Classifiez les données avec la régression logistique
Découvrez le principe de régression logistique (ou classification)
On distingue plusieurs types de classifications suivant les valeurs prises par la variable cible :
La classification binaire où la variable cible prend 2 valeurs exclusives : oui/non, 0/1, vrai/faux, marche/ne marche pas, etc.
Le cas multiclasse où la variable cible peut prendre plus de 2 valeurs.
Et parmi ce cas multiclasse, on distingue ensuite :la classification ordinale où les valeurs sont ordonnées : 1, 2, 3 ; mauvais, moyen, bon ;
et la classification nominale où les catégories ne sont pas ordonnées : les couleurs, les nationalités, les animaux...
Enfin, on parle de classification multilabel quand un échantillon peut appartenir à plusieurs catégories à la fois. Par exemple, les genres d'un film ou la taxonomie d'un animal : un tigre est à la fois un mammifère, un félin et un carnivore.
Nous allons principalement travailler sur le cas le plus simple, la classification binaire.
Comprenez le rapport entre classification et régression
Le principe général de modélisation est similaire à celui de la régression ; ce qui va surtout changer, ce sont les métriques de score des modèles et leur interprétation.
Mais attendez, pourquoi parle-t-on de régression logistique pour la classification ?
En fait, on va adapter la régression linéaire au cas de la classification en interprétant la prédiction de la régression linéaire, comme une des catégories de la variable cible.
Prenons le cas d'une régression linéaire à 1 prédicteur :
Ici, est continue et potentiellement peut prendre toute valeur réelle.
Imaginons une fonction qui projette dans l'intervalle :
On peut interpréter la variable comme étant la probabilité que la prédiction soit dans une des catégories. En considérant par exemple un seuil de classification de .
si alors catégorie 0 ;
si alors catégorie 1.
ChatGPT : Un nombre entre 0 et 1 peut être interprété comme une probabilité parce qu'il mesure la possibilité d'un événement se produisant. 0 signifie impossible, 1 signifie certain, et les valeurs entre 0 et 1 indiquent les chances relatives de l'événement.
Merci ChatGPT !
On peut donc appliquer une régression linéaire, projeter le résultat dans l'intervalle et interpréter cette valeur comme la probabilité d'appartenance à une des catégories souhaitées.
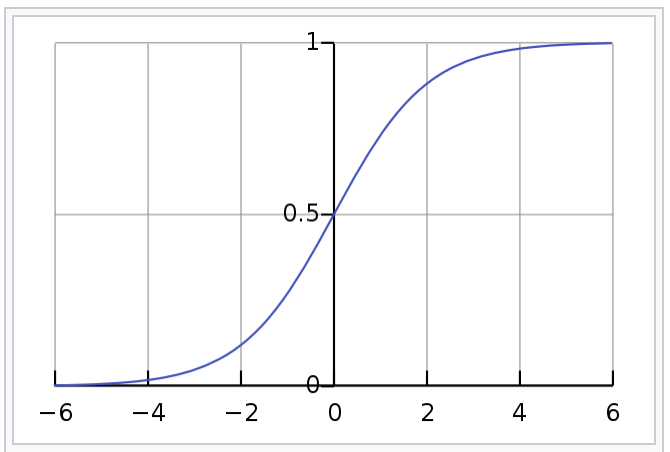
Plus précisément, une régression logistique dans un cas de classification binaire de prédiction consiste à :
modéliser une régression linéaire ;
projeter la prédiction y variable dans l'intervalle [0,1]: logistique(y) ;
interpréter logistic(y) comme probabilité que y soit dans une catégorie ou dans l'autre en fonction d'un seuil t=0.5 :
si logistique(y) < 0.5 => catégorie 0,
si logistique(y) >= 0.5 => catégorie 1.
Résolvez un problème de classification avec la régression logistique
Ce dataset a 569 échantillons, 30 prédicteurs et une variable cible binaire : la tumeur est maligne (1) ou bénigne (0).
from sklearn.datasets import load_breast_cancer
X, y = load_breast_cancer(return_X_y=True)
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(random_state=808).fit(X, y)Regardons 2 échantillons en particulier et leur prédiction :
clf.predict([X[8, :]])On obtient 0 : bénigne
Un autre :
clf.predict([X[13, :]])On obtient 1 : maligne.
On peut aussi obtenir la probabilité de prédiction de chaque échantillon avec la fonction predict_proba() qui donne la paire de probabilité pour 0 et 1.
Note dans le cas binaire : p(0) + p(1) = 1
clf.predict_proba([X[8, :]])
array([[0.69722956, 0.30277044]])Soit 69,7 % d'appartenir à la classe 0 et 30,3 % d'appartenir à la classe 1.
clf.predict_proba([X[13, :]])
array([[0.1193025, 0.8806975]])Soit 11,9% d'appartenir à la classe 0 et 88 % d'appartenir à la classe 1.
Le modèle semble moins fiable au niveau de sa classification pour l'échantillon 8 que pour l'échantillon 13.
Un bon moyen d'analyser les performances d'un modèle de classification consiste à tracer l'histogramme des probabilités des prédictions.
y_hat_proba = clf.predict_proba(X)[:,1]
import seaborn as sns
sns.histplot(y_hat_proba)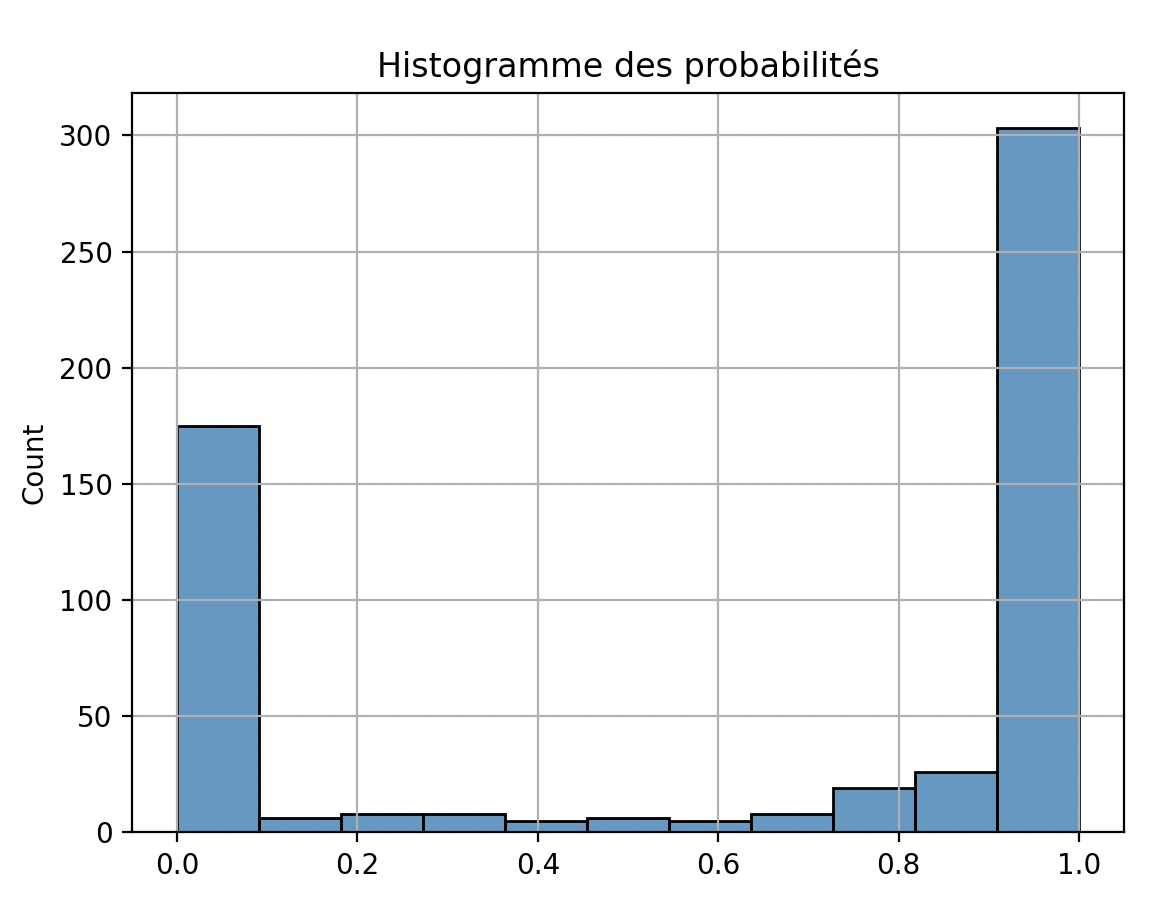
Le modèle est assez fiable au niveau de ses prédictions, la plupart des prédictions ont une probabilité proche de 0 ou de 1.
Pour un mauvais modèle nous aurions par exemple des prédictions moins clairement espacées. Par exemple, ici, la majorité des prédictions ont une probabilité entre 0,55 et 0,65. Le modèle est moins fiable.
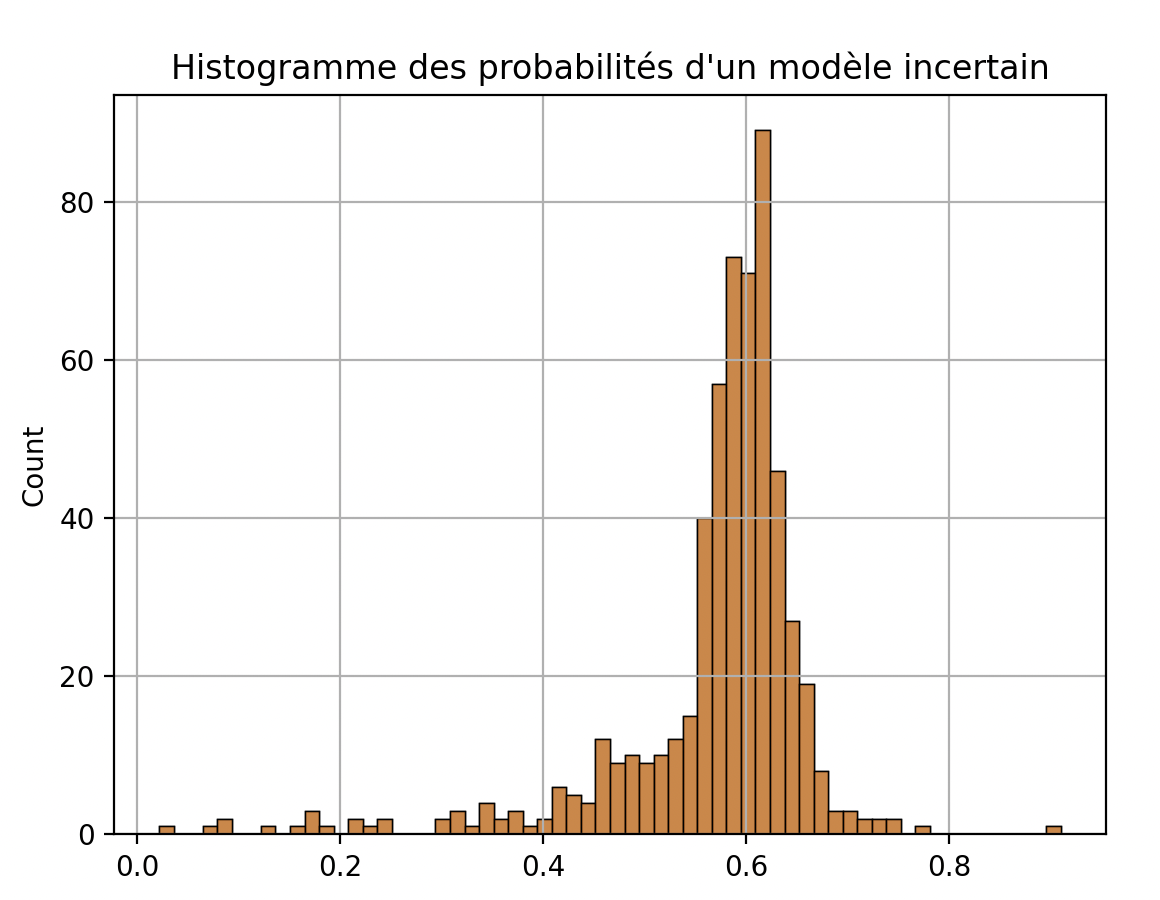
Évaluez la performance d'un modèle de classification
Dans scikit-learn la fonction de calcul de l'accuracy est accuracy_score.
Reprenons le modèle de régression logistique que nous venons d'entraîner, et obtenons ses prédictions :
y_pred = clf.predict(X)Son exactitude est alors :
from sklearn.metrics import accuracy_score
accuracy_score(y, y_pred)
> 0.94794,7 % ! C'est un bon score pour une simple régression logistique.
Ce modèle est-il biaisé ou objectif ? A-t-il tendance à classer plutôt les 0 en 1 ou les 1 en 0 ?
Pour voir cela on fait appel à la matrice de confusion, un tableau 2x2 avec en colonnes le nombre de valeurs vraies et en rangées le nombre de valeurs prédites :
from sklearn.metrics import confusion_matrix
confusion_matrix(y, y_pred)
array([[193, 19],
[ 11, 346]])De façon générale, dans le cas binaire, la matrice de confusion s'exprime de la façon suivante :
|
| catégorie prédite |
|
|
| positif | négatif |
catégorie réelle | positif | TP : vrai positif | FN : faux négatif |
| négatif | FP : faux positif | TN : vrai négatif |
La diagonale contient le nombre d'échantillons bien classés.
Hors diagonale, le nombre des échantillons mal classés.
où
TP : true positive, vrai positif : échantillons positifs prédits comme positifs.
FP : false positive, faux positif : échantillons négatifs prédits comme positifs de façon erronée.
TN : true negative, vrai négatif : échantillons négatifs prédits comme négatifs.
FN : false negative, faux négatif : échantillons positifs prédits comme négatifs de façon erronée.
|
| catégorie prédite |
|
|
| négatif | positif |
catégorie réelle | négatif | TN : vrai négatif | FP : faux positif |
| positif | FN : faux négatif | TP : vrai positif |
À partir des métriques TP, TN, FP, FN, on définit de nombreuses métriques adaptées à des problématiques et des interprétations spécifiques, dont le “rappel” et la “précision”.
Le rappel = TP / (TP + FN) (recall en anglais)
Le rappel est adapté pour minimiser les faux négatifs, quand les conséquences de manquer des instances positives sont graves.
Par exemple, dans un contexte médical, ne pas détecter la maladie d'un patient (faux négatif) peut avoir des conséquences sérieuses pour la personne. Un modèle avec un fort rappel réduit les risques de rater une détection souhaitée.
La précision = TP / (TP + FP)
La précision est adaptée quand on souhaite minimiser les faux positifs.
Un e-mail faussement identifié comme étant du spam (faux positif) peut faire disparaître des informations importantes. Un modèle avec une forte précision réduit les risques de fausses alertes.
Le paradoxe de l'exactitude
Il y a parfois un fort déséquilibre entre les cas négatifs et les positifs dans le dataset. Par exemple dans la détection de pannes de machines, de maladies ou de fraudes.
Prenons par exemple le cas d'un dataset de fraude avec 1 % des échantillons correspondant au cas positif où il n'y a pas de fraude.
Un modèle de prédiction simpliste et absurde qui prédit qu'il n'y a jamais de fraude aura une exactitude de 99 %. Un score excellent mais qui évidemment ne sert à rien. D'ou l'intérêt d'avoir des métriques de classification adaptées à chaque type de situation.
Comparons les résultats obtenus pour 2 autres seuils. Par exemple et .
Pour obtenir les catégories prédites avec ces seuils, on part des probabilités prédites par le modèle :
y_hat_proba = clf.predict_proba(X)[:,1]On obtient les catégories relatives pour les 2 seuils :
y_pred_03 = [ 0 if value < 0.3 else 1 for value in y_hat_proba ]
y_pred_07 = [ 0 if value < 0.7 else 1 for value in y_hat_proba ]On a alors les matrices de confusion suivantes :
pour 0,3 :
confusion_matrix(y, y_pred_03)
array([[185, 27],
[ 6, 351]])pour 0,7 :
confusion_matrix(y, y_pred_07)
array([[200, 12],
[ 18, 339]])Les recalls et précisions sont récapitulés dans le tableau suivant :
from sklearn.metrics import precision_score, recall_score
precision_score(y, y_pred)
recall_score(y, y_pred)
| exactitude | précision | rappel |
seuil = 0.3 | 0.942 | 0.9286 | 0.9832 |
seuil = 0.5 | 0.9473 | 0.9479 | 0.9692 |
seuil = 0.7 | 0.9473 | 0.9658 | 0.9496 |
Notre modèle étant très performant, les différences de score sont faibles, mais on observe bien une dépendance vis-à-vis des seuils utilisés.
Regardons pour finir une métrique de classification assez généraliste pour être utilisable dans la plupart des cas. Il s'agit de la ROC AUC.
L'idée est de tracer le rappel ou TPR (true positive rate) par rapport au FPR (false positive rate) en fonction des seuils de classification. Le TPR est défini par TP / (TP + FN) et le FPR est défini par FP (FP + TN).
La courbe obtenue est appelée Receiver Operating Characteristic (ou ROC), ou encore fonction d’efficacité du récepteur.
Le graphe suivant montre le ROC d'un bon modèle et d'un mauvais modèle :
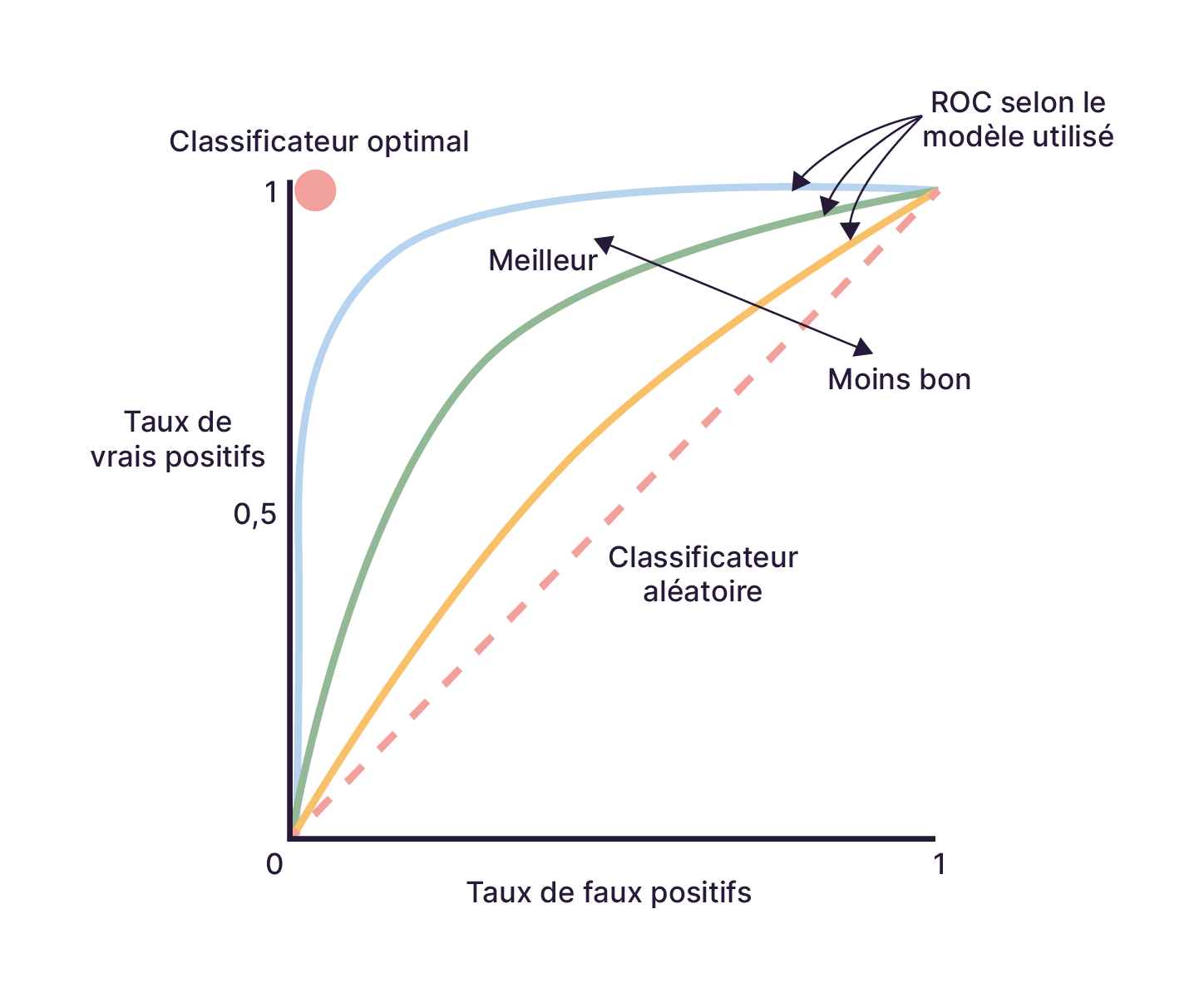
Plus la courbe se rapproche du coin en haut à gauche, meilleur est le modèle. La diagonale correspond à un modèle purement aléatoire.
La métrique qui nous intéresse est en fait la surface entre la courbe et la diagonale. Elle est appelée ROC- AUC pour Area under the ROC ou surface sous la courbe ROC. Elle prend en compte tous les seuils de classement entre 0 et 1 et donc ne dépend pas d'une valeur spécifique de ce seuil.
Pour notre modèle, on a une ROC-AUC de >> 0.99
Excellent !
Pour tracer la courbe ROC :
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y, y_hat_proba)
import matplotlib.pyplot as plt
plt.plot(fpr, tpr)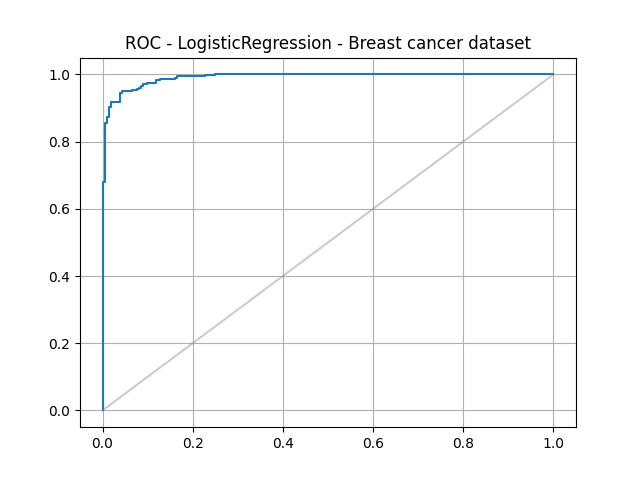
À vous de jouer !

Vous pouvez le charger avec :
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)À votre tour, entraînez une régression logistique sur ce dataset, et calculez les différentes métriques que nous venons de voir.
En résumé
On peut adapter la régression linéaire pour de la classification en appliquant la fonction logistique qui transforme la prédiction en une probabilité d'appartenance à une des classes.
Pour évaluer la performance d'une classification on regarde la matrice de confusion, et des métriques comme la précision, l'accuracy, le recall.
La courbe ROC permet de s'affranchir du seuil de classification pour mesurer la performance d'un modèle de classification.
Le Machine Learning n'est pas limité au contexte supervisé. Il existe des modèles de prédiction indépendants de la connaissance de la variable cible. Ce sont les modèles de partitionnement, que nous allons voir dans le chapitre suivant.
