Analysez la corrélation entre deux variables quantitatives
Jusqu'à maintenant, nous avons vu 2 manières de présenter des données en analyse bivariée : le diagramme de dispersion (scatterplot), et le tableau de contingence.
La première est adaptée quand les 2 variables sont quantitatives, et la seconde est adaptée quand les 2 variables sont qualitatives.
Et quand il y a une variable quantitative et une variable qualitative ?
Pas si vite !! Nous aurons l'occasion de voir cela à la fin de cette partie. ;)
Représentez la relation entre deux variables quantitatives
Le diagramme de dispersion
Posons-nous la question suivante :
Êtes-vous moins dépensier lorsque vous avez peu d'argent sur votre compte ?
Vous l'aurez deviné, les 2 variables à étudier sont : montant et solde_avt_operation. Rechercher une corrélation entre ces variables revient à dire : "Sachant que le solde de votre compte est petit, peut-on s'attendre à ce que le montant de l'opération soit lui aussi petit ?" (ou l'inverse).
Je vous invite donc à tracer le diagramme de dispersion entre le solde avant opération et le montant des dépenses, et analyser ce qui en ressort.
Si vous avez correctement réussi à tracer le graphique (pas de panique si ce n'est pas le cas : vous trouverez un exemple de code dans le notebook joint ^^), les points sont assez dispersés et nombreux : il est donc difficile d'y voir très clair. C'est souvent le cas, lorsque l'on travaille avec des jeux de données comportant de nombreux individus. Pour remédier à cela, il existe une représentation qui peut s'avérer plus adéquate.
Une alternative au diagramme de dispersion
Pour avoir une représentation plus efficace que le scatter plot, il est possible d'agréger la variable X en abscisse (axe horizontal) en différentes classes. Cela équivaut à "découper" au couteau le graphique précédent en tranches verticales. On représente ensuite pour chaque tranche une boîte à moustaches calculée à partir de tous les points présents dans la tranche. Voici donc le nouveau graphique obtenu :
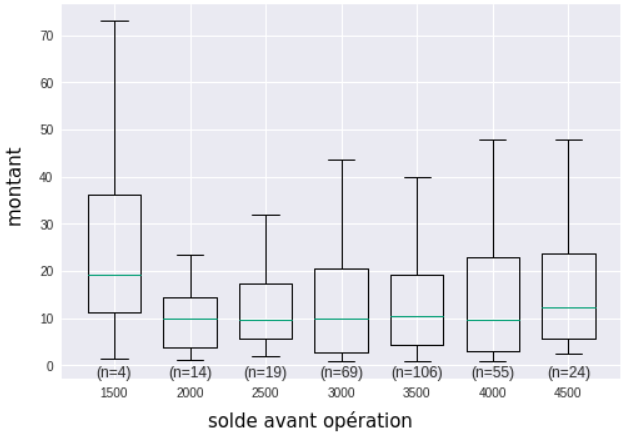
Sur ce graphique, on ne peut pas vraiment dire que plus le solde est petit, plus le montant est petit, même si les boîtes à moustaches des tranches [2000;2500[ et [2500;3000[ semblent légèrement moins dispersées vers le haut. La boîte à moustaches la plus à gauche est très dispersée : cela peut sembler étonnant, mais elle n'est en fait pas très représentative car elle ne représente que 4 individus sur une population qui en contient presque 300. On remarque qu'il est donc important d'afficher les effectifs de chaque classe (n=4, n=14, n=19, etc.).
À vous de jouer

Essayez de retracer ce graphique par vous-même. Ca peut sembler difficile au premier abord, mais procédez par étape :
Il faut tout d'abord discrétiser la variable représentant le solde avant opération. Ici, on procède par tranche de 500 €. Créez dans un premier temps une nouvelle variable au sein de votre dataframe, correspondant à cette discrétisation.
Une fois que cela est fait, il ne reste plus qu'à tracer des boxplots entre notre nouvelle variable et le montant des opérations.
Appréhendez les indicateurs numériques
C'est bien beau les graphiques, mais je sens que vous êtes en manque de calcul ! Il nous faut un indicateur numérique qui puisse nous dire si les variables sont corrélées ou pas.
Ici, on veut savoir si quand on a un solde ( ) petit, on a aussi un montant ( ) petit. Mais petit par rapport à quoi ? Ici, quand on dit "petit", c'est par rapport aux autres valeurs, donc on veut dire "plus petit que la moyenne". Prenons une opération bancaire (= un individu) au hasard, et notons la valeur du solde avant opération, et le montant de l'opération. Pour mesurer si x est plus petit que la moyenne , on peut calculer :
Cette quantité sera négative si x est inférieur à , et positive dans le cas contraire. De même, on peut calculer pour comparer à la moyenne . Maintenant, multiplions-les !
Si est plus petit que la moyenne et que est plus petit que la moyenne, alors les deux termes seront négatifs. Quand on multiplie deux nombres négatifs, on obtient un nombre positif. C'est aussi valable dans l'autre sens : si est supérieur à la moyenne et aussi, alors sera aussi un nombre positif.
OK, avec cette multiplication, on obtient la quantité pour une seule opération bancaire (un seul individu). Mais si les montants sont vraiment petits quand le solde est petit (et inversement), alors les de toutes les opérations seront positifs ! Et si on fait la moyenne de tous ces , alors on obtiendra encore un nombre positif. La moyenne de tous ces s'écrit comme ceci :
Résumons : Si est petit quand est petit (et inversement), alors sera positif. Si et ne sont au contraire pas corrélés, sera plutôt proche de 0. Pour les motivés, vous pouvez aussi déduire que si est grand quand est petit (et inversement), alors sera négatif. Dans ce dernier cas, il y a corrélation certes, mais on dit que c'est une corrélation négative.
La covariance empirique et le coefficient de corrélation
Devinez quoi ! L'indicateur que nous venons de construire est très utilisé en statistiques ; il s'appelle la covariance empirique de X et Y. Ce terme vous rappelle la variance empirique ? C'est normal : elles sont similaires. Effectivement, si vous calculez la covariance empirique de X et X, vous retombez sur la formule de la variance empirique de X, qui s'écrit : . Magique !
Pour ramener la covariance empirique à une valeur qui soit comprise entre -1 et 1, alors on peut la diviser par le produit des écarts-types. Cette normalisation nous permet de faire des comparaisons. Ce qui nous donne :
Ce coefficient r est appelé coefficient de corrélation, ou coefficient de corrélation linéaire, ou encore coefficient de corrélation de Pearson.
Pourquoi "linéaire" ?
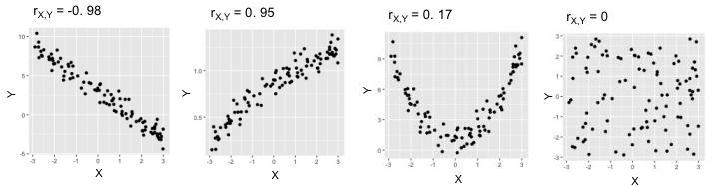
Parce que malheureusement, il ne détecte les relations que lorsqu'elles sont linéaires, c'est-à-dire lorsque les points sont plutôt bien alignés sur une ligne droite. Sur le graphique ci-dessous, les deux schémas du haut montrent des points bien alignés : leur est donc proche de 1 ou de -1. Sur le 4e graphique en revanche, il n'y a pas vraiment de corrélation (connaître la valeur du d'un point ne nous donne aucune indication sur la valeur de ) : est donc proche de 0. Cependant sur le 3e graphique, il y a une forte corrélation, mais sa forme n'est pas linéaire, et est donc malheureusement proche de 0.
Pour calculer le coefficient de Pearson et la covariance, 2 lignes suffisent !
import scipy.stats as st
import numpy as np
print(st.pearsonr(depenses["solde_avt_ope"],-depenses["montant"])[0])
print(np.cov(depenses["solde_avt_ope"],-depenses["montant"],ddof=0)[1,0])Le coefficient de corrélation linéaire se calcule grâce à la méthode st.pearsonr. On lui donne ensuite les 2 variables à étudier.
Un couple de valeurs est renvoyé, le coefficient de corrélation est la premier élément de ce couple, d'où le [0] à la fin de la ligne 4.
La méthode np.cov renvoie la matrice de covariance, que vous n'avez pas à connaître à ce niveau. Cette matrice est en fait un tableau, et dans ce dernier, c'est la valeur située sur la 2e ligne à la 1e colonne, d'où le [1,0].
En résumé
Il est intéressant de faire une représentation graphique pour avoir un aperçu visuel d'une corrélation.
Le graphique le plus adapté dans le cas de deux variables quantitatives est un diagramme de dispersion, qui n'est autre qu'un nuage de points (ou scatter plot, en anglais).
Le coefficient de corrélation de Pearson ou coefficient de corrélation linéaire permet de compléter numériquement l'analyse de la corrélation.
Ce dernier n'est pertinent que pour évaluer une relation linéaire. Il prend des valeurs entre -1 et 1, et le signe du coefficient indique le sens de la relation.
Passons maintenant à l'analyse de deux variables quantitatives par régression linéaire, dans le prochain chapitre !
