , il existe des méthodes qui nécessitent l'emploi d'itérateurs.
Il s'agit en particulier des méthodes insert() et erase() qui, comme leur nom l'indique, permettent d'ajouter ou supprimer un élément au milieu d'un conteneur.
Un exemple vaut mieux qu'un long discours :
#include <vector>
#include <string>
#include <iostream>
using namespace std;
int main()
{
vector<string> tab; //Un tableau de mots
tab.push_back("les"); //On ajoute deux mots dans le tableau
tab.push_back("Developpeurs");
tab.insert(tab.begin(), "Salut"); //On insère le mot "Salut" au début
//Affiche les mots donc la chaîne "Salut les Developpeurs"
for(vector<string>::iterator it=tab.begin(); it!=tab.end(); ++it)
{
cout << *it << " ";
}
tab.erase(tab.begin()); //On supprime le premier mot
//Affiche les mots donc la chaîne "les Developpeurs"
for(vector<string>::iterator it=tab.begin(); it!=tab.end(); ++it)
{
cout << *it << " ";
}
return 0;
}Et c'est la même chose pour tous les types de conteneurs. Si vous avez un itérateur sur un élément, vous pouvez le supprimer via erase() ou ajouter un élément juste après grâce à insert() .
Je vous avais dit que vous alliez adorer ce chapitre ! Et cela ne fait que commencer.
Les différents itérateurs
Terminons quand même avec quelques aspects un petit peu plus techniques.
Parmi les cinq types d'itérateurs, seuls deux sont utilisés pour les conteneurs :
Les "bidirectional iterators".
Et les "random access iterators".
Voyons ce qu'ils nous proposent.
Les "bidirectional iterators"
Ce sont des itérateurs qui permettent d'avancer et de reculer sur le conteneur. Cela veut dire que vous pouvez utiliser aussi bien ++ que -- .
Ce sont les itérateurs utilisés pour les list , set et map . On ne peut donc pas utiliser ces itérateurs pour accéder directement au milieu d'un de ces conteneurs.
Les "random access iterators"
Ces itérateurs permettent d'accéder directement au milieu d'un conteneur.
Par exemple pour accéder au huitième élément d'un vector , on peut utiliser cette syntaxe :
vector<int> tab(100,2); //Un tableau de 100 entiers valant 2
vector<int>::iterator it = tab.begin() + 7; //Un itérateur sur le 8ème élémentEn plus des vector , ces itérateurs sont ceux utilisés par les deque .
Utilisez les list et les map
Les list
C'est un conteneur assez différent de ce que vous connaissez.
Les éléments ne sont pas rangés les uns à côté des autres dans la mémoire. Chaque case contient un élément et un pointeur sur la case suivante, située ailleurs dans la mémoire :
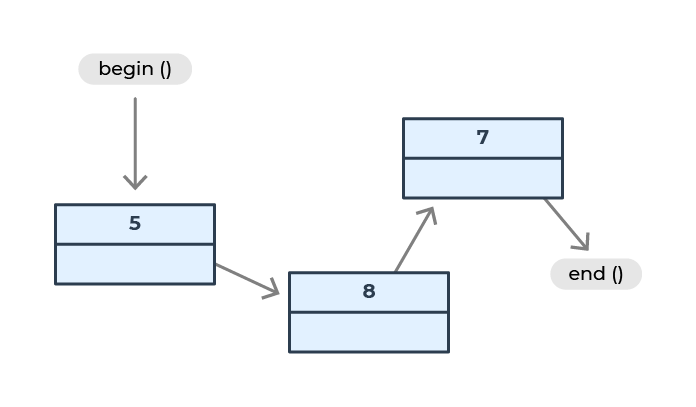
L'avantage de cette structure de données est que l'on peut facilement ajouter des éléments au milieu. Il n'est pas nécessaire de décaler toute la suite, comme dans l'exemple de la bibliothèque du chapitre précédent.
Mais (il y a toujours un mais) on ne peut pas directement accéder à une case donnée… tout simplement parce qu'on ne sait pas où elle se trouve dans la mémoire. On est obligé de suivre toute la chaîne des éléments. Pour aller à la huitième case, il faut aller à la première case, suivre le pointeur jusqu'à la deuxième, suivre le pointeur jusqu'à la troisième, et ainsi de suite jusqu'à la huitième. C'est donc très coûteux.
Passer de case en case, dans l'ordre, est une mission parfaite pour les itérateurs. Et puis, il n'y a pas d'opérateur [] pour les listes. On n'a donc pas le choix !
L'avantage, c'est que tout se passe comme pour les autres conteneurs. On n'a pas besoin de connaître les spécificités du conteneur pour itérer dessus.
#include <list>
#include <iostream>
using namespace std;
int main()
{
list<int> liste; //Une liste d'entiers
liste.push_back(5); //On ajoute un entier dans la liste
liste.push_back(8); //Et un deuxième
liste.push_back(7); //Et encore un !
//On itère sur la liste
for(list<int>::iterator it = liste.begin(); it!=liste.end(); ++it)
{
cout << *it << endl;
}
return 0;
}Super, non ?
Les map
La structure interne des map est plus compliquée que celle des list .
Les map utilisent ce qu'on appelle des arbres binaires, et se déplacer dans un tel arbre peut vite devenir un vrai casse-tête.
Grâce aux itérateurs, ce n'est pas à vous de vous préoccuper de tout cela. Vous utilisez simplement les opérateurs ++ et -- , et l'itérateur saute d'élément en élément. Toutes les opérations complexes sont masquées à l'utilisateur.
Il y a juste une petite subtilité avec les tables associatives. Chaque élément est en réalité constitué d'une clé et d'une valeur. Un itérateur ne peut pointer que sur une seule chose à la fois. Il y a donc à priori un problème. Rien de grave, je vous rassure.
Les pair sont déclarées dans le fichier d'en-tête utility . Il est cependant très rare de devoir utiliser directement ce fichier, puisqu'il est inclus par presque tous les autres.
Créons quand même une paire, simplement pour essayer :
#include <utility>
#include <iostream>
using namespace std;
int main()
{
pair<int, double> p(2, 3.14); //Une paire contenant un entier valant 2 et un nombre à virgule valant 3.14
cout << "La paire vaut (" << p.first << ", " << p.second << ")" << endl;
return 0;
}Et c'est tout ! On ne peut rien faire d'autre avec une paire. Elles servent juste à contenir deux objets.
Les deux attributs sont publics. Cela peut vous sembler bizarre, puisque je vous ai conseillé de toujours déclarer vos attributs dans la partie privée de la classe.
C'est juste un outil très basique, et on n'a pas envie de s'embêter avec des méthodes get() et set() . C'est pour cela que les attributs sont publics.
Je vous ai dit au chapitre précédent que les map triaient leurs éléments selon leurs clés. Nous allons maintenant pouvoir le vérifier facilement :
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main()
{
map<string, double> poids; //Une table qui associe le nom d'un animal à son poids
//On ajoute les poids de quelques animaux
poids["souris"] = 0.05;
poids["tigre"] = 200;
poids["chat"] = 3;
poids["elephant"] = 10000;
//Et on parcourt la table en affichant le nom et le poids
for(map<string, double>::iterator it=poids.begin(); it!=poids.end(); ++it)
{
cout << it->first << " pese " << it->second << " kg." << endl;
}
return 0;
}Si vous testez, vous verrez que les animaux sont affichés par ordre alphabétique, même si on les a insérés dans un tout autre ordre :
chat pese 3 kg. elephant pese 10000 kg. souris pese 0.05 kg. tigre pese 200 kg.
Les itérateurs sont aussi utiles pour rechercher quelque chose dans une table associative.
L'opérateur [] permet d'accéder à un élément donné, mais il a un défaut. Si l'élément n'existe pas, l'opérateur [] le crée. On ne peut pas l'utiliser pour savoir si un élément donné est déjà présent dans la table ou pas.
Vérifier si une clé existe déjà dans une table est donc très simple.
Reprenons la table de l'exemple précédent, et vérifions si le poids d'un chien s'y trouve :
int main()
{
map<string, double> poids; //Une table qui associe le nom d'un animal à son poids
//On ajoute les poids de quelques animaux
poids["souris"] = 0.05;
poids["tigre"] = 200;
poids["chat"] = 3;
poids["elephant"] = 10000;
map<string, double>::iterator trouve = poids.find("chien");
if(trouve == poids.end())
{
cout << "Le poids du chien n'est pas dans la table" << endl;
}
else
{
cout << "Le chien pese " << trouve->second << " kg." << endl;
}
return 0;
}Je sens que vous êtes déjà des fans des itérateurs.
Dans ce screencast, nous allons voir comment :
créer, itérer sur une
map;récupérer la clé et la valeur d’une case de la
map;utiliser la méthode
find()sur unemap.
C'est parti !
Découvrez les foncteurs : la version objet des fonctions
Si vous suivez un cours d'informatique à l'université, on vous dira que les itérateurs sont des abstractions des pointeurs, et que les foncteurs sont des abstractions des fonctions. Et généralement, le cours va s'arrêter là. Je pourrais faire de même et vous laisser vous débrouiller avec un ou deux exemples, mais je ne pense pas que vous seriez très heureux.
Ce que l'on aimerait faire, c'est appliquer des changements sur des conteneurs ; par exemple :
prendre un tableau de lettres et toutes les convertir en majuscules ;
ou prendre une liste de nombres et ajouter 5 à tous les nombres pairs.
Bref, on aimerait appliquer une fonction sur tous les éléments d'un conteneur.
Le problème, c'est qu'il faudrait pouvoir passer cette fonction en argument d'une méthode du conteneur. On ne peut passer que des objets en argument, pas des fonctions.
Les foncteurs sont des objets possédant une surcharge de l'opérateur () . Ils peuvent ainsi agir comme une fonction, mais être passés en argument à une méthode ou à une autre fonction.
Créez un foncteur
Commençons avec un exemple simple, un foncteur qui additionne deux entiers :
class Addition{
public:
int operator()(int a, int b) //La surcharge de l'opérateur ()
{
return a+b;
}
};Cette classe ne possède pas d'attribut. Elle possède juste une méthode, la fameuse surcharge de l'opérateur () . Comme il n'y a pas d'attribut et rien de spécial à effectuer, le constructeur généré par le compilateur est largement suffisant.
On peut alors utiliser ce foncteur pour additionner deux nombres :
#include <iostream>
using namespace std;
int main()
{
Addition foncteur;
int a(2), b(3);
cout << a << " + " << b << " = " << foncteur(a,b) << endl; //On utilise le foncteur comme s'il s'agissait d'une fonction
return 0;
}Ce code donne bien évidemment le résultat escompté :
2 + 3 = 5
Et l'on peut bien sûr créer tout ce que l'on veut comme foncteur. Par exemple, un foncteur ajoutant 5 aux nombres pairs peut être écrit comme ça :
class Ajout{
public:
int operator()(int a) //La surcharge de l'opérateur ()
{
if(a%2 == 0)
return a+5;
else
return a;
}
};Rien de neuf, en somme !
Des foncteurs évolutifs
Cela nous permet en quelque sorte de créer une fonction avec une mémoire. Elle pourra donc effectuer une opération différente à chaque appel.
Je pense qu'un exemple sera plus parlant :
class Remplir{
public:
Remplir(int i)
:m_valeur(i)
{}
int operator()()
{
++m_valeur;
return m_valeur;
}
private:
int m_valeur;
};On peut par exemple l'utiliser pour remplir un vector avec les nombres de 1 à 100. Je vous laisse essayer. Mais comme c'est encore une notion récente pour vous, je vous propose une solution :
int main()
{
vector<int> tab(100,0); //Un tableau de 100 cases valant toutes 0
Remplir f(0);
for(vector<int>::iterator it=tab.begin(); it!=tab.end(); ++it)
{
*it = f(); //On appelle simplement le foncteur sur chacun des éléments du tableau
}
return 0;
}Ceci n'est bien sûr qu'un exemple tout simple. On peut créer des foncteurs avec beaucoup d'attributs et des comportement bien plus complexes. On peut aussi ajouter d'autres méthodes pour réinitialiser m_valeur , par exemple. Comme ce sont des objets, tout ce que vous savez à leur sujet reste valable !
Les prédicats
On les utilise pour répondre à des questions comme :
Ce nombre est-il plus grand que 10 ?
Cette chaîne de caractères contient-elle des voyelles ?
Ce
Personnageest-il encore vivant ?
Ces prédicats seront très utiles dans la suite. Nous verrons au prochain chapitre comment supprimer des objets qui vérifient une certaine propriété, et c'est bien sûr un foncteur de ce genre qu'il faudra utiliser !
Voyons quand même un petit code avant d'aller plus loin. Prenons le cas d'un prédicat qui teste si une chaîne de caractères contient des voyelles :
class TestVoyelles
{
public:
bool operator()(string const& chaine) const
{
for(int i(0); i<chaine.size(); ++i)
{
switch (chaine[i]) //On teste les lettres une à une
{
case 'a': //Si c'est une voyelle
case 'e':
case 'i':
case 'o':
case 'u':
case 'y':
return true; //On renvoie 'true'
default:
break; //Sinon, on continue
}
}
return false; //Si on arrive là, c'est qu'il n'y avait pas de voyelle du tout
}
};Terminons cette section en jetant un coup d'œil à quelques foncteurs prédéfinis dans la STL. Eh oui, il y en a même pour les fainéants !
Les foncteurs prédéfinis
Pour les opérations les plus simples, le travail est prémâché. Tout se trouve dans le fichier d'en-tête functional .
Le premier foncteur que je vous ai présenté prenait comme arguments deux entiers, et renvoyait la somme de ces nombres. La STL propose un foncteur nommé plus pour faire cela :
#include <iostream>
#include <functional> //Ne pas oublier !
using namespace std;
int main()
{
plus<int> foncteur; //On déclare le foncteur additionnant deux entiers
int a(2), b(3);
cout << a << " + " << b << " = " << foncteur(a,b) << endl; //On utilise le foncteur comme s'il s'agissait d'une fonction
return 0;
}Comme pour les conteneurs, il faut indiquer le type souhaité entre les chevrons. En utilisant ces foncteurs prédéfinis, on s'économise un peu de travail.
Voyons finalement comment utiliser ces foncteurs avec des conteneurs.
Fusionnez les deux concepts
Pour l'instant, nous allons modifier le critère de tri des map grâce à un foncteur.
Modifiez le comportement d'une map
L'opérateur < pour les string compare les chaînes par ordre alphabétique.
Changeons ce comportement pour utiliser une comparaison des longueurs.
Je vous laisse essayer d'écrire un foncteur comparant la longueur de deux string .
Voici ma solution :
#include <string>
using namespace std;
class CompareLongueur
{
public:
bool operator()(const string& a, const string& b)
{
return a.length() < b.length();
}
};Il ne reste maintenant plus qu'à indiquer à notre map que nous voulons utiliser ce foncteur :
int main()
{
//Une table qui associe le nom d'un animal à son poids
map<string, double,CompareLongueur> poids; //On utilise le foncteur comme critère de comparaison
//On ajoute les poids de quelques animaux
poids["souris"] = 0.05;
poids["tigre"] = 200;
poids["chat"] = 3;
poids["elephant"] = 10000;
//Et on parcourt la table en affichant le nom et le poids
for(map<string, double>::iterator it=poids.begin(); it!=poids.end(); ++it)
{
cout << it->first << " pese " << it->second << " kg." << endl;
}
return 0;
}Et ce programme donne le résultat suivant :
chat pese 3 kg. tigre pese 200 kg. souris pese 0.05 kg. elephant pese 10000 kg.
Les animaux ont été triés suivant la longueur de leur nom. Changer le comportement d'un conteneur est donc une opération très simple à réaliser.
En résumé
Les itérateurs sont assimilables à des pointeurs limités à un conteneur.
On utilise les opérateurs
++et--pour les déplacer, et l'opérateur*pour accéder à l'élément pointé.Les foncteurs sont des classes qui surchargent l'opérateur
(). On les utilise comme des fonctions.La STL utilise beaucoup les foncteurs pour modifier le comportement de ses conteneurs.
Je pense que maintenant vous ne serez plus capable de vous passer des itérateurs. C’est une bonne nouvelle ! Continuons la découverte des itérateurs, je vous garde de belles surprises dans le prochain chapitre !
