Découvrez le principe de la régression linéaire
Découvrez le principe de la régression linéaire
La régression linéaire est le modèle le plus simple pour modéliser et prédire des valeurs continues en fonction d'autres variables.
Pensez-y comme une ligne droite qui relie les points dans un nuage de données, captant ainsi la tendance générale des observations.
De façon plus rigoureuse, lorsque l'on prédit une variable cible à partir d'une variable de prédiction , la régression linéaire consiste à trouver les coefficients et dans l'équation de la droite qui va être la plus proche de tous les points du nuage de points :
Dans le cas de 2 variables de prédiction et de , le modèle correspond à l'équation du plan défini par :
De façon générale, si on a variables de prédictions dans notre jeu de données pour la prédiction d'une variable cible , le modèle de regression linéaire consiste à trouver les coefficients de l'équation :
De façon abrégée nous écrirons :
~
Notez le signe ~ qui veut dire que l'on régresse la variable cible par rapport aux variables de prédictions .
La simplicité de la régression linéaire lui confère des propriétés précieuses :
interprétabilité : le poids respectif des coefficients correspond au poids relatif des prédicteurs ;
facilité d'implémentation : il existe beaucoup de langages et de librairies ;
rapidité de calcul : optimisés depuis longtemps, les calculs sont hyper rapides ;
légère en mémoire : donc adaptée à l'Internet des Objets (IoT) basé sur des senseurs de faible puissance.
Comprenez les limites de la régression linéaire
Utiliser une régression linéaire nécessite cependant de prendre quelques précautions.
Limite n° 1 : Utiliser une régression linéaire à partir d’un cas non linéaire ne marchera pas
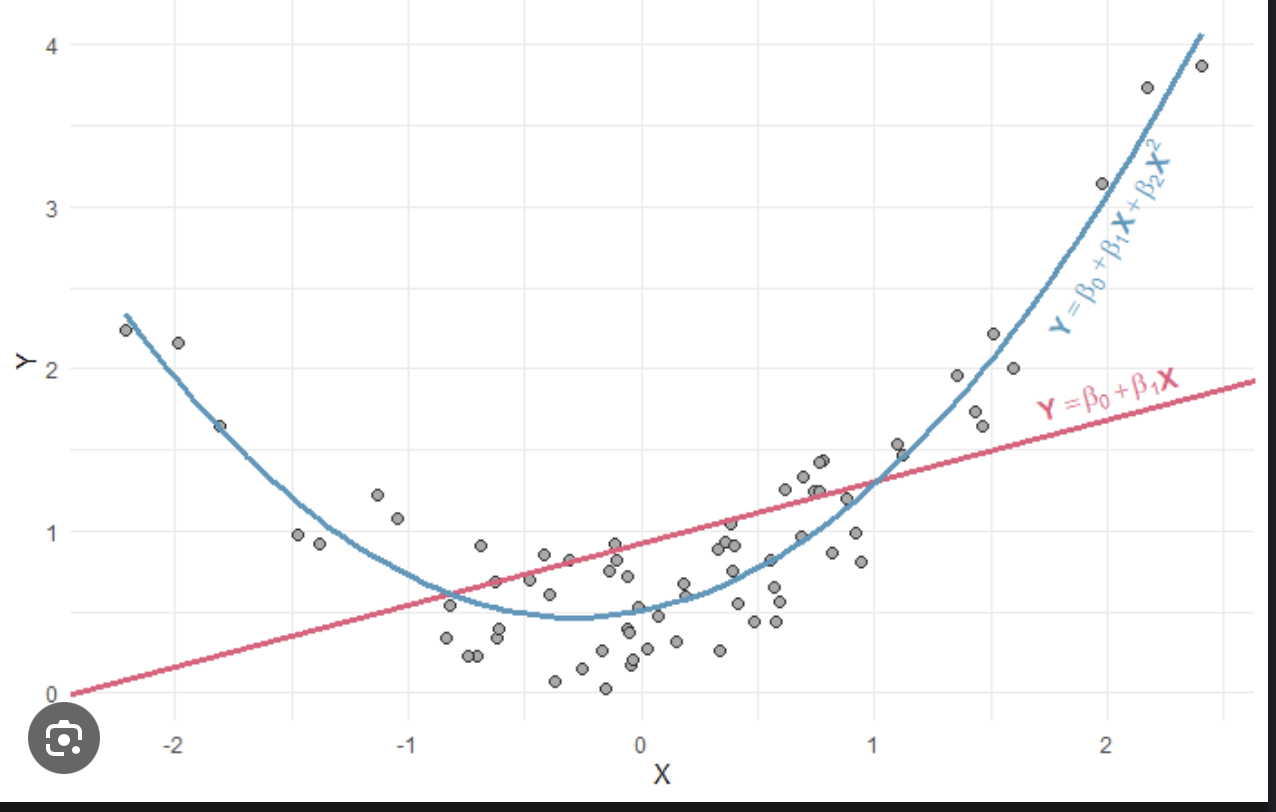
Il faut s'assurer que la relation entre la variable cible et les prédicteurs soit linéaire. Utiliser une régression linéaire dans des cas évidemment non linéaires ne marchera pas.
Mais qu'est-ce qu'un cas non linéaire ?
Supposons que nous ayons une relation quadratique entre la variable cible et un prédicteur + du bruit comme sur le graphe ci-dessous. On voit bien que la droite de la régression linéaire n'explique en rien la relation entre le prédicteur et la cible.
Limite n° 2 : des variations d'amplitude significative peuvent fausser l'importance des coefficients
Une autre précaution utile concerne l'amplitude respective des variables.
Les valeurs des coefficients de la régression linéaire sont en effet inversement proportionnelles à l'amplitude de la variable associée.
Si une variable est 1 000 fois plus grande en moyenne qu'une autre variable, et si ces 2 variables ont le même pouvoir de prédiction sur la variable cible, alors le coefficient de la grande variable sera 1 000 fois plus petit que celui de la deuxième variable.
En normalisant les variables afin que leur amplitude soit comprise dans un intervalle comparable, chaque coefficient de la régression linéaire reflète directement l'impact de la variable sur la variable cible, son pouvoir de prédiction.
À nous de jouer : Let's regress!

C'est un dataset classique issu du livre référence An introduction to Statistical Learning. Il contient 200 échantillons sur le budget alloué aux publicités télévisées, à la radio et dans les journaux, ainsi que les ventes résultantes.
Variable cible :
ventes(salesdans la version originale).
Prédicteurs : budgets de publicité :
pour la TV :
tv;pour la la radio :
radio;pour la presse :
journaux(newspaperdans la version originale).
La variable cible, ventes , est continue, donc nous sommes bien dans une logique de régression (et non de classification).
Nous allons essayer de prédire le volume de vente en fonction du budget publicitaire en TV, radio et journaux.
Chargeons et explorons le dataset.
import pandas as pd
df = pd.read_csv(<url du dataset>;)
# Explorons rapidement les données avec
df.head()
df.describe()La fonction regplot() permet non seulement d'afficher le nuage de points des variables tv , radio et journaux en fonction des ventes, mais aussi de tracer la ligne de régression.
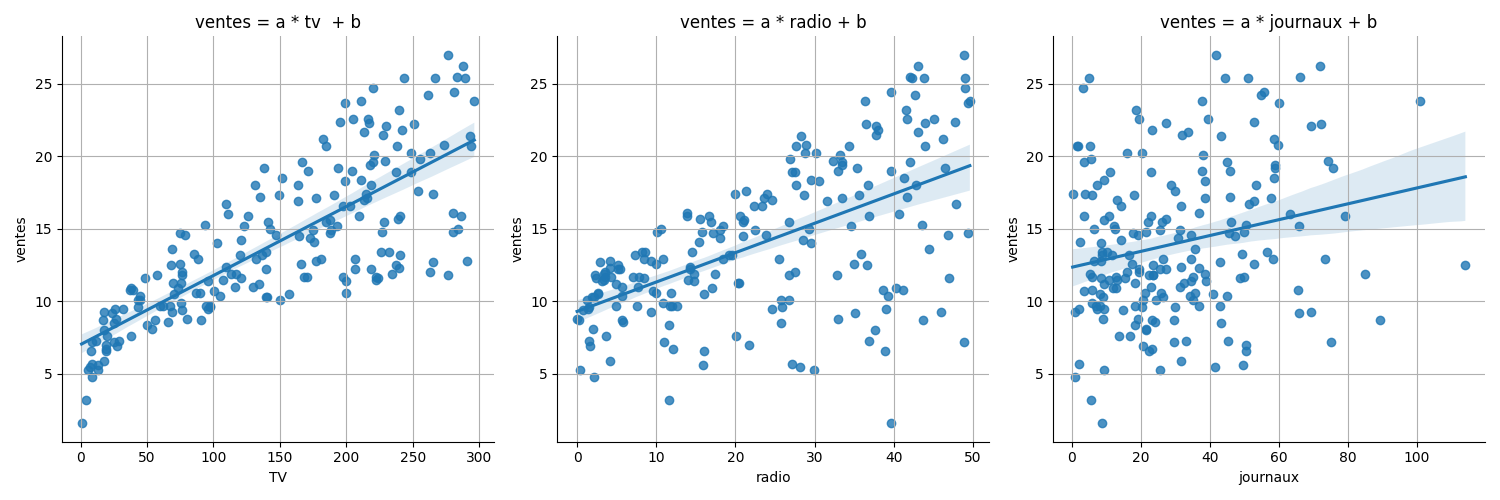
La zone bleu pâle reflète l'incertitude du modèle. Plus elle est grande, moins la régression est fiable.
Le graphe montre que :
tvest plus prédictive des ventes queradio;radioest plus prédictive quejournaux.
L'observation est confirmée par les coefficients de corrélation :
df.corr()
- tv 0.78
- radio 0.58
- journaux 0.23Choisissons le modèle de régression linéaire de scikit-learn.
from sklearn.linear_model import LinearRegression
reg = LinearRegression()Cette fonction prends les variables d'entrée, la variable cible, un ratio et retourne 4 objets :
X_train: prédicteurs pour l'entraînement ;X_test: prédicteurs pour l'évaluation ;y_train: variable cible pour l'entraînement ;y_test: variable pour l'évaluation.
On va ensuite utiliser :
X_trainety_trainpour entraîner le modèle (train en anglais) ;X_testety_testpour l'évaluer (test en anglais).
Cela donne :
from sklearn.model_selection import train_test_split
X = df[['tv','radio','journaux']]
y = df.ventes
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)Comme notre jeu de données a 200 échantillons et que l'on en réserve 20 % pour le test, on aura les tailles suivantes ( X.shape() et y.shape() ) :
X_train: 160 * 3X_test: 40 * 3y_train: 160 * 1y_test: 40 * 1
On a donc 160 échantillons pour entraîner notre modèle et 40 échantillons que le modèle ne voit pas pendant son entraînement et qui nous serviront à l'évaluer.
Le terme random_state est un paramètre qui permet de contrôler la reproductibilité des résultats lorsque vous effectuez des opérations qui impliquent de l'aléatoire, comme par exemple scinder les données en sous-ensembles de train et test.
En fixant une valeur spécifique pour random_state, vous vous assurez que les opérations aléatoires se déroulent toujours de la même manière. Les résultats sont reproductibles et vous pouvez comparer différents modèles.
On entraîne le modèle :
reg.fit(X_train, y_train)Pour estimer la performance sur le sous-ensemble de test, il faut tout d'abord obtenir les prédictions pour X_test :
y_pred_test = reg.predict(X_test)On peut maintenant calculer l'écart entre les vraies valeurs de test (y_test) et celles prédites par le modèle.
Utilisons la RMSE et la MAPE comme scores. Pour ces 2 métriques, un score plus petit correspond à un meilleur modèle. MAPE est comprise entre 0 et 1, tandis que RMSE n'est pas contrainte.
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
print(f"RMSE: {mean_squared_error(y_test, y_pred_test)}")
print(f"MAPE: {mean_absolute_percentage_error(y_test, y_pred_test)}")On obtient :
RMSE :
3.17MAPE :
0.15
Est-ce un bon ou un mauvais score ?
Difficile à dire, comme la RMSE n'est pas absolue. Une MAPE de 0,15 semble bien, car plus proche de 0 que de 1.
Mais peut-on faire mieux ?
Amélioration n° 1 : Ajouter un terme quadratique
Si l'on regarde bien le nuage de points de ventes par rapport à tv , on remarque que ce nuage de points suit plutôt une courbe qu'une ligne droite. C'est particulièrement vrai pour la partie en bas à gauche du graphe.
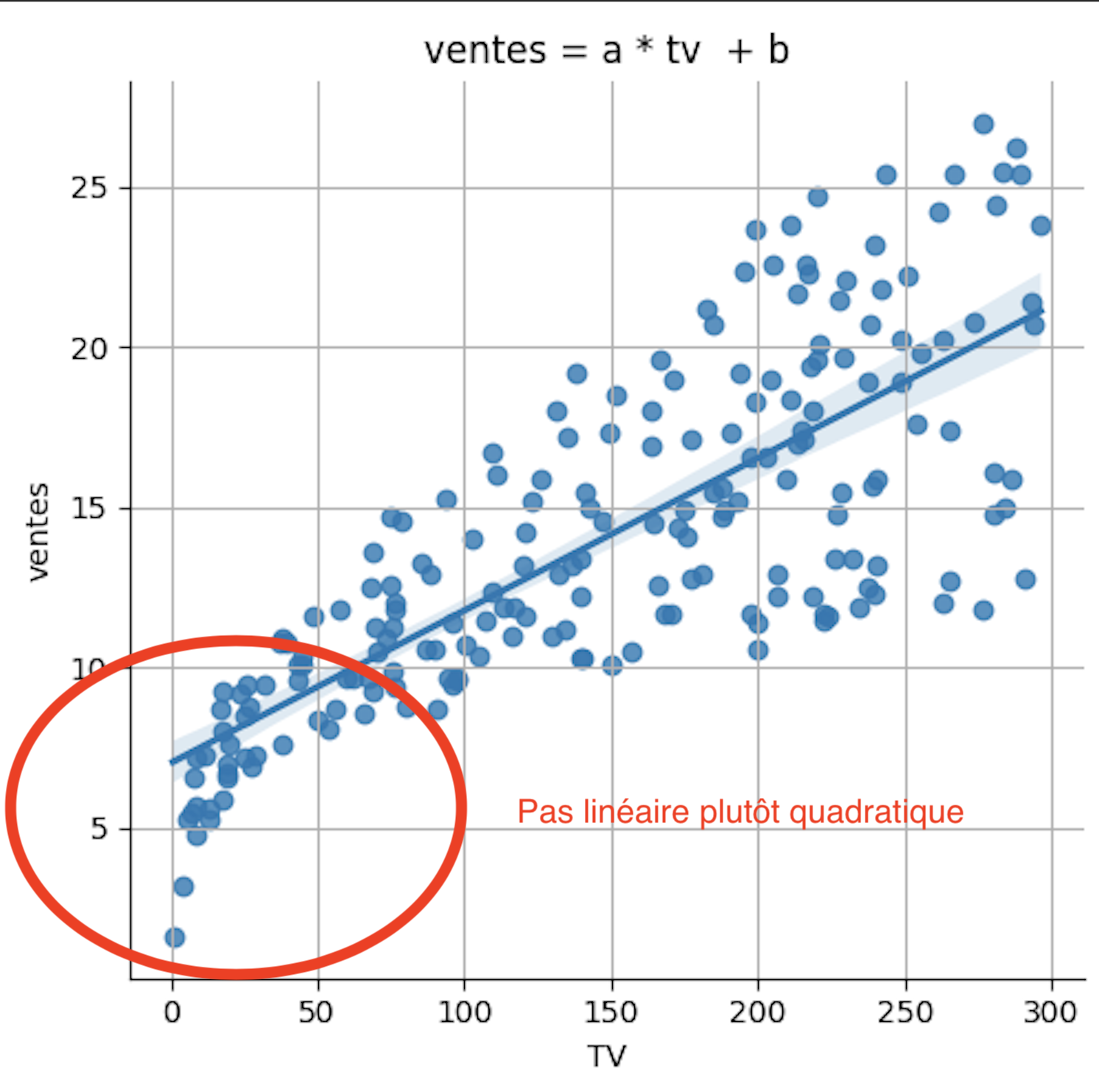
On peut en déduire que la relation entre ventes et tv n'est pas simplement linéaire, c'est-à-dire :
Mais cela dépend aussi d'un terme comme ceci :
C'est un polynôme du second degré de variable tv .
La régression polynomiale consiste à ajouter les puissances de certains prédicteurs dans la régression. C'est une façon simple pour capturer les relations non linéaires entre les variables.
Avant d'entraîner ce nouveau modèle, on remarque que l'amplitude de tv2 va être bien plus grande que celle des autres variables. On va donc normaliser les variables, pour que leurs amplitudes soient compatibles.
Créons la nouvelle variable tv2 = tv^2 :
df['tv2'] = df.tv**2Normalisons l'amplitude en utilisant MinMaxScaler qui force les variables entre 0 et 1.
Dans sklearn, appliquer un "Scaler" consiste à :
1. L'importer :
from sklearn.preprocessing import MinMaxScaler2. Le créer (l'instancier) :
scaler = MinMaxScaler()3. Le fit() sur les données (le scaler calcule alors les min et max des variables) :
scaler.fit(df)4. Et enfin transformer les données :
data_array = scaler.transform(df)La méthode transform retourne un array et non une dataframe. Pour une question de simplification des scripts, je vais recréer la dataframe df :
df = pd.DataFrame(data_array, columns = ['tv','radio','journaux','ventes','tv2'])Les étapes 3 et 4 peuvent être concentrées en utilisant la méthode fit_transform() , ce qui donne :
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data_array = scaler.fit_transform(df)
df = pd.DataFrame(data_array,
columns = ['tv','radio','journaux','ventes','tv2'])À ce stade, df ne contient que des valeurs entre 0 et 1.
df.describe().loc[['min','max']]
| tv | radio | journaux | ventes | tv2 |
min | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
max | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
Notre régression linéaire est maintenant une régression polynomiale grâce à la présence du terme quadratique tv2 . Entraînons-la.
y ~ tv + radio + journaux + tv2
Le Python :
X = df[['tv','radio','journaux', 'tv2']]
y = df.ventes
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)
reg.fit(X_train, y_train)
y_hat_test = reg.predict(X_test)
print(f"Coefficients: {reg.coef_}")
print(f"RMSE: {mean_squared_error(y_test, y_hat_test)}")
print(f"MAPE: {mean_absolute_percentage_error(y_test, y_hat_test)}")Ce qui donne :
modèle | normalisé | RMSE | MAPE |
ventes ~ tv + radio + journaux | non | 3.1741 | 0.15199 |
ventes ~ tv + radio + journaux | oui | 0.00492 | 0.19102 |
ventes ~ tv + radio + journaux + tv2 | oui | 0.00369 | 0.162 |
On note une nette amélioration par rapport au premier modèle.
Il est possible d'aller encore plus loin en ajoutant le terme croisé tv * radio qui reflète l'effet cumulé d'une campagne de pub qui soit à la fois à la radio et à la télévision.
Allez plus loin
On a parlé du paramètre random_state qui permet de contrôler l'aspect aléatoire du "train, test, split". En faisant varier ce paramètre, les données seront réparties parmi les sous-ensembles entraînement et test de façon différente et le modèle ne sera pas entraîné sur les mêmes échantillons.
Cependant imaginez que parmi le jeu de données se trouvent quelques échantillons très différents des autres. Par exemple, un très fort budget en journaux (> 200, par exemple). Si ces échantillons se retrouvent dans le sous-ensemble d'entraînement, le modèle va le prendre en compte et la droite de régression sera plus plate ou penchée que si ces échantillons se trouvaient dans le sous-ensemble de test.
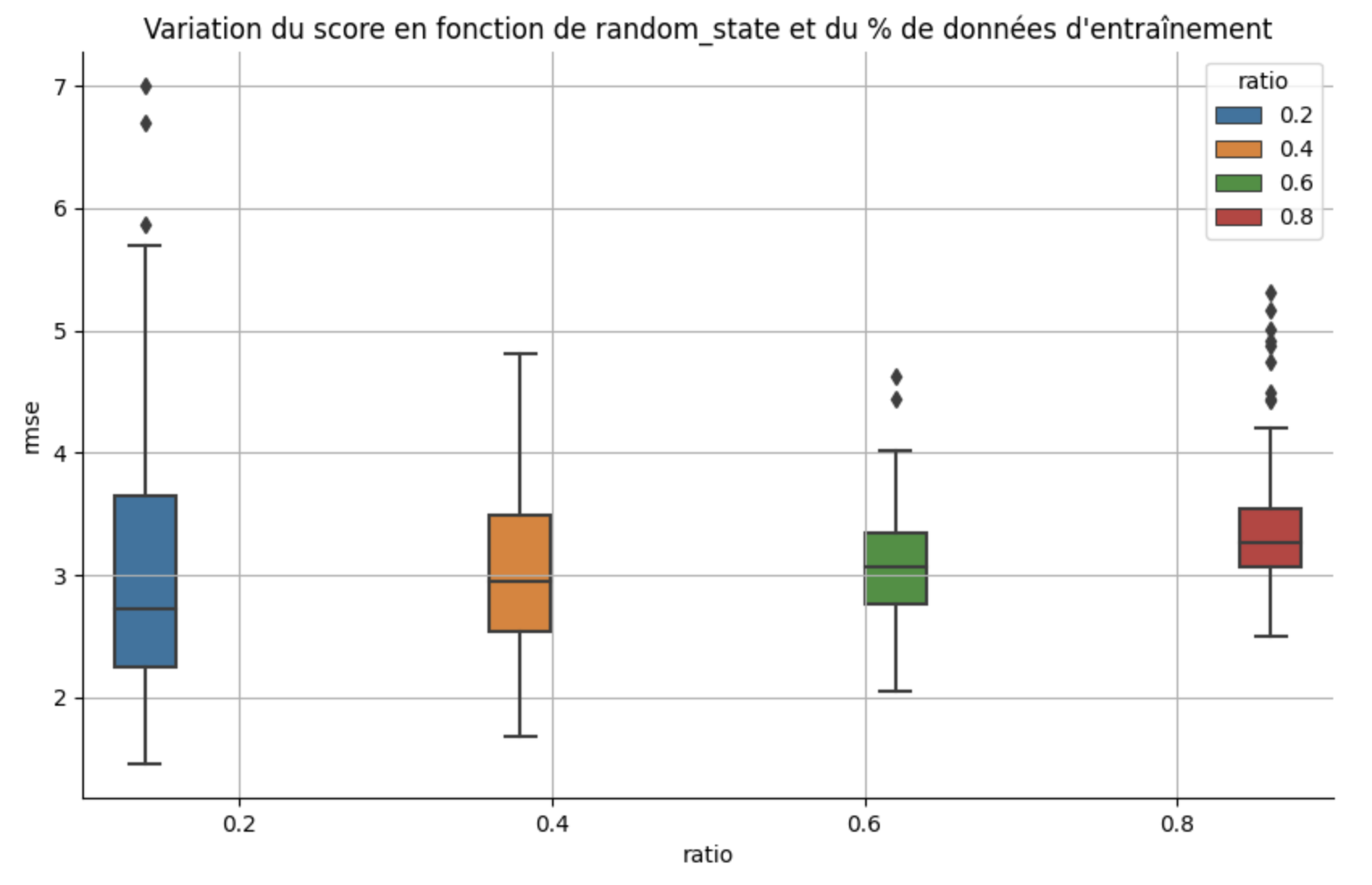
Pour observer cette sensibilité à la répartition entre train et test, ainsi que l'influence du random_state, comparez les scores obtenus au test_size et au random_state . Pour un test_size élevé ( test_size = 0.800 , le modèle aura très peu d'échantillons pour s'entraîner et sera plus sensible à la répartition des échantillons entre le test et le train.
C'est bien ce que l'on observe sur la figure suivante où l'on voit le score obtenu sur la régression ventes ~ tv + radio + journaux pour des valeurs décroissantes de test_size : 80 %, 60 %, 40 % et 20 %.
La variabilité du score est plus importante quand le nombre d'échantillons d'entraînement est faible (à gauche,
test_size= 80 %).Néanmoins, même pour un large set d'échantillons d'entraînement (à droite,
test_size= 20 %), les scores peuvent varier fortement en fonction de la valeur derandom_state.
En résumé
La régression linéaire est un modèle simple pour prédire des valeurs continues en fonction de variables prédictives.
On évalue les performances du modèle en utilisant des métriques telles que RMSE et MAPE.
La normalisation des variables permet de lier les coefficients de la régression linéaire au poids relatif des prédicteurs.
Il est important de s'assurer que la relation entre la variable cible et les prédicteurs est linéaire avant d'utiliser la régression linéaire.
La régression polynomiale permet de capturer des relations non linéaires entre les variables en ajoutant des termes quadratiques ou d'ordre supérieur.
L'utilisation de
train_test_splitpermet de diviser les données en sous-ensembles d'entraînement et de test pour évaluer le modèle.Le choix du paramètre
random_stateaffecte la reproductibilité des résultats lors de la séparation des données en sous-ensembles.
Dans le chapitre suivant, nous allons plonger dans la classification et ses nombreuses métriques d'évaluation.
