Partitionnez les données avec k-means
Découvrez le principe du partitionnement (ou clustering)
Jusqu'à maintenant, nous avons travaillé sur des techniques d'apprentissage supervisées (comme la régression ou la classification) où le dataset d'entraînement du modèle contient la valeur de la variable cible.
Dans ce chapitre, nous allons travailler sur une technique de prédiction non supervisée, le partitionnement ou clustering en anglais.
L'algorithme de clustering a 2 objectifs :
Minimiser la différence entre les échantillons d'un même groupe. On veut des groupes denses et homogènes.
Maximiser la différence entre les groupes. On veut des groupes bien séparés les uns des autres.
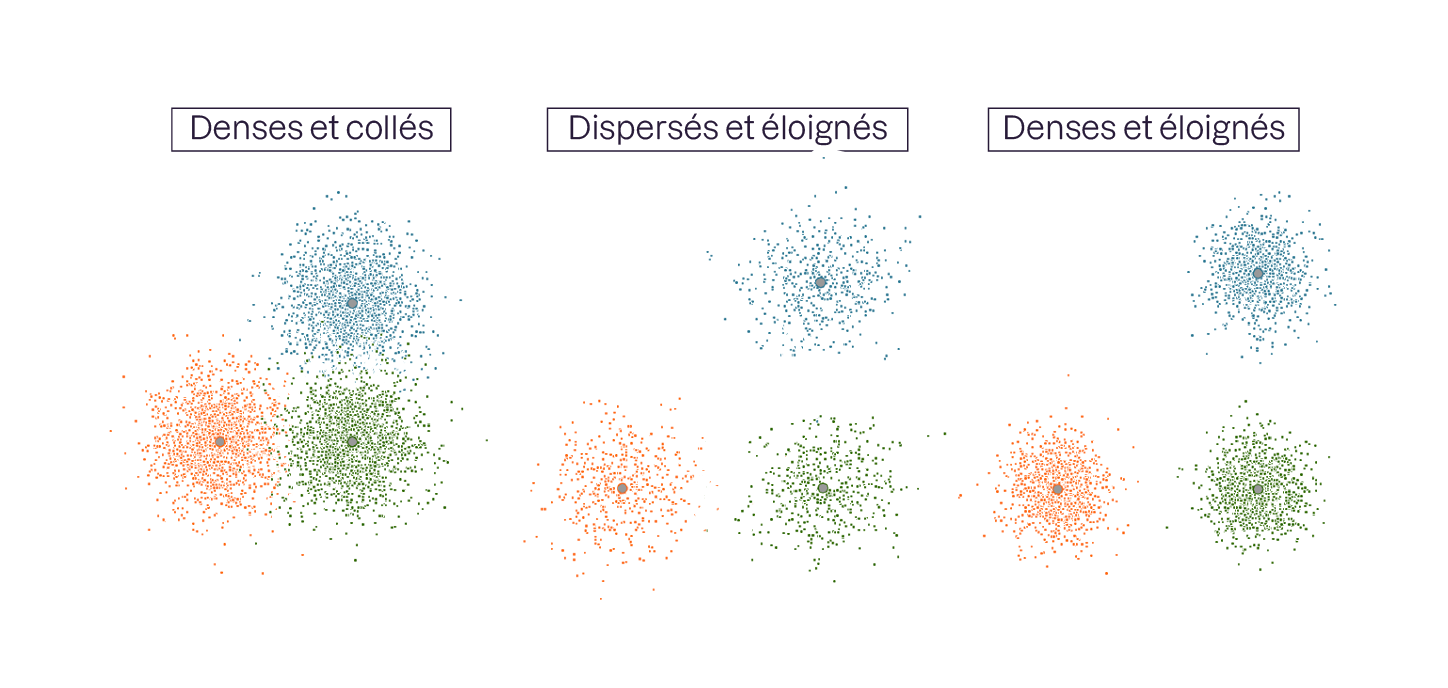
Pour illustrer, voici 3 nuages de points (ou clusters en anglais) :
Groupes cohérents collés.
Groupes séparés mais très dispersés.
Groupes cohérents et séparés.
Poser le problème ainsi amène immédiatement 3 questions (si si, 3).
Question 1 : Comment définir la similarité des échantillons ?
La similarité ou ressemblance d'échantillons se traduit directement par une faible distance entre les échantillons. La mesure utilisée la plus usitée est la distance euclidienne.
Question 2 : Comment trouver le nombre de clusters optimal ?
C'est un des paramètres d'entrée du modèle. Vous pouvez décider de partitionner les échantillons en 2 groupes, 3 groupes ou plus. Cette décision vous appartient et dépend du contexte dans lequel vous travaillez, de votre connaissance des données et de vos objectifs.
Cependant, il n'est pas toujours possible de connaître à l'avance le nombre de groupes qui sera optimum. Il nous faut donc estimer ce paramètre avant d'entraîner le modèle.
Pour estimer le nombre optimum de groupes, il existe plusieurs méthodes aux noms poétiques de “méthode du coude” (Elbow Method) ou “méthode de la silhouette” que nous verrons plus loin.
Question 3 : Quels types d'algorithmes pour le clustering ?
Appliquez le clustering
Le clustering est utilisé lorsque l'on veut comprendre le dataset sans à-priori préalable. Par exemple :
L'analyse des données géospatiales pour déterminer les caractéristiques spécifiques de certaines forêts dans le contexte de la biodiversité ou de la prévention des feux.
L'analyse de texte pour faciliter la compréhension et l'organisation de grands ensembles de données textuelles. Par exemple l'analyse de tous les articles d'une publication pour identifier les thèmes principaux ou récurrents.
La détection d'anomalies pour regrouper les données normales dans un cluster et en considérant toute donnée non conforme à ce cluster comme une anomalie.
Et bien entendu, le marketing pour mieux cibler les clients en fonction de leurs comportements d'achat, préférences ou caractéristiques démographiques.
Comprenez le k-means
L'algorithme du k-means est simple et efficace. En voici les étapes principales :
Phase d'initialisation :
On choisit arbitrairement un nombre de clusters K.
Le modèle sélectionne aléatoirement K points comme centres de clusters initiaux, appelés "centroïdes".
À chaque itération :
Attribution des données : Chaque point de données est associé au cluster dont le centroïde est le plus proche.
Mise à jour des centroïdes : Les coordonnées des centroïdes des clusters sont recalculées en prenant en compte les nouveaux points.
Ce processus itératif se répète jusqu'à ce que les centroïdes ne changent plus de manière significative, ou après un nombre d'itérations fixé à l'avance.
Une fois le processus terminé, vous obtenez K clusters avec des points de données similaires regroupés ensemble.
K-means est un algorithme simple pour regrouper des données, mais il nécessite de choisir judicieusement le nombre de clusters au départ et peut être sensible à l'initialisation des centroïdes.
Ce résultat final va dépendre :
du nombre de clusters choisi initialement ;
de l'initialisation : dans la plupart des implémentations du k-means, l'initialisation des premiers centroïdes se fait de façon automatisée et aléatoire. On peut donc obtenir des résultats sensiblement différents à chaque entraînement du modèle.
Appliquez le k-means()
Nous allons tout d'abord travailler sur un dataset que nous allons créer. Cela afin de bien comprendre la dynamique de l'algorithme et de mettre en œuvre le calcul du nombre optimal de clusters par la méthode de la silhouette.
Pour créer un dataset artificiel en 2 dimensions constitué de K clusters de N échantillons chacun, scikit-learn offre la fonction make_blobs() qui est bien nommée, elle fait des blobs !
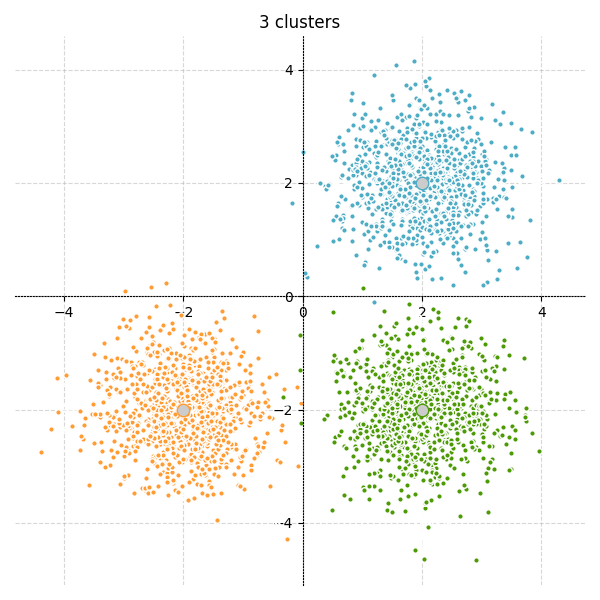
Par exemple voici 3 "blobs" bien séparés constitués de 3 000 échantillons chacun n_samples=3000 , centrés respectivement aux coordonnées centers = [[2, 2], [-2, -2], [2, -2]] et d'écart type cluster_std=0.7 (l'écart type dicte la dispersion des points).
from sklearn.datasets import make_blobs
centers = [[2, 2], [-2, -2], [2, -2]]
X, labels_true = make_blobs(
n_samples=3000,
centers=centers,
cluster_std=0.7)X est un array à 2 dimensions et labels_true contient le numéro du cluster de chaque échantillon.
On obtient donc 3 nuages de points bien distincts :
Appliquons maintenant l'algorithme du k-means sur ces 3 nuages de points.
from sklearn.cluster import KMeans
k_means = KMeans( n_clusters=3, random_state = 808)
k_means.fit(X)
print(k_means.cluster_centers_)On obtient les centres suivants : [-2.02 -2.00], [ 1.99 2.01], [ 1.98 -2.01], soit très proches des centres initiaux de nos données : [2, 2], [-2, -2], [2, -2].
Mais comment évaluer la performance du modèle lorsque l'on ne connaît pas les coordonnées des centroïdes initiaux ?
Il y a pour cela plusieurs méthodes.
Méthode 1 : Calculer la distance entre les points et leur centroïde respectif
Un bon clustering doit regrouper au maximum les points et donc cette distance doit être minimum.
C'est ce que fait la méthode score du k-means de scikit-learn.
Pour le modèle ci-dessus, nous obtenons :
k_means.score()
score: -4577.71Comme c'est un score relatif, il sert surtout à comparer différents modèles.
Méthode 2 : Faire une estimation graphique
En observant les nuages de points et leur répartition on peut estimer visuellement la pertinence du clustering.
Pour notre modèle, on observe le résultat suivant :
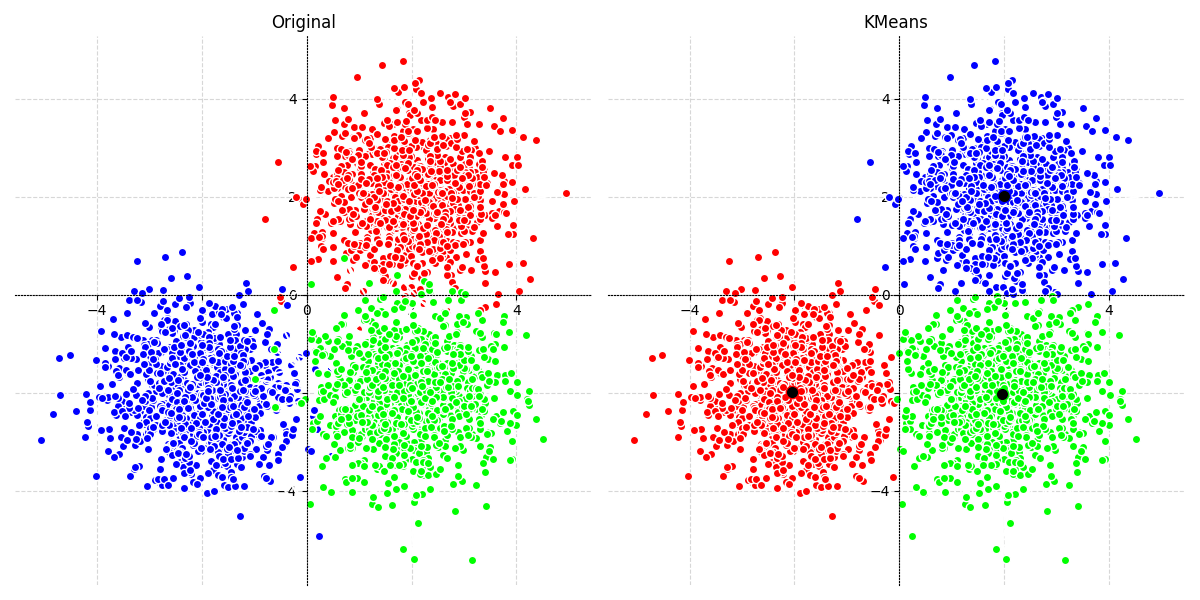
On peut remarquer que les nuages de points identifiés par le modèle sont très similaires aux groupes originaux. Seuls quelques points ont changé de cluster. Le modèle semble être bon.
Méthode 3 : Utiliser le coefficient de silhouette
La coefficient de silhouette prend en compte non seulement la densité des clusters mais aussi l'écart entre les différents clusters.
Il se calcule à partir de la distance moyenne intra-groupe (a) et de la distance moyenne entre les groupes les plus proches (b).
a est donc la moyenne des distances des échantillons avec leur centroïde respectif dans chaque groupe ;
b est la distance entre un échantillon et le groupe le plus proche dont l'échantillon ne fait pas partie ;
le coefficient de silhouette d'un échantillon est alors défini par silhouette = (b - a) / max(a, b).
Le coefficient de silhouette est compris entre -1 (mauvais) et 1 (excellent).
En Python, on utilise silhouette_score de scikit-learn :
from sklearn.metrics import silhouette_score
k_means_labels = k_means.predict(X)
print("silhouette_score: ", silhouette_score(X,k_means_labels ))On obtient un coefficient de silhouette de 0,60.
Dans cet exemple, nous sommes dans un cas idéal. Nous connaissons les données, leurs groupes respectifs et le nombre de clusters. Et en plus le dataset est linéairement séparable. On peut tracer une ligne droite de séparation entre les différents nuages de points.
Pour illustrer cela, faisons varier le nombre de clusters comme paramètre de k-means de 2 à 10, et regardons l'évolution du coefficient de silhouette.
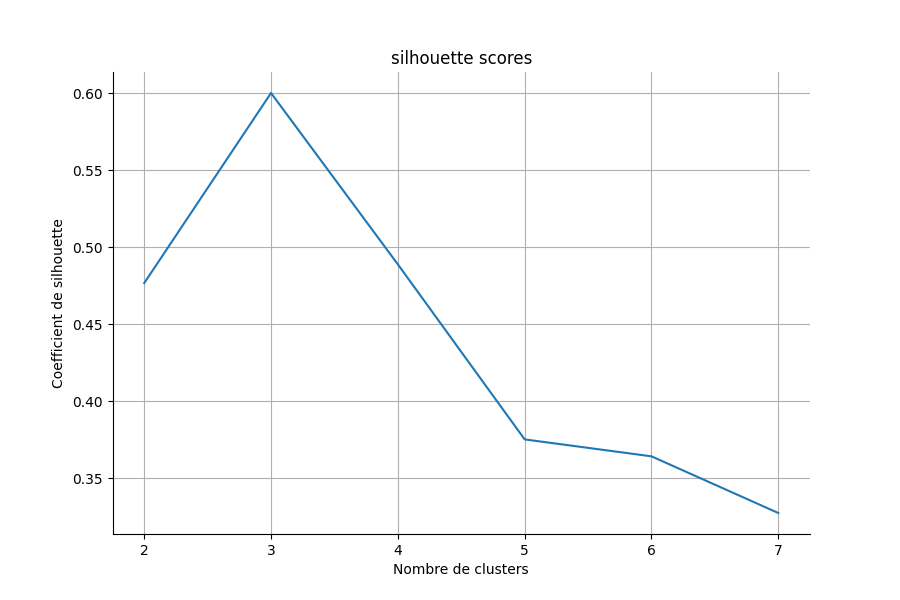
On observe bien un pic de la valeur du coefficient pour 3 clusters.
Appliquez le k-means sur Iris
Iris est constitué de 150 échantillons de fleurs réparties en 3 familles de 50 échantillons chacune :
Iris-Setosa ;
Iris-Versicolor ;
Iris-Virginica.
Les 4 variables sont la largeur et la longueur, en cm , des pétales et des sépales des fleurs. Une image vaut plus qu'une explication sur la différence entre sépale et pétale :

On le charge de la façon suivante :
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.targetX comprend les valeurs des prédicteurs sous forme de numpy array et y la liste des classes 0, 1 , 2.
Appliquons k-means sur ce dataset :
model = KMeans(n_clusters=3, n_init="auto")
model.fit(X)Voici les scores de classification :
print("score", model.score(X))
print("silhouette_score: ", silhouette_score(X,model.labels_ ))score : -78.85
silhouette_score : 0.55
Comme on sait que les fleurs appartiennent à 3 familles, on peut aussi regarder la performance du clustering en tant qu'outil de classification. Est-ce que le modèle retrouve bien les catégories initiales ?
Notez bien que contrairement à une classification supervisée, ce n'est pas le but du modèle. Le modèle de clustering ne tend qu'à regrouper les échantillons qui ne se ressemblent pas et à détecter à quelle catégorie arbitraire ils appartiennent.
Avant cela, il faut s'assurer que les numéros des catégories trouvées par le modèle de clustering correspondent bien aux catégories initiales. En regardant les catégories du modèle, on s'aperçoit qu'il faut échanger les catégories 0 et 1.
labels = model.labels_.copy()
# Valeurs intermédiaires
labels[labels==0] = 5
labels[labels==1] = 10
labels[labels==2] = 15
# Associer les bonnes catégories
labels[labels == 5] = 0
labels[labels == 10] = 2
labels[labels == 15] = 1from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
print("accuracy_score",accuracy_score(y,labels ))
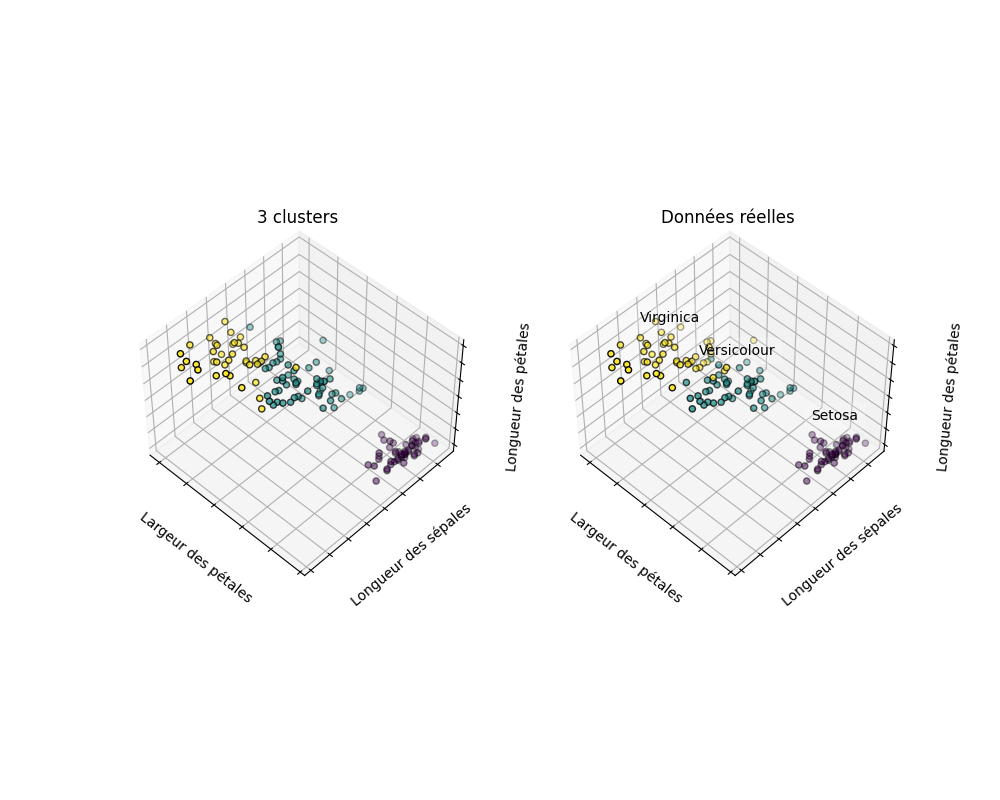
print("confusion_matrix\n",confusion_matrix(y,labels ))accuracy_score: 0.887
confusion_matrix
[[50 0 0]
[ 0 47 3]
[ 0 14 36]]Donc une performance assez bonne avec une précision de 88,7 %.
La matrice de confusion montre que la catégorie 1 est identifiée à 100 % et que les catégories 2 et 3 sont en majorité aussi bien identifiées.
L'analyse graphique confirme cela :
En résumé
L'algorithme du k-means consiste à calculer les centres des partitions d'échantillons de façon itérative.
Un bon partitionnement minimise la distance entre les points au sein d'une partition et maximise la distance entre les partitions.
Pour trouver le nombre optimal de partitions, on trace le coefficient de silhouette en faisant varier le nombre de partitions. Le nombre de partitions optimal correspond à un maximum du coefficient de silhouette.
K-means peut aussi être utilisé comme modèle de classification
Ceci clôt la partie 2 de ce cours. Vous êtes maintenant armé pour classifier, régresser et partitionner. Ce que vous allez faire avec le quiz 2 sur un dataset bien sympathique de pingouins de Palmer.
Dans la partie 3 du cours, nous nous attacherons à travailler sur les données pour à la fois améliorer leur qualité mais aussi les transformer afin qu'elles deviennent comestibles pour les modèles.
