Appréhendez les mesures de forme
Bon, votre ami vous a donné la moyenne des temps de trajet, ainsi que l’écart-type. Vous êtes déjà plus serein. Mais... il y a quelque chose que vous n'avez pas prévu. Regardez ces 2 distributions :
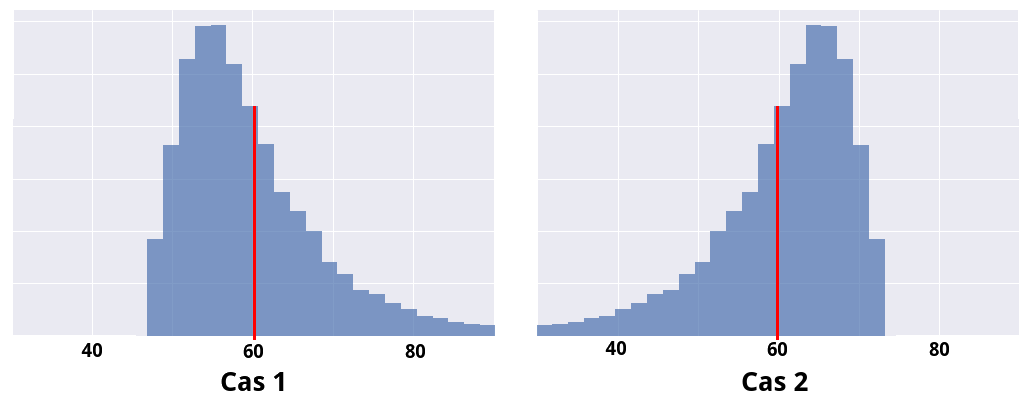
Elles ont la même moyenne empirique (60 minutes), et le même écart-type. Cependant, le cas 1 est plus "risqué" que le cas 2. En effet, dans le cas 2, il est très peu probable que votre trajet dure plus de 75 minutes : pas de risque d'être en retard ! Par contre, dans le cas 1, il est tout à fait possible que votre trajet dure 80 minutes, ou même beaucoup plus.
Il y a des mesures statistiques pour cela ! On les appelle les mesures de forme.
Réfléchissons
Construisons notre propre indicateur de forme ! Nous souhaitons savoir si la distribution s'étale plutôt à gauche ou à droite de la moyenne.
Je vous propose de reprendre celui que nous avons construit au chapitre précédent. Au départ, nous avions eu cette idée :
Prenons toutes nos valeurs, et calculons pour chacune d'entre elles l'écart qu'elles ont avec la moyenne. Puis additionnons tous ces écarts !
L'écart entre une valeur et la moyenne, nous l'avons écrit . Si cet écart est positif, cela signifie que est supérieur à la moyenne, s'il est négatif, est inférieur à la moyenne.
En additionnant tous ces écarts, nous nous sommes aperçus que la somme valait toujours 0. Nous avons donc mis cette quantité au carré : . Avec le carré, cette grandeur est toujours positive. Si elle est toujours positive, on perd l'information qui nous dit si est supérieur ou inférieur à la moyenne. Or ici, nous voulons garder cette information !
Bon, si le carré ne convient pas, mettons-la au cube pour voir !
Bien vu ! Quand on met l'écart au cube, on obtient . Contrairement au carré, le cube conserve le signe de . Ensuite, prenons la moyenne de tous ces écarts au cube, on obtient :
Nous avons atteint notre objectif : cette grandeur sera négative si la majorité des valeurs est plus petite que la moyenne, et positive sinon !
Mais nous pouvons faire encore mieux. Regardez ces deux distributions :
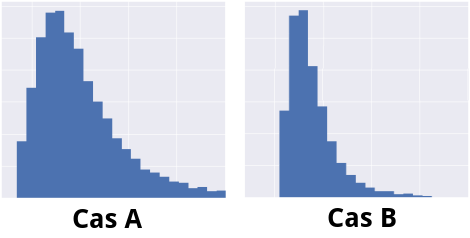
Elles ont la même forme, mais pas le même écart-type (la distribution A est plus étendue que B, A a un écart-type 2 fois supérieur à B). Comme elles ont la même forme, on voudrait que notre indicateur donne la même valeur pour ces deux distributions.
Mais actuellement, ce n'est pas le cas. Dans le cas A, les écarts à la moyenne sont 2 fois plus importants que dans le cas B. Comme on met ces écarts au cube, notre indicateur sera donc fois plus grand pour A que pour B. Or nous les souhaitons égaux. Pour corriger cela, il faut annuler l'effet de l'écart-type. On va donc diviser notre indicateur par l'écart-type mis au cube :
Découvrez les mesures de forme
Le Skewness empirique
Devinez quoi ! L'indicateur que nous venons de créer est utilisé par les statisticiens, et s'appelle le skewness empirique. En général, on a l'habitude de nommer le skewness , et son numérateur :
avec
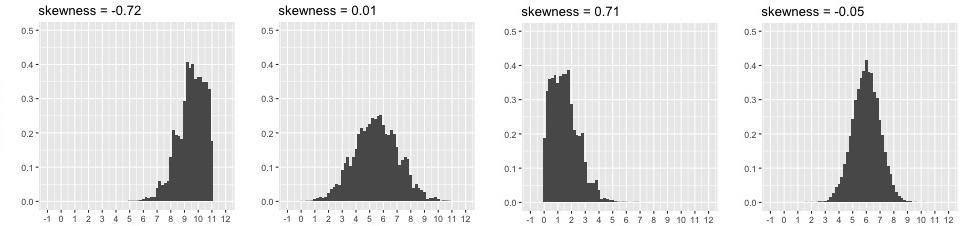
Le skewness est une mesure d'asymétrie. L’asymétrie d’une distribution traduit la régularité (ou non) avec laquelle les observations se répartissent autour de la valeur centrale. On interprète cette mesure de cette manière :
Si alors la distribution est symétrique.
Si alors la distribution est étalée à droite.
Si alors la distribution est étalée à gauche.
Le calcul du skewness se fait très facilement en Python. Voici un exemple avec la variable montant de notre jeu de données de transactions bancaires :
data['montant'].skew()Le Kurtosis empirique
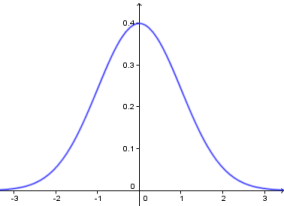
Le kurtosis empirique n'est pas une mesure d'asymétrie, mais c'est une mesure d'aplatissement. L’aplatissement peut s’interpréter à la condition que la distribution soit symétrique. En fait, on compare l'aplatissement par rapport à la distribution la plus célèbre, appelée distribution normale (parfois "courbe de Gauss" ou "Gaussienne"). Vous l'avez probablement déjà vue, elle ressemble à cela :
Le kurtosis est souvent noté , et se calcule par :
avec
Voilà comment calculer le kurtosis de notre variable montant :
data['montant'].kurtosis()Il s’interprète comme ceci :
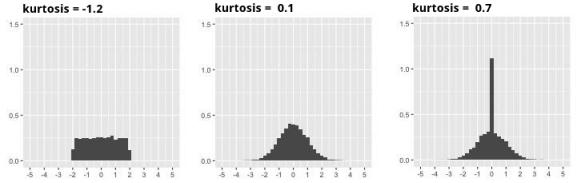
Si , alors la distribution a le même aplatissement que la distribution normale.
Si , alors elle est moins aplatie que la distribution normale : les observations sont plus concentrées.
Si , alors les observations sont moins concentrées : la distribution est plus aplatie.
À vous de jouer

Poussez encore votre analyse un peu plus loin ! Ajoutez le calcul du Skewness empirique et le Kurtosis empirique pour chaque catégorie.
En résumé
Les mesures de forme sont des mesures permettant de déterminer si la majeure partie des valeurs est plus petite ou plus grande que la moyenne.
Le skewness est une mesure d'asymétrie, qui correspond à l'étude de la régularité (ou non) avec laquelle les observations se répartissent autour de la valeur centrale.
Le kurtosis empirique est une mesure d'aplatissement de la distribution, comparativement à l'aplatissement d'une distribution normale.
Dans le prochain chapitre, nous verrons une dernière mesure : les mesures de concentration. Allez, c'est parti !
