Créez votre premier data frame avec Pandas
Préparez votre jeu de données
Comme nous avons pu le voir, les arrays NumPy sont particulièrement efficaces pour traiter des valeurs numériques. Mais les données, dans la réalité, ne sont pas composées uniquement de chiffres et de nombres.
En effet, on retrouve aussi :
des catégories ;
des labels ;
des dates ;
du texte brut.
De plus, ces données ont généralement un format prédéfini en analyse de données, où chaque ligne va correspondre à un individu (au sens statistique du terme), et chaque colonne va être une caractéristique spécifique des individus. C’est ce que l’on appelle une variable.
Voici quelques exemples pour illustrer cela :
dans le milieu automobile, chaque individu sera une voiture, et on pourra avoir comme caractéristiques la puissance du moteur, les dimensions du véhicule, la marque, le modèle, la couleur, etc. ;
dans une étude de grande distribution, chaque individu pourra être un produit sur lequel on aurait plusieurs informations (le prix, la catégorie, etc.) ;
dans le milieu bancaire enfin, chaque individu sera une personne, sur laquelle on aurait enregistré le salaire moyen, le genre, ses mensualités de remboursement de prêt, etc. ;
Voilà par exemple à quoi pourrait ressembler ce dernier cas :

En explicitant le format des données, vous avez peut-être eu l’image d’un fichier Excel, et c’est une bonne idée ! Excel est encore pour beaucoup d’entreprises un format très utilisé pour stocker et déplacer des données. Mais ce n’est pas le seul, les données peuvent être stockées sous bien des formats différents.
Par exemple, on retrouve régulièrement des fichiers texte ou des fichiers CSV (pour comma-separated values). Ce sont simplement des fichiers contenant l’ensemble des données brutes, séparées par un délimiteur.
Voici un exemple avec un jeu de données automobiles, dont le délimiteur est le point-virgule :
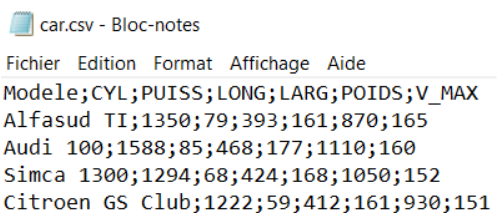
Cela peut également être sous la forme de fichier JSON. Le JavaScript Object Notation (JSON) est un format standard utilisé pour représenter des données structurées. Cela ressemble à un gros dictionnaire Python pouvant contenir lui-même d’autres dictionnaires et/ou listes. C’est une description un peu “réductrice”, mais une image vaut mieux que mille mots :
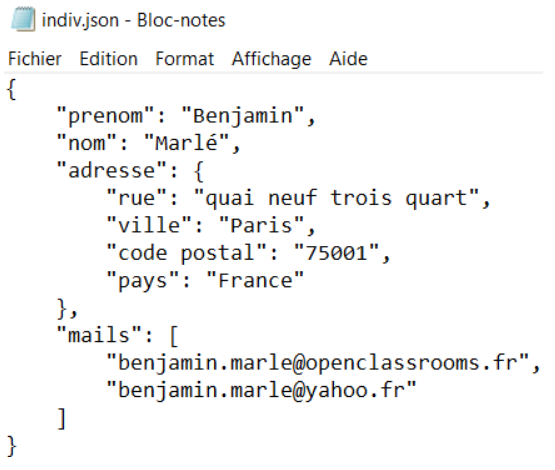
Nous n’aurons malheureusement pas l’occasion d'approfondir le format JSON dans le cadre de ce cours, mais il existe de nombreuses ressources qui traitent le sujet en détail. Le JSON est un format très standard dans le monde informatique !
Nous cherchons donc un outil qui nous permette de représenter les données avec le format souhaité (individus/variables), de manipuler différents types de données, et de lire les données provenant de différentes sources. Cet outil n’est autre que la librairie Pandas, et plus particulièrement les objets data frame.
Le data frame est un objet Python permettant de représenter les données sous forme de tableau, où chaque colonne est explicitement nommée. Il reprend les mêmes paradigmes que l’array NumPy : chaque colonne peut naturellement être d’un type différent, mais une colonne ne peut contenir qu’un seul type ! Cette organisation simplifie l’accès aux variables, et permet de nombreuses manipulations de données plus ou moins complexes.
Mais du coup, quel est l’intérêt de la librairie NumPy si Pandas permet de faire tout cela ?
Excellente question ! Vous verrez au fur et à mesure de ce cours, et plus globalement de vos futures analyses de données, que vous serez régulièrement amené à jongler entre les deux. Il est assez courant que certaines méthodes appliquées à des data frames retournent des arrays, et qu’on ait besoin de retransformer ces arrays en data frames à postériori. C’est pourquoi il est nécessaire de maîtriser les deux librairies, pour être parfaitement armé avant de plonger dans une analyse de données.
En parlant de plonger, que diriez-vous de créer votre premier data frame ?
Générez votre premier data frame
Nous allons créer notre premier data frame à partir des formats cités ci-dessus ; et comme lorsqu’on aime, on ne compte pas… je vous propose d’importer le même jeu de données… sous 3 formats différents : format Excel, format CSV et format JSON.
Vous trouverez les trois fichiers dans ce dossier compressé. Passons à présent à la pratique :
Une fois le data frame importé, commence alors le travail principal d’un analyste de données : la manipulation de données. Et avant toute manipulation, il est nécessaire de connaître son jeu de données.
Identifiez les caractéristiques de votre data frame
Pandas met à disposition plusieurs méthodes pour pouvoir faire cela de façon efficace.
Aperçu du data frame
Comme présenté ci-dessus, un bon réflexe à adopter après l’importation, et après toute transformation importante, est de visualiser le jeu de données, ou du moins quelques lignes, afin de vérifier que tout s’est correctement déroulé.
Pour cela, il existe deux méthodes principales :
la méthode
.head()permettant de sélectionner par défaut les 5 premières lignes du data frame. Il est possible de préciser entre parenthèses le nombre de lignes à afficher ;la méthode
.tail()permettant de sélectionner par défaut les 5 dernières lignes du data frame. Il est également possible de préciser entre parenthèses le nombre de lignes à afficher.
Voici quelques exemples :
# chargement du fichier
import pandas as pd
data = pd.read_csv("clients.csv")# afficher les 5 premières lignes
display(data.head())# afficher les 2 dernières lignes
display(data.tail(2))# afficher les 5 premières et dernières lignes
display(data)On peut aussi accéder facilement aux caractéristiques globales d’un data frame.
Caractéristiques globales du data frame
Lorsqu’on parle de caractéristiques globales, il est question ici des attributs, des informations générales qu’on retrouve sur tous les data frames, et dont on aura besoin régulièrement.
En premier lieu viennent les dimensions d’un data frame. Combien de lignes comportent un data frame ? Et combien de colonnes ? Tout comme avec les arrays NumPy, il est possible de répondre à ces questions via l’attribut .shape :
data.shapeLe résultat sera un tuple. Sa lecture est relativement simple : le premier élément correspond au nombre de lignes, et le second au nombre de colonnes. On peut naturellement stocker le résultat de cet attribut dans une variable pour réutiliser ces éléments ultérieurement :
dim = data.shape
print(dim[0]) # 228
print(dim[1]) # 4Au-delà des dimensions, on peut avoir envie de connaître les types de chacune de nos variables. On peut accéder à cela très simplement à partir de l’attribut .dtypes :
data.dtypesVous devriez avoir l’affichage suivant :

Bien qu’avec un affichage un peu austère, cela permet d’avoir facilement le type de chaque variable de notre data frame.
Enfin, nous avons évoqué précédemment le lien qui peut exister entre Pandas et NumPy. Je vous propose dès à présent de matérialiser ce lien en transformant notre data frame en array :
clients_array = data.values
display(clients_array)Et tada ! Aussi simplement que cela, nous avons à présent un array NumPy en lieu et place de notre data frame.
En résumé
En analyse de données, les données sont généralement représentées et manipulées sous un format de tableau, où chaque ligne représente un individu, et chaque colonne une variable.
Le data frame de Pandas propose une implémentation de ce format en Python.
Les formats de stockage des données sont multiples : cela peut être via des fichiers délimités (CSV ou texte), ou encore des fichiers JSON ou Excel.
L’objet data frame de Pandas permet de manipuler simplement et efficacement les données :
en important très facilement tous ces différents formats ;
en accédant facilement aux caractéristiques générales de notre jeu de données, comme les types de variables, le nombre de lignes, le nombre de colonnes, etc.
Maintenant que nous sommes au point sur les informations générales d’un data frame, il est à présent temps de découvrir un peu plus en détail ce que Pandas nous permet de faire en termes de manipulation de data frame.
