Optimisez la pertinence de vos alertes et l’efficacité de vos processus
Vous avez mis en place la détection et vous avez traité plusieurs incidents. Mais les cyberattaques évoluent vite… et votre organisation aussi !
Votre troisième mission est donc de participer à l’évolution du SOC et de l’améliorer en continu.
Nous allons voir dans cette partie comment prendre en compte les retours faits dans la partie précédente à la fin des incidents.
Pour commencer, voyons comment agir sur les processus pour gagner du temps.
Comprenez les enjeux de l’amélioration continue dans un SOC
Pourquoi l’amélioration continue ? Si le SOC est bien conçu, il n’y a pas besoin de le réinventer ?
En fait, même dans un SOC mature, il y a toujours des problèmes à corriger.
Dans le SI que vous cherchez à protéger, il y a en permanence des évolutions : déploiement de nouvelles solutions, déploiement de nouvelles machines, de nouveaux services, etc. Toutes ces solutions doivent être suivies par la sécurité et potentiellement intégrées au périmètre surveillé par le SOC.
En particulier, la surface d’attaque évolue constamment. Non seulement parce que votre périmètre évolue, mais aussi parce que le temps introduit constamment de nouvelles vulnérabilités que les attaquants peuvent exploiter.
Sans compter que les attaquants aussi évoluent, et trouvent constamment de nouvelles techniques. À vous de vous adapter et de suivre ces évolutions !
Au-delà des évolutions du contexte, la détection et la réponse ne sont jamais des processus achevés. Il y a forcément des erreurs à éviter et des faux positifs qui reviennent en permanence.
Toutes ces contraintes peuvent être compliquées à gérer si le SOC ne s’adapte pas.
En fait, l’amélioration continue est une de vos missions principales. Et c’est notamment en étant proactif dans l’amélioration du SOC que vous allez éviter de vous démobiliser.
Réduisez le nombre de faux positifs
Le premier problème à prendre à bras-le-corps est la quantité de faux positifs.
Les faux positifs consomment littéralement l’énergie du SOC pour rien. Ils sont donc les premiers montrés du doigt en matière d’alert fatigue.
Il faut donc les détecter… et les traiter.
Détecter et traiter… ce sont les missions du SOC ?
Exactement. C’est pour cette raison que l'amélioration de la détection doit se faire en continu au sein même du cycle de réponse aux incidents !
Dans la partie précédente, nous avions expliqué qu’il y avait trois sorties possibles de qualification :
l’alerte est un faux positif ;
l’alerte doit être investiguée ;
l’alerte est déjà investiguée.
En fait, on peut ajouter une autre possibilité : l’investigation qui est lancée répond soit à un incident, soit à un besoin d’amélioration de la détection.
À ce moment-là, l’alerte suit un schéma de réponse similaire à celui d’un incident :
On crée une investigation dans le SOAR.
On investigue sur les causes de ce défaut de détection.
On prévoit un plan d’action dans le SIRP ou le SOAR.
Si nécessaire, on communique aux équipes concernées à l’aide du SIRP.
On prend les actions pour remédier à ce défaut.
On clôture les tickets et l’investigation, et on débriefe.
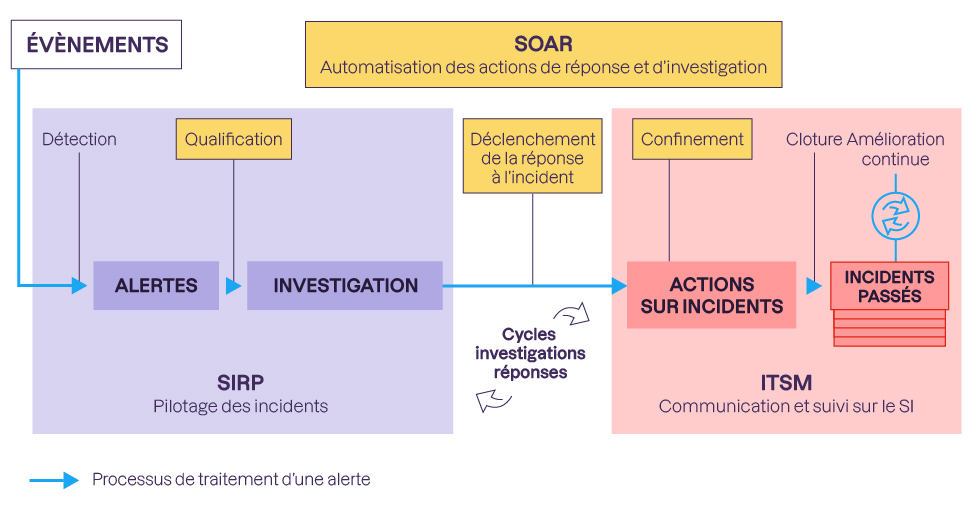
Dans la pratique, les actions pour améliorer la détection doivent être attribuées à un responsable, suivies et communiquées aux équipes métiers concernées. La différence avec un incident est que ce processus n’est pas contraint par des impératifs d’urgence, et qu’il n’y a pas d’étape de confinement.
Cela vous permet de vous débarrasser des faux positifs et de suivre ce processus d’amélioration.
Documentez vos modes opératoires
En plus de la détection, vous pouvez aussi améliorer la réponse à incident.
Lorsque vous êtes face à un incident critique, qu’il est urgent de confiner, vous n’avez pas de temps à perdre à vous poser trop de questions. Surtout si les réponses existent déjà au sein du SOC !
Pour cela, mettez en place des fiches réflexes pour réagir aux différentes situations. Par exemple :
Mails de phishing : des mails de phishing arrivent en permanence. Vous n’avez pas le temps de vous poser des questions pour traiter chaque mail ! Avoir une procédure claire vous permettra de gagner du temps (si ce n’est pas automatisé !). Il faut supprimer le mail, vérifier si un mail similaire a été reçu par d’autres collaborateurs, identifier les utilisateurs qui l’ont reçu, éventuellement forcer le changement du mot de passe ou investiguer sur les machines de ces utilisateurs s’il s’agit de phishing par pièce jointe malveillante, et noter toutes ces actions effectuées.
Compromission d’une machine : si un poste est compromis, soit on le traite, soit c’est l’attaquant qui le traite à sa façon. Là non plus donc, pas le temps de trop réfléchir à ce qu’il faut faire. Il faut déconnecter la machine, la mettre de côté pour éventuellement investiguer ou récupérer des données, et noter toutes les actions faites.
Compromission d’un serveur applicatif ou d’une base de données : si la machine est compromise, il faut la mettre en quarantaine. Mais certains serveurs peuvent avoir une marche à suivre spécifique en fonction de la criticité de leur activité ou de leur données. Anticiper ces cas de figure et avoir une procédure claire vous permettront de savoir tout de suite quels sont les actifs qui doivent être traités différemment.
Attaque par rançongiciel : dans le cas d’un rançongiciel avéré qui se propage, chaque seconde compte ! Vous devez avoir un bouton d’urgence pour déconnecter au minimum ce qui est compromis. Vous n’avez pas le temps de vous demander où est le bouton !
D’où l’importance d’anticiper et de prévoir ces fiches réflexes.
Automatisez vos processus autant que possible
Vous pouvez même aller plus loin pour gagner du temps pendant les investigations, en automatisant tout ce qui est répétitif dans vos procédures.
Par exemple, la procédure concernant les mails de phishing indique toujours les mêmes actions. C’est quelque chose que l’on peut automatiser avec des scripts sur mesure !
C’est notamment le rôle du SOAR. Pour rappel, cela signifie Security Orchestration, Automation and Response, il y a donc bien une composante d’automatisation ! L’avantage de centraliser l’automatisation dans le SOAR, qui est la plateforme de travail centrale du SOC, est que vous automatisez au plus près de vos processus.
Parmi les outils SOAR les plus répandus, on peut citer TheHive, Cortex, Splunk et Shuffle.
Vous pouvez aussi utiliser des outils d’orchestration et d’automatisation qui ne sont pas réservés à la sécurité, tels que N8N, Tines ou Node-RED.
Par exemple, vous pouvez automatiser :
la création de l’incident dans le SIRP dès que le statut de l’investigation passe à “incident avéré”. Cela vous permet notamment d’attribuer automatiquement les investigations ;
l’enrichissement automatique des alertes. Par exemple, ajouter automatiquement à l’alerte ou l’investigation le pays des adresses IP identifiées ;
la mise en quarantaine d’une machine, que vous pouvez déclencher dès que l’investigation confirme que la machine est compromise ;
le blocage d’un sous-réseau que vous pouvez déclencher si une attaque de grande ampleur est en cours de propagation (comme un ransomware).
Dans la pratique, vous devrez définir des modules d’automatisation, parfois appelés “playbooks” ou “responders”. Soit ils peuvent être appelés à la main, soit vous pouvez définir un élément déclencheur, par exemple “Créer une investigation” ou “Passer l’investigation en mode incident”.
Cela vous permettra de gagner de précieuses minutes dans des situations qui ont lieu fréquemment, ou au contraire dans des situations d’urgence !
Soyez prêt à utiliser des outils de circonstance
Pour gagner du temps dans ces situations d’urgence, vous devez aussi être prêt à les affronter. Cela veut dire avoir les bons outils, prêts à l’emploi !
Dans les retours du PIR, vous pouvez avoir identifié qu'il vous manquait des outils pour automatiser certaines investigations, pour automatiser des actions de réponse, mais aussi pour rechercher des informations pertinentes ou pour échanger avec les bonnes personnes.
Dans les parties précédentes, l’outil qui nous a été le plus important pour réagir aux situations de crise est l’EDR. Il vous sert de “tour de contrôle” de circonstance, et vous permet d’investiguer et de réagir rapidement sur un grand nombre de machines.
Si votre organisation est déjà équipée d’un EDR, soyez prêt à le déployer rapidement sur un nouveau périmètre pour réagir à une situation d’urgence. Si vous ne pouvez pas le faire, des outils peuvent vous servir d’EDR de circonstance : Velociraptor, Google Rapid Response (GRR) ou DFIR ORC (créé par l’ANSSI).
En résumé
La dernière mission du SOC est d’être constamment en train de s’améliorer.
Un SOC qui ne met pas en place de processus d’amélioration continue risque de se démobiliser face à des alertes répétitives, des attaquants qui s'adaptent et un SI qui évolue : c’est l‘“alert fatigue”.
Un premier point à améliorer est de réduire le nombre de faux positifs. C’est un des problèmes les plus courants du SOC, car ces faux positifs consomment inutilement des ressources et fatiguent les équipes !
Utilisez au maximum votre SOAR (Security Orchestration, Automation & Response) pour centraliser l’automatisation de la réponse aux incidents. Il vous permet d’automatiser les étapes répétitives de la qualification et de l’investigation, ainsi que des actions techniques pour gagner du temps dans les situations d’urgence.
Les EDR vous offrent des capacités essentielles dans la gestion d’un incident. Soyez prêt à déployer un EDR de circonstance tel que Velociraptor, GRR ou DFIR ORC sur les machines qui n’ont pas d’EDR installé.
Pour améliorer vos capacités, vous devez aussi concentrer vos efforts sur les menaces qui sont les plus pertinentes. C’est ce que nous allons voir dans le chapitre suivant !
