Minimisez les appels de votre API grâce aux serializers
Retournez plus d'informations
En l’état, les clients (application front, mobile, etc.) de notre API doivent réaliser plusieurs appels pour obtenir la liste des catégories et la liste des produits qui composent chacune d’entre elles.
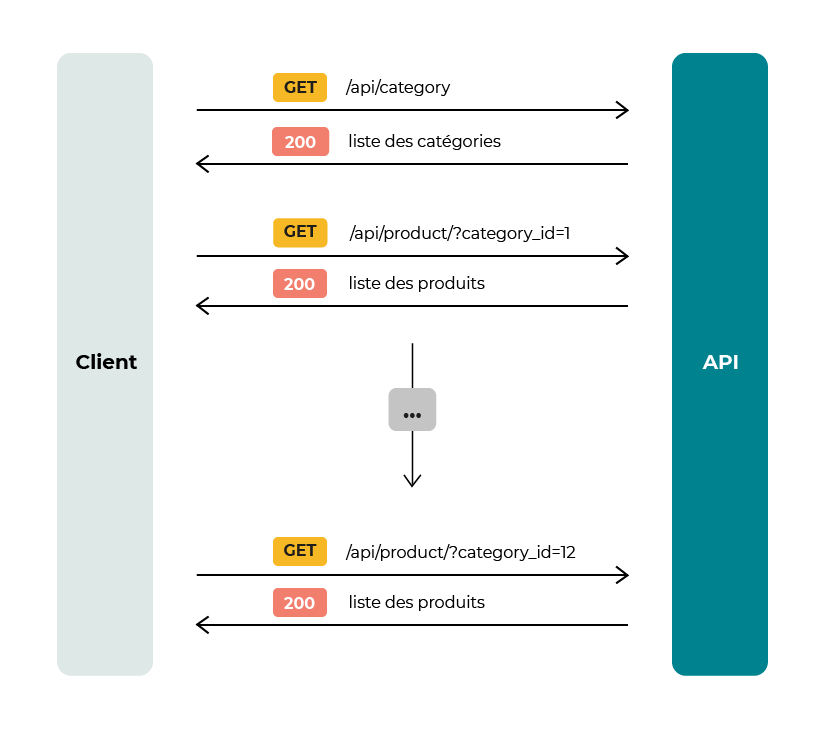
Donc autant d’appels qu’il y a de catégories sont nécessaires, ce qui n’est pas très optimal.
Pour résoudre cette problématique, il est possible d’imbriquer des serializers, afin que le serializer des catégories renvoie directement la liste des produits qui composent la catégorie consultée. Et c’est ce que nous allons voir tout de suite ensemble.
Imbriquez les serializers
Nous allons faire en sorte que notre endpoint de catégorie renvoie également la liste des produits qui le composent. Pour cela, éditons notre serializer de catégorie en ajoutant dans la liste des fields le related_name vers les produits définis dans notre model :
class CategorySerializer(ModelSerializer):
class Meta:
model = Category
fields = ['id', 'date_created', 'date_updated', 'name', 'products']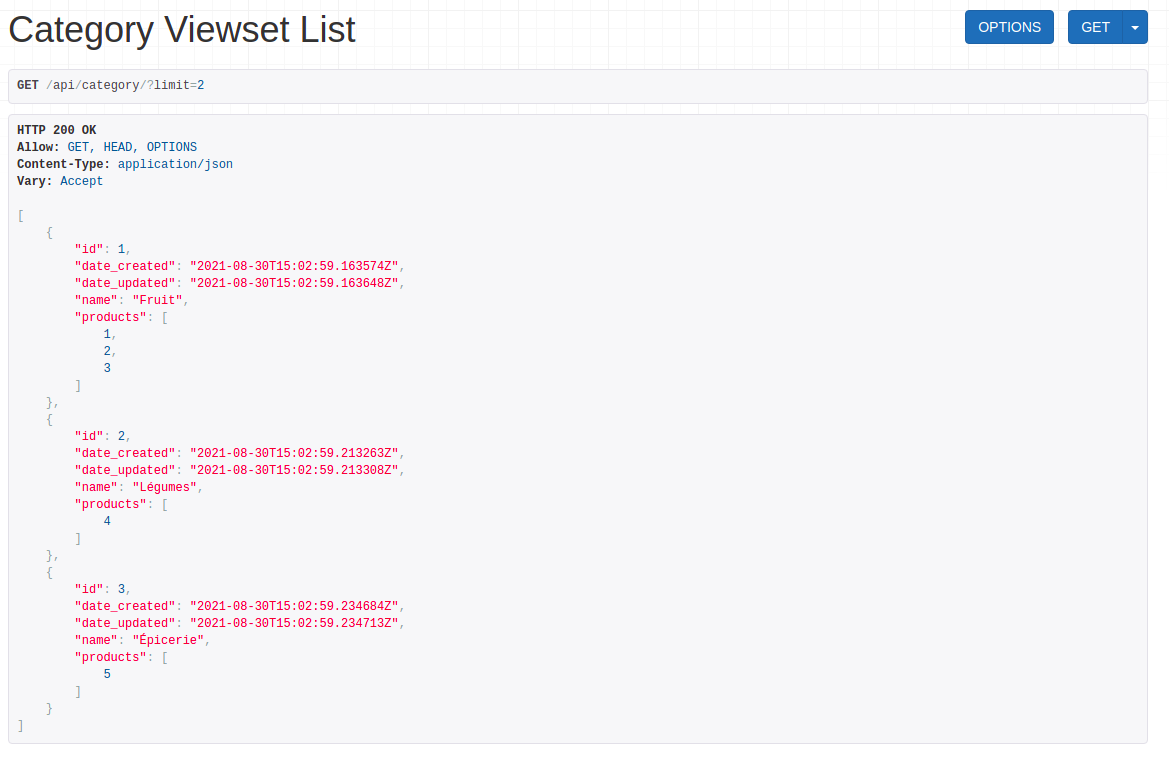
Nous disposons maintenant de tous les identifiants des produits de chaque catégorie, mais ces informations ne sont pas suffisantes pour que les applications clientes les utilisent. Nous pourrions utiliser le serializer de produits pour obtenir des informations plus complètes :
class CategorySerializer(ModelSerializer):
# Nous redéfinissons l'attribut 'product' qui porte le même nom que dans la liste des champs à afficher
# en lui précisant un serializer paramétré à 'many=True' car les produits sont multiples pour une catégorie
products = ProductSerializer(many=True)
class Meta:
model = Category
fields = ['id', 'date_created', 'date_updated', 'name', 'products']Notre retour d'endpoint est bien plus complet à présent, et peut alors être utilisé directement par les clients de notre API.
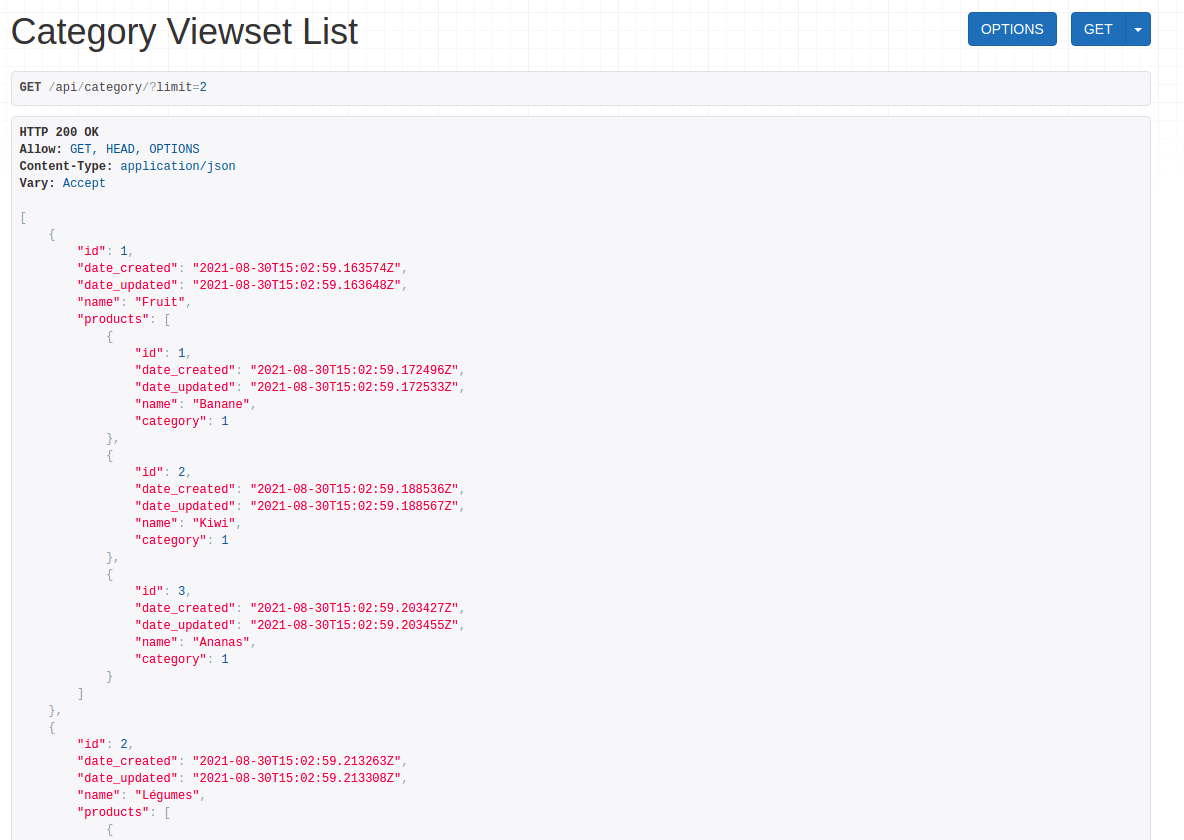
Cependant, un problème persiste, DRF affiche tous les produits de chaque catégorie, alors que nous voudrions n'afficher que ceux qui sont actifs.
Pour cela, nous pouvons redéfinir notre attribut de classe products avec un SerializerMethodField qui nous donne alors la possibilité de filtrer les produits à retourner.
class CategorySerializer(serializers.ModelSerializer):
# En utilisant un `SerializerMethodField', il est nécessaire d'écrire une méthode
# nommée 'get_XXX' où XXX est le nom de l'attribut, ici 'products'
products = serializers.SerializerMethodField()
class Meta:
model = Category
fields = ['id', 'date_created', 'date_updated', 'name', 'products']
def get_products(self, instance):
# Le paramètre 'instance' est l'instance de la catégorie consultée.
# Dans le cas d'une liste, cette méthode est appelée autant de fois qu'il y a
# d'entités dans la liste
# On applique le filtre sur notre queryset pour n'avoir que les produits actifs
queryset = instance.products.filter(active=True)
# Le serializer est créé avec le queryset défini et toujours défini en tant que many=True
serializer = ProductSerializer(queryset, many=True)
# la propriété '.data' est le rendu de notre serializer que nous retournons ici
return serializer.data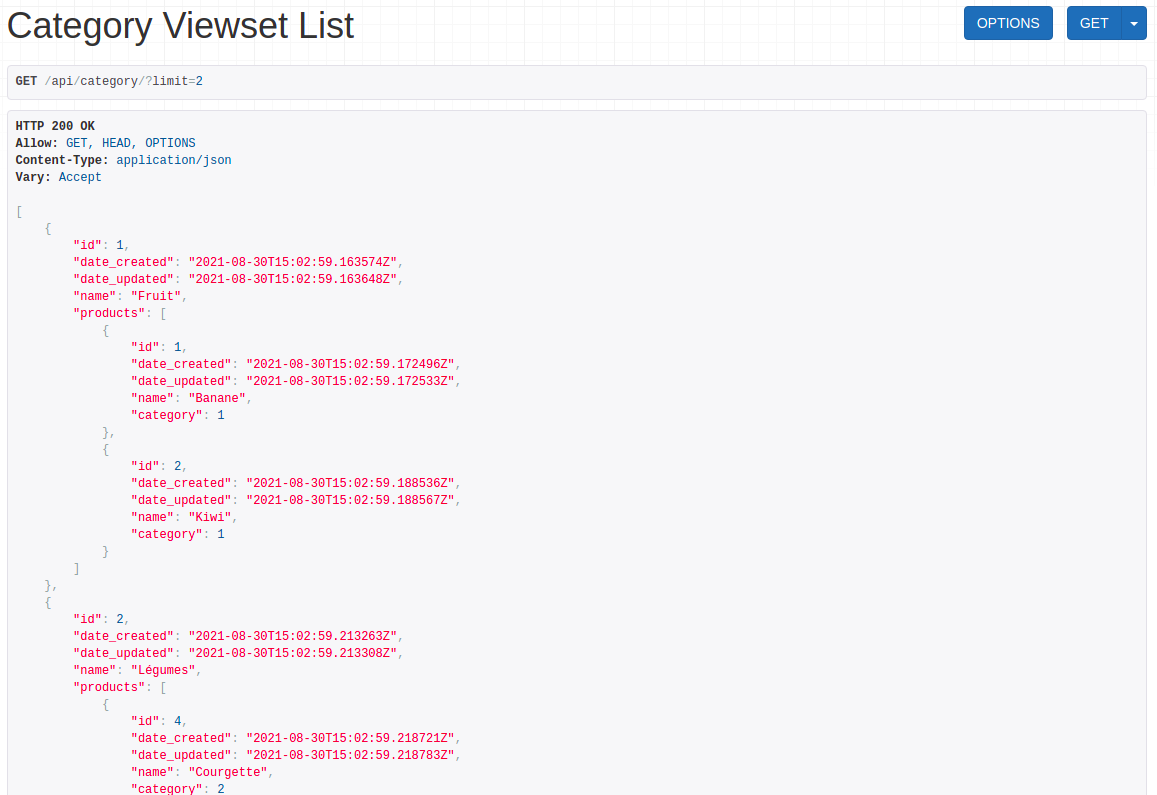
Nous pouvons constater qu'à présent les produits retournés sont bien seulement des produits actifs.
Et si on lançait nos tests après le développement de cette feature ?
Oups, c’est cassé ! Et c’est tout à fait normal.
Une API se doit d’être minutieusement testée, car les retours de ces endpoints sont souvent garants du bon fonctionnement des applications clientes. L’ajout d’un attribut dans un endpoint ne pose en général aucun problème, mais le retrait d’un attribut peut avoir des conséquences plus importantes.
Imaginons que l’application mobile de notre site utilise l’attribut price de nos articles, et que nous décidions de le retirer pour le déplacer ailleurs. Les applications mobiles ne pourraient pas alors afficher de prix tant qu’ils ne déploient pas eux-mêmes une nouvelle version de leur application qui utilise le nouvel attribut.
Mais ça fait beaucoup de données tout ça pour un seul endpoint, non ?
Pour limiter les données retournées, il est possible de mettre en place une pagination. Faisons-le ensemble !
Ajoutez de la pagination
Mettre en place une pagination dès la création d’une API est une bonne pratique, car en limitant le nombre d’entités retournées, cela permet :
De réduire le temps de réponse, surtout si le calcul de certains attributs est coûteux ;
Aux applications clientes de ne pas récupérer toutes les informations si elles ne se servent que d’une seule partie ;
D’éviter la modification des applications clientes par la suite, car la pagination impose certains attributs.
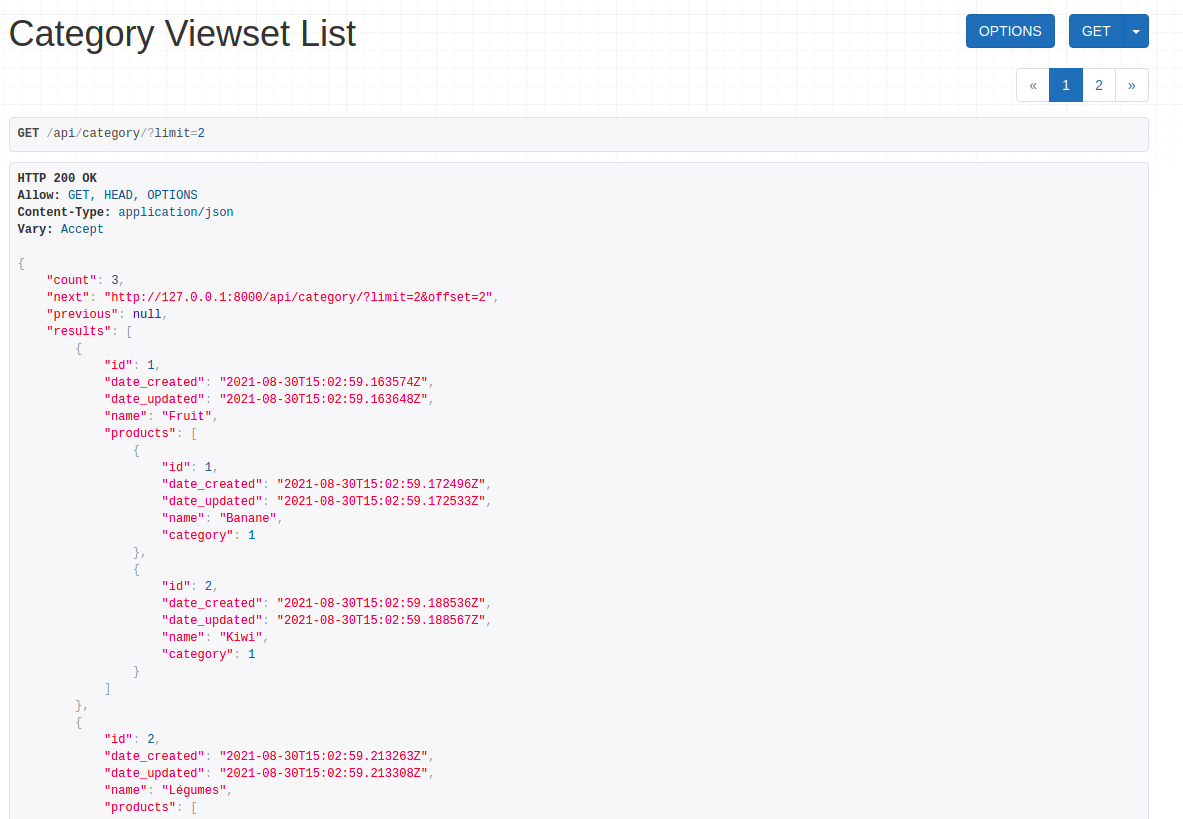
La pagination indique les informations suivantes :
count: le nombre total d’éléments ;next: l’URL de l’endpoint pour obtenir la page suivante ;previous: l’URL de l’endpoint pour obtenir la page précédente ;results: les données réelles utilisables.
Revenons sur l'imbrication et la pagination dans le screencast ci-dessous :
À vous de jouer

Je vous propose de mettre en place le même mécanisme d’imbrication sur le serializer de produits, pour que les applications clientes puissent récupérer d’un coup les produits et leurs articles actifs.
Pour réaliser cela, vous pouvez partir de la branche P2C1_exercice. Elle contient déjà ce que nous venons de faire ensemble.
Une solution est proposée sur la branche P2C1_solution.
En résumé
Imbriquer des serializers permet d’obtenir plus d’informations en un seul appel.
Il est possible d’appliquer des filtres sur un attribut du serializer en utilisant un
SerializerMethodField.Toute modification d’un endpoint entraîne l’adaptation d’un test.
Il est bien de rapidement mettre en place une pagination sur une API.
Maintenant que nous avons optimisé le nombre d’appels de notre API, voyons comment différencier les informations retournées en liste ou en détail – vous me suivez au prochain chapitre ? C’est parti !
