Analysez deux variables qualitatives avec le Chi-2
Bon... il ne nous reste plus qu'à étudier le cas de 2 variables qualitatives. Je vous rassure, vous avez déjà fait la moitié du travail dans le chapitre sur le tableau de contingence : si vous avez compris ce principe, c'est déjà très bien.
Définissez quelles questions nous nous posons
La méthode d'analyse sera la même pour répondre à toutes les questions suivantes. La seule chose qui change, ce sont les 2 variables étudiées :
Avez-vous les mêmes catégories de dépenses le week-end et en semaine ? (Variables categ et weekend).
Avez-vous plus d'entrées d'argent en début de mois ou en fin de mois ? (sens et quart_mois).
Vos dépenses sont-elles plus grandes en début de mois qu'en fin de mois ? (tranche_depense et quart_mois).
Le montant d'une opération est-il différent d'une catégorie de dépense à l'autre ? (tranche_depense et categ).
Vos paiements en carte bancaire sont-ils toujours petits, et vos virements importants ? (type et tranche_depense).
Y a-t-il des catégories d'opérations qui arrivent toujours au même moment du mois, comme votre loyer, par exemple ? (categ et quart_mois).
Y a-t-il certaines catégories d'opérations qui s'effectuent toujours selon le même mode de paiement, par exemple par virement bancaire ? (type et categ).
Créez la représentation
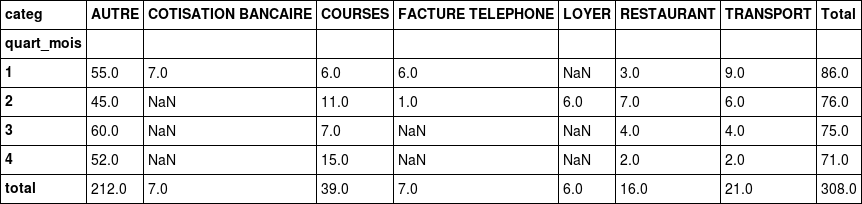
Pour répondre à ces questions, vous pouvez afficher le tableau de contingence comme ceci :
X = "quart_mois"
Y = "categ"
cont = data[[X,Y]].pivot_table(index=X,columns=Y,aggfunc=len,margins=True,margins_name="Total")
contAdaptez les 2 variables qualitatives que vous souhaitez étudier en lignes 1 et 2. Le tableau de contingence se calcule grâce à la méthode pivot_table. Chaque case du tableau de contingence compte un nombre d'individus. Ce comptage se fait grâce à la fonction len.
Appuyez-vous sur des statistiques
Malheureusement, il ne nous sera ici pas possible de proposer un modèle comme dans les 2 derniers chapitres. Mais ce n'est pas grave ! On se rattrapera grâce à une mesure statistique.
Reprenez le chapitre sur le tableau de contingence, et remettez-vous en tête ce petit encadré que nous avions écrit :
Si deux événements et sont indépendants, alors on s'attend à ce que le nombre d'individus qui satisfont à la fois et (appelons ce nombre ) soit égal à (c'est le calcul que vous aviez fait en entrant dans le bar : 30%*10=3). Au contraire, plus sera différent de , plus on aura de raisons de penser que et ne sont pas indépendants.
Étudier une corrélation entre deux variables qualitatives revient donc à comparer les avec les . Les , ce sont les nombres qui sont dans le tableau de contingence (en dehors des 2 ligne et colonne TOTAL). On pourrait donc créer un autre tableau qui aurait la même forme que le tableau de contingence, mais qui contiendrait plutôt les . Voici donc à gauche le tableau de contingence que nous avions, et à droite le tableau des :
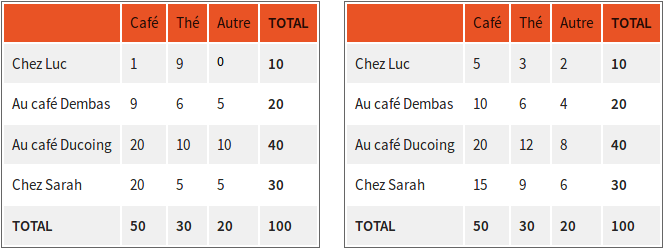
Le tableau de droite est ce à quoi on s'attend en cas d'indépendance des 2 variables. Il nous faudrait donc une statistique qui puisse comparer les valeurs de ces 2 tableaux deux à deux, et qui nous permettrait aussi de trouver les cases pour lesquelles les valeurs sont très différentes. Ces cases seront des valeurs dignes d'intérêt, et qui seront source de non-indépendance des 2 variables.
Allez hop ! Si vous voulez comparer deux nombres, je vous conseille de faire leur différence ! Et pour avoir des différences toujours positives (pour éviter qu'elles ne s'annulent en les sommant), passons-les au carré. Ce n'est pas la première fois que l'on utilise ce petit stratagème :
Oui mais là, si j'ai un et un , l'écart au carré sera de 4. Si j'ai un et un , l'écart au carré sera aussi de 4. Or une erreur de 4 quand vaut 4, c'est une erreur bien plus importante que si .
C'est vrai. On peut alors normaliser cet écart au carré en le divisant par . On obtient donc la formule suivante, en sachant que :
Cette mesure est calculable pour chacune des cases du tableau de contingence. Il peut être intéressant de colorer ce dernier en fonction de cette mesure : foncé quand la mesure est grande, clair quand elle est proche de 0. Ainsi, on détecte facilement les cases qui sont source de non-indépendance : cette représentation s'appelle une carte de chaleur, ou heatmap, en anglais.
Voici le code affichant cette heatmap :
import seaborn as sns
tx = cont.loc[:,["Total"]]
ty = cont.loc[["Total"],:]
n = len(data)
indep = tx.dot(ty) / n
c = cont.fillna(0) # On remplace les valeurs nulles par 0
measure = (c-indep)**2/indep
xi_n = measure.sum().sum()
table = measure/xi_n
sns.heatmap(table.iloc[:-1,:-1],annot=c.iloc[:-1,:-1])
plt.show()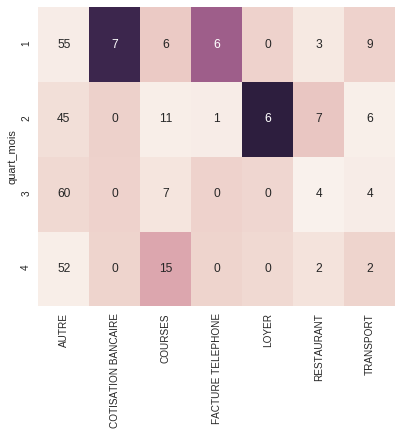
Les lignes 1 à 6 calculent le tableau indep, qui est le tableau représentant le cas d'indépendance. Il fait intervenir le produit matriciel (avec .dot()), que vous n'avez pas à connaître à ce niveau.
En ligne 9, measure contient tous les pour chaque case du tableau. On peut ensuite calculer les contributions (que nous avons définies plus haut) en divisant chaque par (placé dans la variable xi_n). On fait ceci en ligne 11 par measure/xi_n. On obtient ainsi pour chaque case une valeur comprise entre 0 et 1, qui nous sert à étalonner la couleur.
On peut considérer cette valeur comme une contribution à la non-indépendance. Elle est optionnellement exprimable en pourcentage si on la multiplie par 100. Plus cette contribution sera proche de 100 %, plus la case en question sera source de non-indépendance. La somme de toutes les contributions vaut 100 %.
Enfin, si on somme toutes ces mesures pour chaque case du tableau (de la colonne j=1 à la colonne j=l, puis de la ligne i=1 à la ligne i=k), on obtient la statistique ( se prononce "xi"):
Normalement, on applique à cette mesure un seuil au-delà duquel on dira que les 2 variables sont corrélées. C'est un peu compliqué, mais pour en savoir plus, vous pouvez regarder ce document. Retenons juste ici que plus est grand, moins l'hypothèse d'indépendance est valide.
En fait, il existe des seuils que l'on peut calculer. En dessous du seuil, on dira "Les variables ne sont pas corrélées", et au-dessus, on dira l'inverse.
C'est bien plus pratique ! Mais pour être tout à fait précis, il faut donner une précision supplémentaire, qui est une sorte de "niveau de certitude", que l'on appelle seuil de significativité. On utilise pour cela la p-value, exprimée en pourcentage.
C'est grâce à elle que l'on peut dire si un test statistique est significatif ou pas.
En résumé
Dans le cas de l'analyse des corrélations entre deux variables qualitatives, on optera pour un tableau de contingence, plutôt qu'une représentation graphique.
Il est cependant possible de faire apparaître sur ce tableau les cases participant le plus à une possible corrélation, via une carte de chaleur ou heatmap.
La mesure que l'on fait alors apparaître sur chaque case d'une heatmap est une mesure de contribution à la non-indépendance, qui prend des valeurs entre 0 et 1.
À partir de toutes ces contributions, on peut calculer le coefficient de chi2.
Bravo à vous – vous avez terminé le dernier chapitre du cours ! Validez une dernière fois vos acquis avec le quiz.
