Maîtrisez les solutions pour les traitements par lots

Pour améliorer la rentabilité d’un site web, les traitements par lots (batch) sont très utilisés pour analyser le parcours utilisateur grâce aux données des pages consultées et des cliques boutons. Voyons les services proposés par AWS répondant à ce besoin.
Elastic MapReduce (EMR)
Ci-dessous l’architecture d’un cluster EMR :
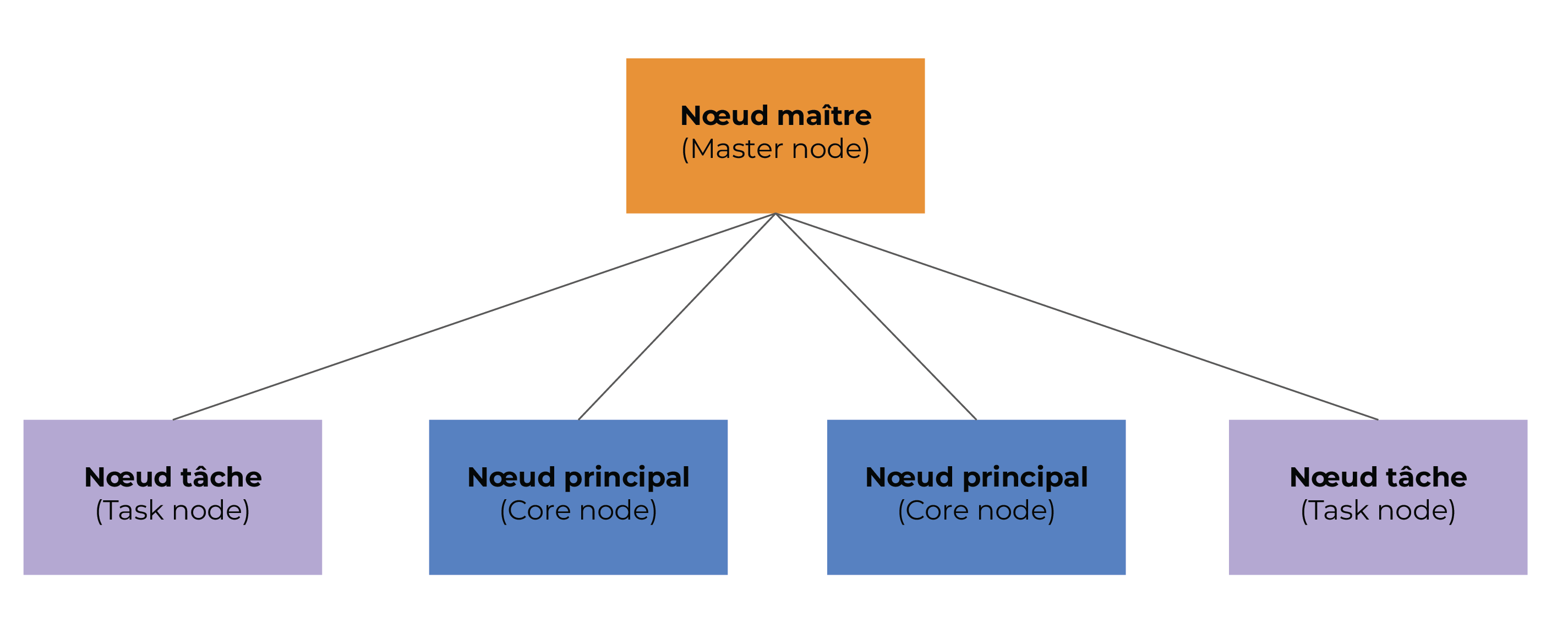
Noeud maître:
Orchestre le cluster
Tarification à utiliser : instances réservées
Noeud tâche:
Exécute uniquement des tâches
Tarification à utiliser : instances Spot
Noeud principal:
Exécute des tâches et stocke les données
Tarification à utiliser : instances réservées
AWS Glue
Quelques exemples de transformation :
Convertir vos données aux formats Big Data : Parquet ou Avro.
Calculer le nombre de clics par utilisateur.
Glue est composé de plusieurs modules (Data Crawler, Data Catalog) avec des fonctions précises comme présentées dans l’image suivante :
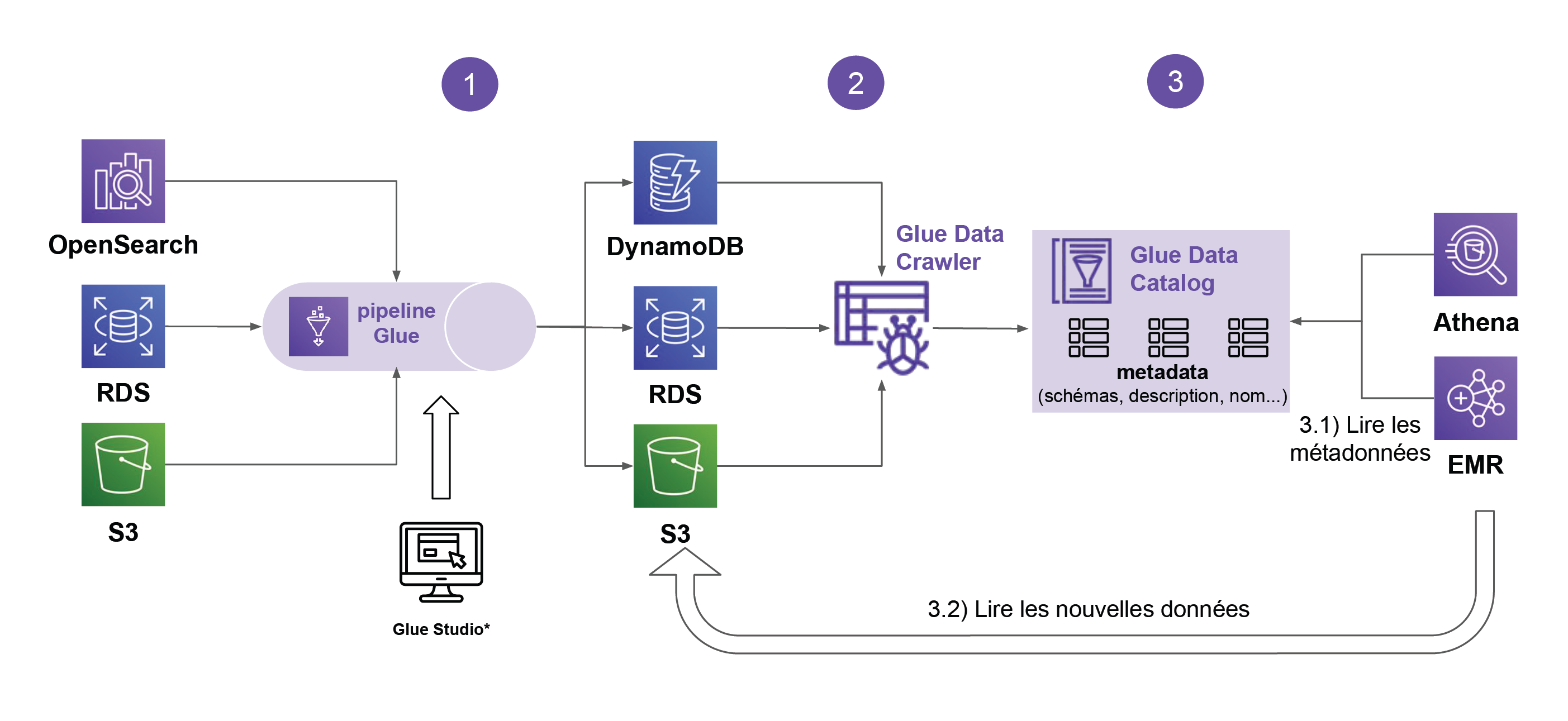
1 - Un pipeline Glue exécute un traitement et le résultat est stocké dans des systèmes de stockage. Avec l’option signets de tâche (job bookmarks), les données déjà traitées ne le sont pas de nouveau. L’option Elastic Views permet de créer des vues croisées.
2 - Le Data Crawler scanne les différents systèmes de stockage pour extraire les métadonnées (metadata) des nouvelles données : l’emplacement de chaque fichier, les noms et types des colonnes des tables, etc.
Les métadonnées sont stockées dans le Data Catalog.3 - Avec différents outils analytics, vous pouvez accéder aux nouvelles données grâce aux métadonnées stockées dans le Data Catalog.
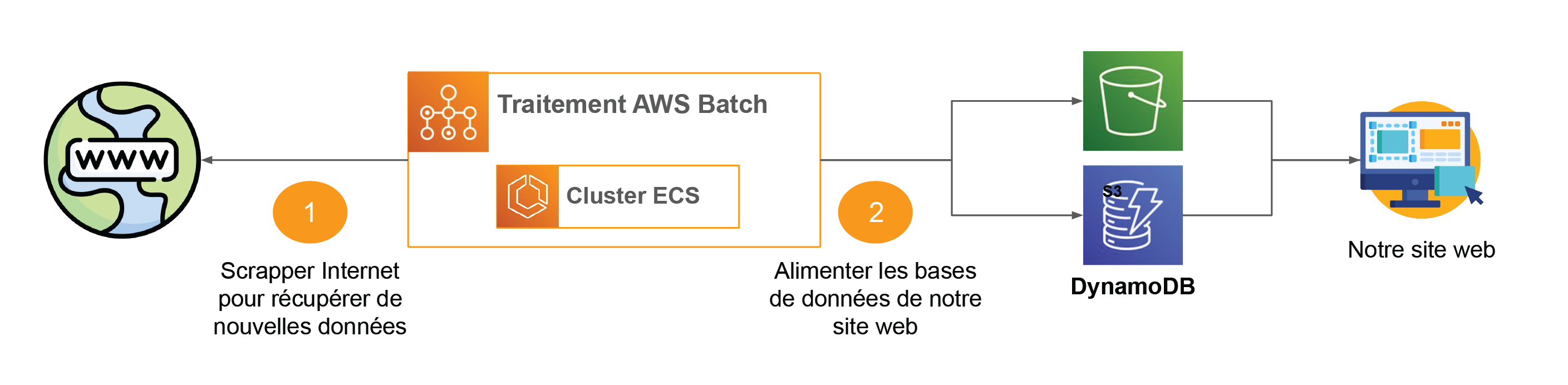
AWS Batch
Un traitement AWS Batch a besoin d’une image Docker pour être exécuté sur ECS. Ce service est idéal pour optimiser vos coûts, car vous choisissez le type d’infrastructure selon vos besoins (Fargate, EC2 ou instances Spot) et il alloue dynamiquement les ressources nécessaires (CPU, mémoire) à vos tâches.
Les services AWS de Machine Learning
Si vous souhaitez appliquer des algorithmes de Machine Learning (apprentissage automatique) à vos données pour faire, par exemple, de la recommandation personnalisée à vos abonnés, le tableau suivant répertorie les services proposés par AWS.
Services | Description |
Amazon SageMaker | plateforme offrant des services pour réaliser et déployer des modèles de machine learning |
Amazon Comprehend | exécute des traitements du langage naturel (NLP) |
Amazon Forecast | fait de la prédiction de séries temporelles basée sur le machine learning |
Amazon Fraud Detector | identifie les activités potentiellement frauduleuses en ligne |
Amazon Kendra | recherche des données non structurées et structurées à l'aide du NLP |
Amazon Lex | crée des interfaces conversationnelles (chatbots) |
Amazon Polly | transforme un texte en paroles réalistes |
Amazon Rekognition | permet la reconnaissance d'image |
Amazon Textract | extrait du texte et des données de documents |
Amazon Transcribe | transforme un audio en texte (pour les sous-titres) |
Amazon Translate | réalise des traductions |
En résumé
Le service EMR vous fournit des clusters Hadoop dans lesquels vous exécutez des applications Big Data.
Le service sans serveur Glue vous permet de construire des pipelines ETL (extraction, transformation, chargement) sans vous soucier de l’architecture.
Le service AWS Batch vous permet d’exécuter plusieurs centaines de milliers de tâches de calcul par batch sur AWS.
AWS fournit une suite de services pour l’apprentissage automatique dont le principal est Amazon SageMaker.
Pour la suite, voyons comment stocker les commentaires des lecteurs dans une base de données !
