Liez des tables avec une jointure interne
Nous poursuivons ici notre enquête, en essayant de construire une table qui contienne à la fois les infos des sociétés, et celles sur les adresses qui correspondent à ces sociétés. Ce que l'on veut faire, ça s'appelle une jointure.
Mais nous irons même plus loin : nous chercherons également les intermédiaires qui ont aidé à créer Big Data Crunchers Ltd.
Découvrez la jointure interne
Dans cette vidéo, vous découvrirez le concept de jointure, et en quoi elle va vous être utile dans notre enquête :
Quel objectif cherchons-nous à atteindre avec une jointure interne ?
Rappelez-vous : chaque société de entity a une adresse. Les adresses se trouvent dans la table address .
Le lien entre les 2 tables se fait grâce à une clé étrangère dans entity , la colonne entity.id_address , qui fait référence à la clé primaire address.id_address .
Voici la table entity et sa clé étrangère :
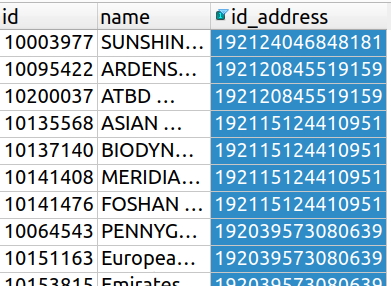
Et ensuite la table address et sa clé primaire :

Cette clé étrangère nous permet de connaître l'adresse de chaque société. Eh bien, c'est cette clé étrangère qui va nous permettre de rassembler dans une même table les sociétés et leurs adresses !
Avant la jointure :
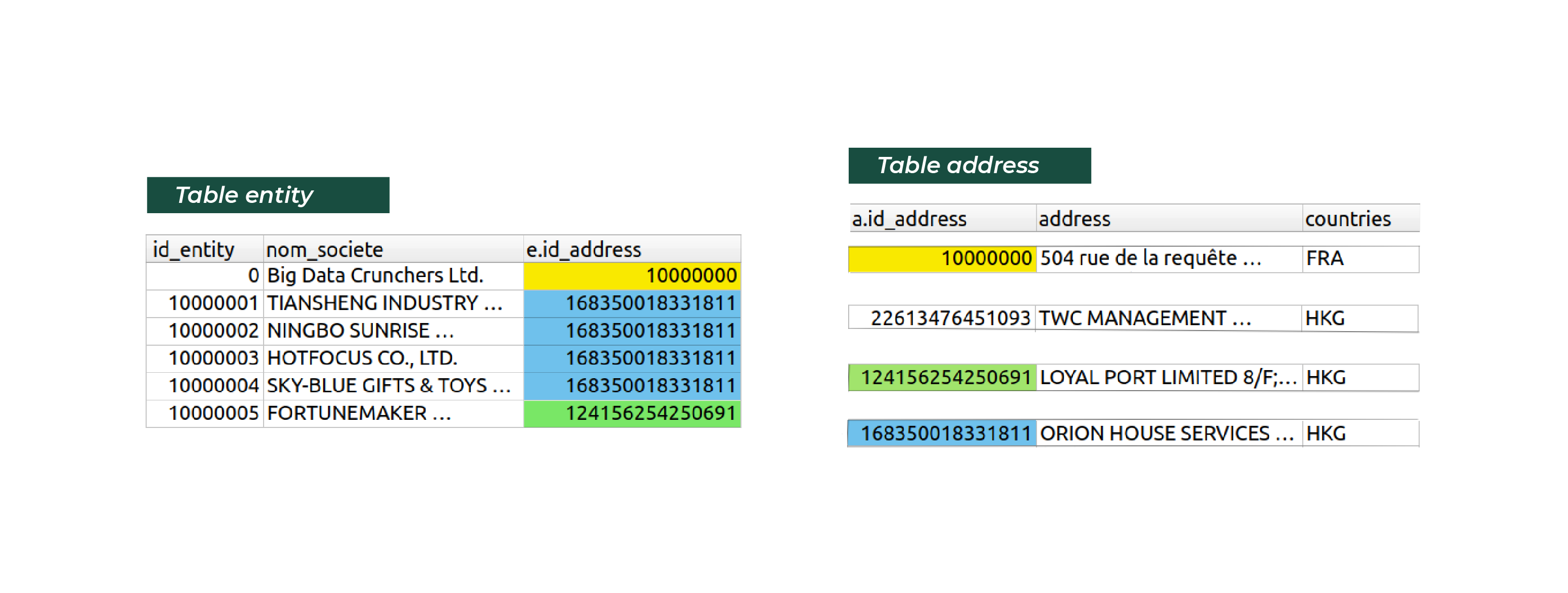
Après la jointure :

On remarque ici que quand on fait correspondre les lignes des 2 tables, pour une ligne donnée la valeur de entity.id_address est égale à la valeur de address.id_address . Ça paraît logique, mais c'est LE détail qui va tout changer pour ce qui suit.
Au chapitre précédent, on avait commencé le travail en faisant un produit cartésien entre entity et address , mais on s'est retrouvés avec une table à 4 milliards de lignes : c'est beaucoup trop !
Voici un aperçu de ces premières lignes, obtenues avec la requête suivante :
SELECT
e.id AS id_entity,
e.name AS nom_societe,
e.id_address AS 'e.id_address',
a.id_address AS 'a.id_address',
a.address,
a.countries
FROM
entity e, address a ;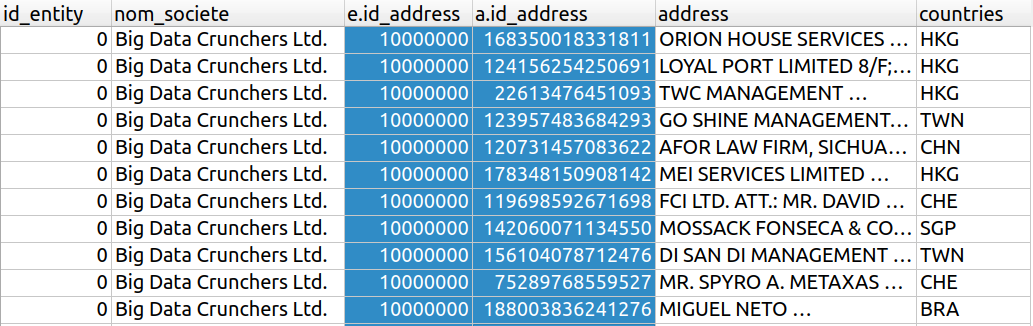
Mais ! Il y a quelque chose qui cloche : les colonnes entity.id_addressetaddress.id_address ne sont pas égales !
Effectivement ! Souvenez-vous, comme il s'agit d'un produit cartésien, on a associé toutes les lignes de entity à toutes les lignes de address , sans nous soucier si les adresses correspondent bien aux sociétés ! On a donc beaucoup de lignes totalement inutiles !
Pour remédier à cela, on va filtrer les lignes inutiles.
Filtrer… donc avec un WHERE ?
Oui, tout à fait !
On va simplement enlever toutes les lignes pour lesquelles entity.id_address n'est pas égal à address.id_address . Notre condition de filtrage sera donc e.id_address = a.id_address .
SELECT
e.id AS id_entity,
e.name AS nom_societe,
e.id_address AS 'e.id_address',
a.id_address AS 'a.id_address',
a.address,
a.countries
FROM
entity e, address a
WHERE
e.id_address = a.id_address ;
Et voilà le résultat ! Notre jointure interne est faite !
La plupart du temps, la condition de jointure fait intervenir la clé étrangère de la 1e table avec la clé primaire de la 2e table. C'est le cas ici.
Vérifiez si le nombre de lignes a bien diminué
Maintenant, réfléchissons au nombre de lignes renvoyées par notre jointure.
Lors du produit cartésien, le nombre de lignes était de :
nombre_lignes_entity x nombre_lignes_address = 215896 x 19805 = 4 milliards environ
Mais après le filtrage, on aura forcément moins de lignes.
Premièrement, chaque ligne de entity possède une adresse au maximum, ou plus précisément un identifiant d'adresse. Par exemple, Big Data Crunchers Ltd a pour identifiant d'adresse 10000000.
Deuxièmement, dans la table
address, il n'y a qu'un seul identifiant par adresse (c'est logique, c'est la clé primaire !).Donc on en conclut que le résultat de la jointure interne aura au maximum autant de lignes qu'il y a de lignes dans entity !
On passe donc de 4 milliards de lignes à 215 896 (maximum), pas mal, non ?
Pourquoi “maximum” ?
Parce que l'adresse de certaines sociétés est inconnue, mais patience, on en parle au chapitre suivant.
Découvrez l'autre syntaxe de la jointure interne
Pour réaliser une jointure, il y a une 2e syntaxe possible, avec les mots clés JOIN et ON :
SELECT *
FROM entity
JOIN address ON entity.id_address = address.id_address ;On peut d'ailleurs inverser entity et address , le résultat sera identique :
SELECT *
FROM address
JOIN entity ON entity.id_address = address.id_address ;Effectuez une jointure sur plusieurs colonnes
Vous vous souvenez qu'une clé primaire peut être composée de plusieurs colonnes ! Si c'est le cas, alors une clé étrangère qui référence cette clé primaire sera forcément composée d'autant de colonnes. Dans ce cas, il sera nécessaire d'effectuer une jointure sur plusieurs colonnes (allez, disons 2 colonnes pour cet exemple). La condition de jointure sera de cette forme :
table1.colonne_fk_1 = table2.colonne_pk_1 AND table1.colonne_fk_2 = table2.colonne_pk_2
-- Première syntaxe :
SELECT * FROM t1, t2 WHERE (t1.fk1 = t2.pk1 AND t1.fk2 = t2.pk2);-- Seconde syntaxe :
SELECT * FROM t1 JOIN t2 ON (t1.fk1 = t2.pk1 AND t1.fk2 = t2.pk2);Ajoutez une condition dans le WHERE
Nous avons atteint notre objectif : coller nos deux tables. Dans le résultat, il nous faut maintenant retrouver Big Data Crunchers Ltd. Pour cela, une petite restriction s'impose. On l'ajoute dans le WHERE. Comme il y a déjà une condition, on utilise AND :
SELECT *
FROM entity, address
WHERE entity.id_address = address.id_address
AND entity.name = 'Big Data Crunchers Ltd.';
Voici le résultat, où on voit enfin l'adresse de notre mystérieuse société apparaître !
Mettez en place une jointure interne avec une table d'association
Retrouvons maintenant les intermédiaires qui ont participé à la création de la société Big Data Crunchers Ltd !
Précédemment, nous avons vu qu'une table d'association sert à modéliser une association de type plusieurs à plusieurs entre deux objets. C'est le cas du lien qui unit entity et intermediary , car plusieurs intermédiaires peuvent créer une société, et un intermédiaire peut créer plusieurs sociétés. Ainsi, il y a une table qui porte le nom de assoc_inter_entity , contenant entre autres :
une colonne
entity, clé étrangère qui référence la tableentity;une colonne
intermediary, clé étrangère qui référence la tableintermediary.
Il nous faut donc faire une jointure sur 3 tables, comme ceci :
SELECT
i.id as intermediary_id,
i.name as intermediary_name,
e.id as entity_id,
e.name as entity_name,
e.status as entity_status
FROM
entity e,
assoc_inter_entity a,
intermediary i
WHERE
e.id = a.entity
AND a.inter = i.id
AND e.name = 'Big Data Crunchers Ltd.' ;Nous avons spécifié les 3 tables dans le FROM. Dans le WHERE, nous donnons les deux conditions de jointure, ainsi que le nom de notre société.
Voilà, vous savez maintenant faire une (double) jointure avec une table d'association. Retenez bien cette requête, elle nous servira de base pour tous les chapitres suivants !
À vous de jouer

Contexte
Votre BDD contient certains des bénéficiaires des sociétés-écrans. Un bénéficiaire, c’est une personne à qui reviennent réellement les bénéfices d'une société. Ces bénéficiaires se trouvent dans la table officer . Cette table peut aussi contenir d’autres personnes liées à la société en question.
Consignes
Les tables officer et entity sont liées par une table d’association appelée assoc_officer_entity .
Grâce à une jointure entre ces 3 tables, et à un filtrage sur le nom de la société, trouvez le nom des 2 personnes liées à la société Big Data Crunchers.
Vérifiez votre travail
La jointure s’effectue grâce aux 2 premières conditions placées dans le WHERE, et le filtrage grâce à e.name = "Big Data Crunchers Ltd." .
SELECT
*
FROM
entity e,
assoc_officer_entity a,
officer o
WHERE
a.entity = e.id AND
a.officer = o.id AND
e.name = "Big Data Crunchers Ltd."En résumé
Une jointure regroupe les lignes de deux tables selon une certaine condition de jointure.
Une jointure est la succession d'un produit cartésien et d'un filtrage sur la condition de jointure.
La plupart du temps, la condition de jointure fait intervenir la clé étrangère de la 1e table avec la clé primaire de la 2e table.
Il y a deux syntaxes pour effectuer une jointure :
avec FROM et WHERE ;
avec JOIN et ON.
Lorsque nous avons affaire à une table d'association, alors il faut joindre 3 tables entre elles, c'est-à-dire faire 2 jointures dans une même requête SQL. Cette double jointure a donc 2 conditions de jointure.
Quand la clé primaire et la clé étrangère contiennent chacune plus d'une colonne, la condition de jointure doit combiner ces colonnes avec un
AND.
Vous maîtrisez maintenant la jointure interne ! Bravo, c'est un élément essentiel en SQL. Mais… vous pourriez avoir des surprises dans certains cas : en effet, vous pourriez voir certaines lignes disparaître après votre jointure. Nous allons voir cela au chapitre suivant !
