Prenez en main une base de données
Initiez-vous au SGBDR
Concrètement, une BDD stockée sur un ordinateur, ça a quelle forme ?
Le plus souvent, une base de données est tout simplement composée d'un ou plusieurs fichiers, dans lesquels sont écrites toutes les données, un peu comme un fichier texte ou un fichier de tableur.
Certains programmes informatiques enregistrent leurs données dans leurs propres fichiers. Lorsque ces données sont peu nombreuses et peu complexes, alors cela fonctionne très bien. Cependant, dès que les données se complexifient, alors ce système n'est plus du tout optimal.
Par exemple, lorsque les données doivent être partagées par plusieurs applications, il faut que ces applications se « mettent d'accord » sur la manière de représenter les données dans les fichiers. C'est couramment le cas dans les entreprises, où les données sont souvent utilisées par plusieurs logiciels : les données des ventes de produits sont par exemple utilisées par le logiciel du service Comptabilité. Ou encore les logiciels qui reportent, sous forme de graphiques, toutes les données clients utiles au service Marketing. Et si chaque logiciel lit et écrit des données de manière différente dans les mêmes fichiers, bonjour le bazar !
Aussi, plus la quantité de données est importante, plus l'accès ou la modification de données est long. En effet, il faut trouver dans de très gros (ou nombreux) fichiers, l'endroit exact où se trouve la donnée recherchée.
Pour faciliter cela, il existe beaucoup de méthodes d'optimisation permettant de réduire le temps d'accès à l'information.
Seulement voilà, utiliser toutes ces méthodes d'optimisation, c'est tout un art, et c'est complexe. Quand un développeur code un programme, il n'a pas le temps – voire pas les compétences – pour programmer toute cette optimisation.
C'est pour cela qu'ont été créés les systèmes de gestion de bases de données (SGBD). Le SGBD, c'est un intermédiaire entre le programme et les données. Chaque SGBD utilise un langage afin de communiquer avec les applications qui souhaitent accéder aux données.
Les SGBD qui gèrent des bases de données relationnelles sont appelés systèmes de gestion de bases de données relationnelles, donc SGBDR. Les plus utilisés sont PostgreSQL, Oracle, MySQL, SQLite, etc. Le langage le plus utilisé par les SGBDR est le langage SQL (structured query language). C'est celui auquel vous allez vous former tout au long de ce cours !
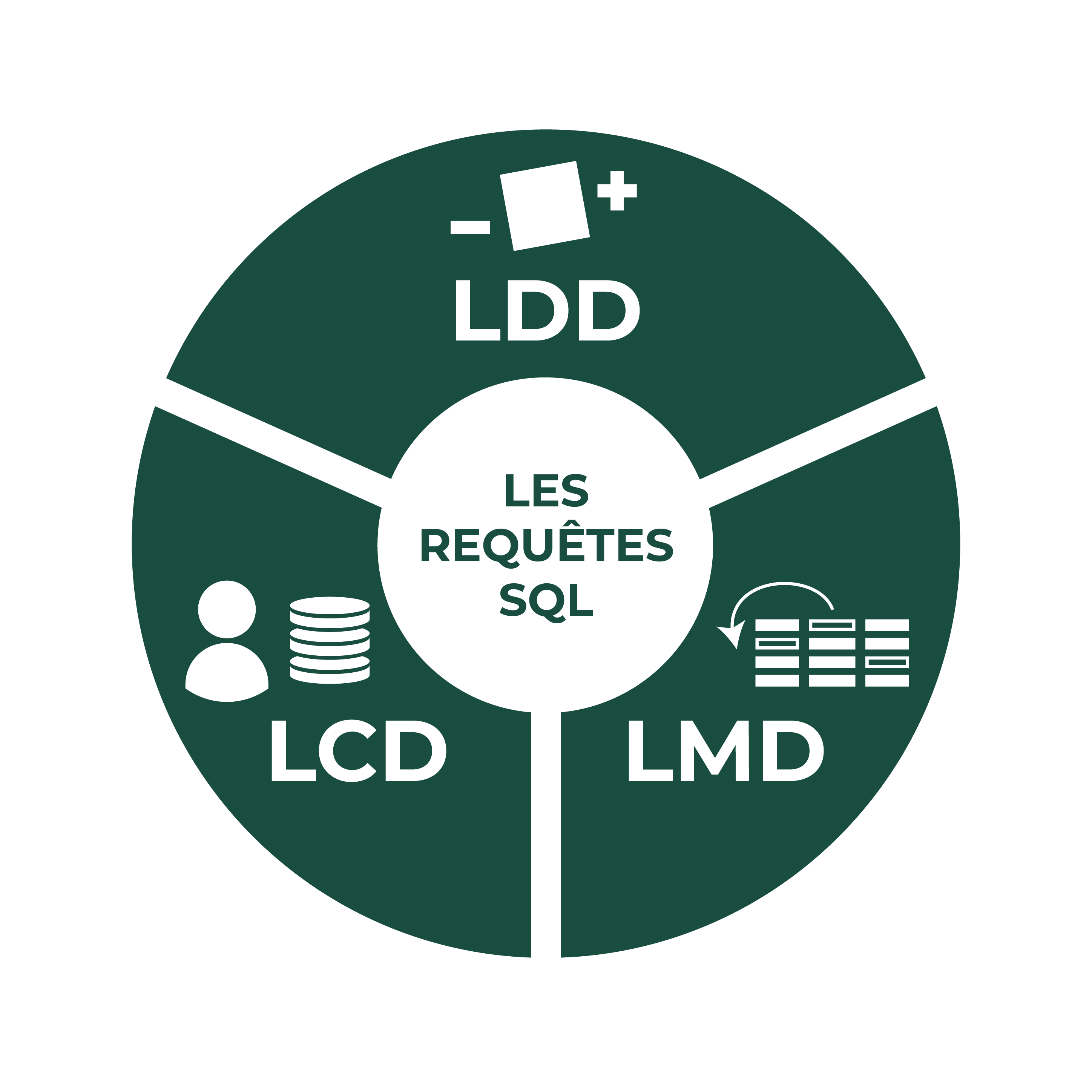
Parler en langage SQL, c'est formuler des requêtes à la base de données. Une requête peut avoir plusieurs buts : accéder à une donnée, ajouter une donnée, modifier la structure des tables, etc. Les requêtes se répartissent en 3 groupes :
le LDD (langage de définition de données) destiné à créer ou supprimer des objets dans la base de données (tables, contraintes, etc.) ;
le LCD (langage de contrôle de données) qui gère les utilisateurs d'une base de données ainsi que leurs droits sur les objets (droit de consultation, de modification etc.) ;
le LMD (langage de manipulation de données) destiné à manipuler les données contenues dans les tables, c'est-à-dire à manipuler les lignes de celles-ci. Les 4 opérations possibles sont :
la création de lignes,
la lecture de lignes,
l'actualisation de lignes,
la suppression de lignes.
Nous supposons donc que la base de données est déjà construite et déjà remplie. Ce qui nous intéresse ici, c'est d'aller fouiller dans les données pour y trouver ce qui nous intéresse. En effet, tout au long de ce cours, vous allez mener l'enquête !
Installez votre première base de données
Tout au long du cours, vous allez vous mettre dans la peau d'un data journaliste qui enquête sur le financement d'un réseau criminel.
Vous utiliserez pour votre enquête la base de données des Panama Papers, qui sont des données initialement secrètes, mais qui ont été révélées par vos collègues journalistes d'investigation.
Découvrez l'architecture de votre base de données
Vous avez, au cours de votre enquête, intercepté une facture émise par une mystérieuse société (c'est-à-dire une entreprise) qui s'appelle « Big Data Crunchers Limited ». Sur ces factures, l'adresse de la société n'est pas indiquée.
Vous ne savez pas qui se cache derrière cette mystérieuse entreprise, mais vous pensez qu'il peut s'agir d'une société-écran.
Dans votre base de données, la liste des sociétés (dont certaines sont des sociétés-écrans) se trouve dans la table entity , (ce qui signifie « entité », en français).
Souvent, les sociétés-écrans sont domiciliées dans des paradis fiscaux, qui sont des pays (ou plus précisément des juridictions) souvent caractérisés par une forte opacité sur les données bancaires, et/ou par des taux de taxation sur les sociétés très bas.
La personne à qui reviennent réellement les bénéfices d'une société s'appelle le ou la bénéficiaire.
Votre base de données contient un bon nombre de ces bénéficiaires, qui sont contenus dans la table officer .
Mais une société ne se crée pas si facilement que ça. En général, il faut demander de l'aide à des services spécialisés. On les appelle souvent des intermédiaires, qui sont principalement des cabinets d'avocats, des banques ou des personnes. Ils se trouvent dans la table intermediary .
Vous allez donc enquêter sur la mystérieuse société Big Data Crunchers Ltd, mais également sur les intermédiaires qui ont aidé à la créer. Afin de rédiger votre article, vous regarderez si ces intermédiaires ont une grosse activité dans des paradis fiscaux, ce qui pourrait vous mener sur la piste d'un réseau de blanchiment d'argent.
Créez votre première table
Dans la vidéo qui suit, je vous propose de créer votre première table.
Voici la requête utilisée dans la vidéo. Elle est destinée à créer la table entity2 (car la table entity existe déjà dans la base) :
CREATE TABLE entity2 (
id INTEGER,
name TEXT NOT NULL,
jurisdiction TEXT,
jurisdiction_description TEXT,
incorporation_date DATE,
status TEXT,
service_provider TEXT,
id_address INTEGER,
source TEXT,
note TEXT,
end_date DATE,
url TEXT,
lifetime INTEGER,
PRIMARY KEY(id)
) Ajout de données dans la table entity2 :
INSERT INTO
entity2 (id, name, jurisdiction, jurisdiction_description, incorporation_date)
VALUES
(1, 'Une société', 'IMG', 'Le Pays Imaginaire', '2024-01-01'),
(2, 'Une autre société', 'IMG', 'Le Pays Imaginaire', '2025-01-01'),
(3, 'Encore une société', 'IMG', 'Le Pays Imaginaire', '2026-01-01');À vous de jouer

Contexte
La personne qui vous a fourni la fameuse facture émise par la société Big Data Crunchers Limited (on appellera cette personne votre “source” ; elle souhaite rester anonyme), travaille dans une entreprise. Mais cette entreprise est bien réelle : elle a de vrais bâtiments, des salariés en chair et en os ; bref, ce n'est pas une société-écran. Cette entreprise est mentionnée comme cliente de la facture sur laquelle vous enquêtez. En plus de cette facture, votre source vous a aussi secrètement fourni la liste des employés sous forme d'une table, que nous appellerons ici la table personne .
Consignes
Voici sur cette illustration la table personne que vous souhaitez stocker dans votre base.
nom | prenom | telephone_professionnel | numero_bureau | identifiant | departement |
Dom | Malika | 01 29 38 ** 01 | 27 | 2893 | ressources humaines |
Dirichlet | John | 01 29 38 ** 02 | 01 | 2983 | marketing |
Hati | Hassia | 01 29 38 ** 03 | 12 | 1829 | marketing |
Bernard | George | null | 51 | 2993 | maintenant |
Créez la requête SQL qui créera la structure de cette table (juste la structure, pas besoin d'y insérer les données).
Vérifiez votre travail
Il y a plusieurs solutions possibles. Je vous en donne une un peu plus bas. Mais pour vérifier si votre réponse est bonne, il vous suffit d'exécuter ces 2 requêtes (l'une après l'autre). Si la 2nde requête affiche les mêmes données que l'illustration de la table donnée ci-dessus, alors vous avez bon !
INSERT INTO personne (nom, prenom, telephone_professionnel, numero_bureau, identifiant, departement)
VALUES
('Dom','Malika','01 29 38 ** 01', 27, 2893,'ressources humaines'),
('Dirichlet','John','01 29 38 ** 02',01,2983,'marketing'),
('Hati','Hassia','01 29 38 ** 03',12,1829,'marketing'),
('Bernard','George', NULL, 51, 2993, 'maintenance')SELECT * FROM personneVoici une réponse possible :
CREATE TABLE personne (
nom TEXT,
prenom TEXT,
telephone_professionnel TEXT,
numero_bureau INTEGER,
identifiant INTEGER,
departement TEXT,
PRIMARY KEY(identifiant)
)En résumé
Un SGBD est un programme qui fait l'intermédiaire entre le programme / l'application et les données, à l'aide d'un langage prédéfini, comme le SQL, par exemple.
Le SGBD est spécialisé dans le stockage de données, et optimise les accès en lecture et en écriture.
On communique avec le SGBDR avec des requêtes SQL.
On crée une table avec
CREATE TABLE.On insère des données grâce à
INSERT INTO (...) VALUES (...).
Vous en savez un peu plus sur l'utilisation du SGBD pour naviguer dans votre base de données. Dans le prochain chapitre, nous verrons comment utiliser la clé primaire pour identifier les lignes de votre table.
