Sauvegardez vos environnements Unix/Linux avec Rsync
Gwenaelle a vraiment apprécié l’installation et l’utilisation d’une solution professionnelle comme Veeam Backup.
Vous tenez tout de même à lui montrer une autre solution qui peut être mise en place pour leurs serveurs sous Gnu/Linux.
Et la solution que vous choisissez de présenter est Rsync.
Découvrez l’utilitaire Rsync
Rsync (pour Remote Synchronization, ou synchronisation distante en français) est l’outil de copie/synchronisation de fichier le plus connu et utilisé sur les systèmes Linux.
Une de ces particularités est l’utilisation d’un algorithme lui permettant de ne transférer que les différences.
Rsync va, pour simplifier, découper chaque fichier en blocs de données, et regarder si le bloc est présent ou non. Si ce n’est pas le cas, il va le copier. Il va ensuite reconstruire le fichier avec les anciens et les nouveaux blocs.
Ce n’est pas là que le seul avantage ou la seule particularité de Rsync. Voici quelques autres fonctionnalités qu’il intègre ou permet :
Préservation des attributs de fichier : Rsync permet de synchroniser les fichiers, mais aussi de préserver leurs permissions, les dates de création ou de modification ou les liens symboliques.
Filtrage des fichiers : Une fonctionnalité très utile est le filtrage de fichier. Vous pouvez décider d’inclure des fichiers à synchroniser, mais aussi d’en exclure ! Très pratique pour éviter de synchroniser des données de cache par exemple. Et tant qu'à faire, l’exclusion se fait aussi bien sur des chemins que sur des motifs.
La compression des données : Rsync permet de copier les données en les compressant. Ça permet de gagner en utilisation de bande passante et en temps de transfert.
Un mode simulation : cette fonctionnalité-là est, à mes yeux, une des plus utiles quand on met en place sa solution de sauvegarde. Rsync va faire exactement comme si la donnée était copiée… mais sans qu’elle le soit ! Et donc, on peut analyser la volumétrie ou le nombre de fichiers copié/modifié.
Rsync possède 2 modes de fonctionnements : Un premier, en mode serveur (“daemon”) de synchronisation, et le second en mode client (“remote shell”) :
Le mode serveur va être utile pour mettre en place un serveur de sauvegarde. Le serveur va écouter par défaut sur le pour 873 (mais qui est bien sûr modifiable) et attendre les différentes connexions des clients Rsync, qui vont effectuer les synchronisations. Les transferts peuvent être chiffrés via l’utilisation de SSH, même si ce n’est pas actif par défaut.
Le mode client va permettre la synchronisation entre de client Rsync, via une connexion SSH (port 22 par défaut). Cette connexion sera donc sécurisée et chiffrée.
Déployez Rsync sur votre environnement
Pour pouvoir montrer le fonctionnement de Rsync à Gwenaelle, la technicienne informatique de Coffeacao, vous allez pouvoir commencer à installer deux machines virtuelles Debian 12 de test.
La première, que nous appellerons “source”, qui contiendra les données, la seconde, “destination”, qui sera prévue pour les recevoir.
Préparation de la machine virtuelle source
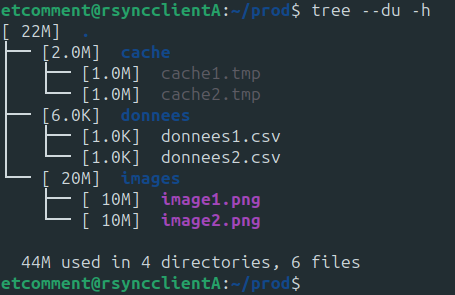
Dans la VM “source”, vous allez pouvoir créer quelques dossiers et fichiers, plus ou moins volumineux, et qui permettront de simuler des données que peuvent avoir Coffecao sur leur infrastructure.
Avant tout chose : Préparez l’arborescence
cd /home/etcomment/ mkdir prod && cd prod mkdir donnees cache images
Vous allez maintenant pouvoir générer des fichiers :
Des fichiers csv de 1Ko chacun dans le dossier “données”
dd if=/dev/urandom of=donnees/donnees1.csv bs=1K count=1 dd if=/dev/urandom of=donnees/donnees2.csv bs=1K count=1
2 fichiers temporaires de 1Mo dans le dossier cache
dd if=/dev/urandom of=cache/cache1.tmp bs=1M count=1 dd if=/dev/urandom of=cache/cache2.tmp bs=1M count=1
Et enfin 2 fichiers un peu plus gros (10Mo) en png dans le dossier “images”.
dd if=/dev/urandom of=images/image1.png bs=1M count=10 dd if=/dev/urandom of=images/image2.png bs=1M count=10
Voilà. Vous vous retrouvez avec une arborescence très simple, avec 3 dossiers comportant chacun 2 fichiers.
Préparation de la machine virtuelle destination
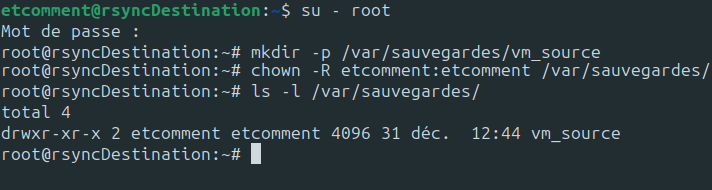
Vous allez maintenant préparer la machine virtuelle de destination.
Celle-ci aura juste un dossier vm_source dans le dossier /var/sauvegardes, où nous donnerons les droits à notre utilisateur de test.
su - root mkdir -p /var/sauvegardes/vm_source chown -R etcomment:etcomment /var/sauvegardes/
sur la source :

et sur la destination :

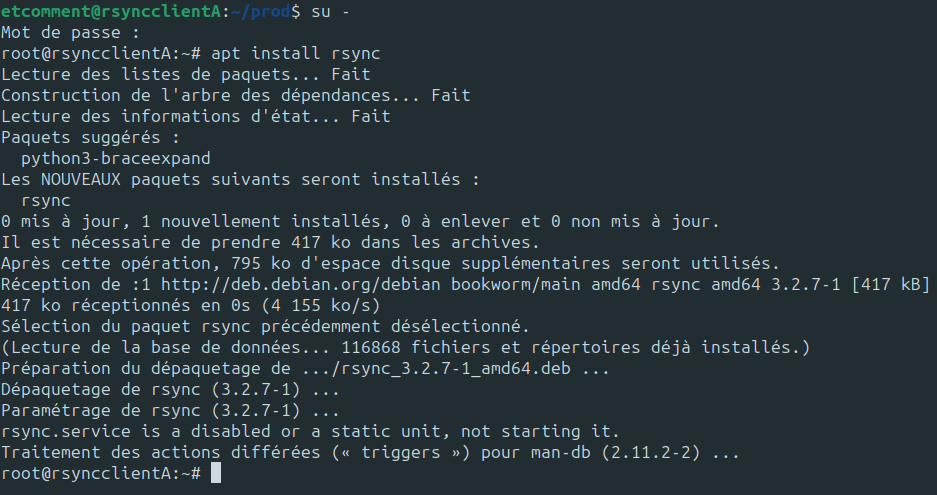
Maintenant que votre environnement de test est prêt, il ne vous reste plus qu’à installer rsync sur vos deux machines virtuelles avec la commande suivante :
apt install rsync
Vous allez pouvoir montrer les premiers usages de base de rsync à Gwenaelle.
Vous lui proposez de voir déjà comment effectuer une synchronisation locale d’un de ses dossiers, puis de faire une synchronisation distante.
Synchronisation d’un dossier en local
Gwenaelle vous fait remarquer que pour leurs synchronisations locales, ils utilisent actuellement la commande cp, qui est la commande de copie de Linux/UNIX/macOs.
Pourquoi utiliser rsync serait-il mieux ?
L’avantage est encore une fois d’utiliser l’algorithme de copie de rsync et de gagner en temps de transfert et en fiabilité de copie.
Pour effectuer une synchronisation, par exemple du dossier /home/etcomment/prod/donnees vers /home/etcomment/montages/, vous allez pouvoir utiliser la commande suivante :
rsync -av /home/etcomment/prod/donnees /home/etcomment/montages/
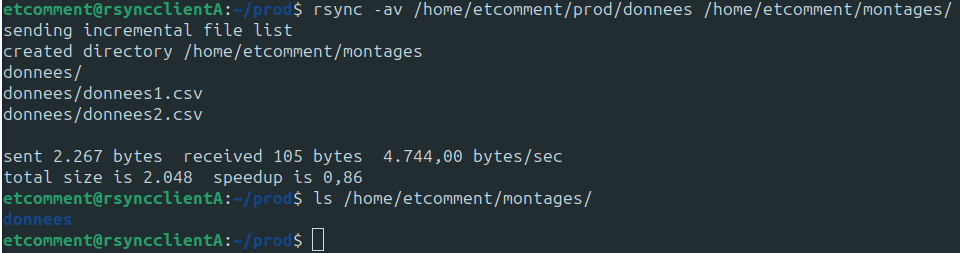
Nous avons utilisé les options -a et -v (simplifié en -av) :
-v (ou --verbose) : C’est assez courant dans les commandes Linux, et c’est l’option pour le "verbeux" (“Verbose” en anglais). C’est l’option qui vous permet d’avoir des informations en sortie.
-a (ou --archive) : C’est une option “raccourcis”. C'est-à-dire que cette option inclut les options suivantes :
-r (ou --recursive) : récursivité pour les répertoires ;
-l (ou --links) : copie les liens symboliques comme… des liens symboliques ;
-p (ou --perms) : préserve les permissions ;
-t (ou --times) : préserve les dates de modification ;
-g (ou --group) : préserve le groupe ;
-o (ou --owner) : préserve le propriétaire (root uniquement) ;
-d (--devices) : préserve les fichiers device (super-user only), comme /dev.
Eh oui, vous auriez très bien pu écrire la commande de cette manière :
rsync -rlptgoDv /home/etcomment/prod/donnees /home/etcomment/montages/
C’est tout de même plus simple de retenir le -a. Et en plus, ce sont la majorité des cas de figure qui rentrent dans ces options.
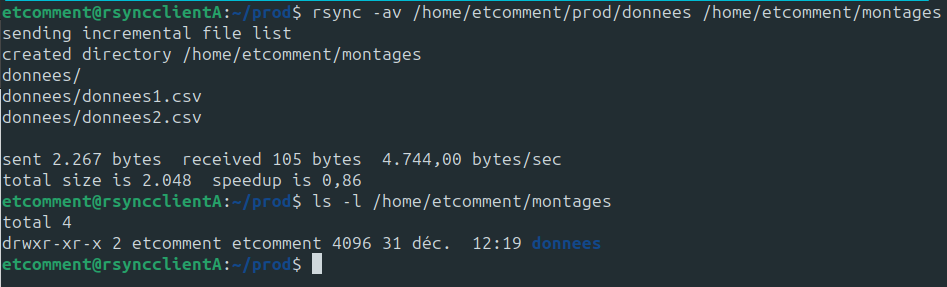
Ensuite, il nous suffit de mettre le dossier source, ici /home/etcomment/prod/donnees, et enfin, le dossier de destination : /home/etcomment/montages.
Sans le / de fin du chemin source :
Avec le / de fin du chemin source :
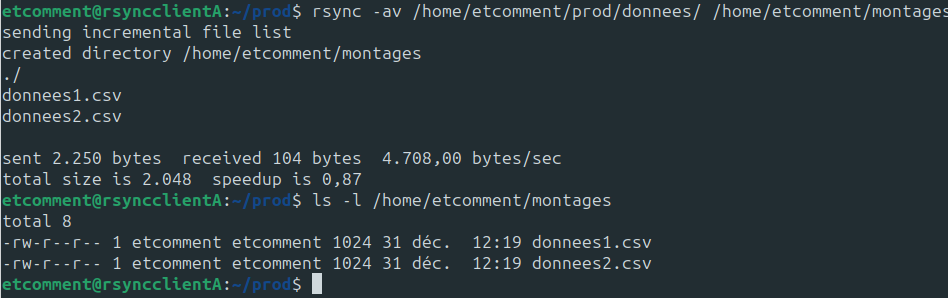
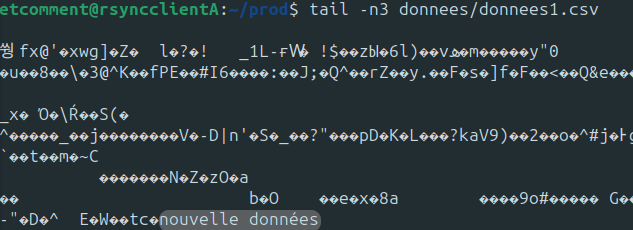
Maintenant, je vous propose de refaire une synchronisation après avoir modifié le fichier donnees1.csv. Nous allons lui ajouter “nouvelle données” à la fin du fichier.
echo "nouvelle données" >> donnees/donnees1.csv

Vous pouvez contrôler les dernières lignes écrites avec tail :
tail -n3 donnees/donnees1.csv
Nous relançons notre synchronisation :
rsync -av /home/etcomment/prod/donnees /home/etcomment/montages/

Est-ce que ça serait possible de ne pas copier le dossier cache ? Je n’ai pas besoin de ces données.
Eh bien rsync est un outil plutôt intelligent et adaptable. Et une option existe pour exclure une liste de fichiers ou un dossier complet : –-exclude.
rsync -av /home/etcomment/prod/donnees /home/etcomment/montages/ --exclude="cache"
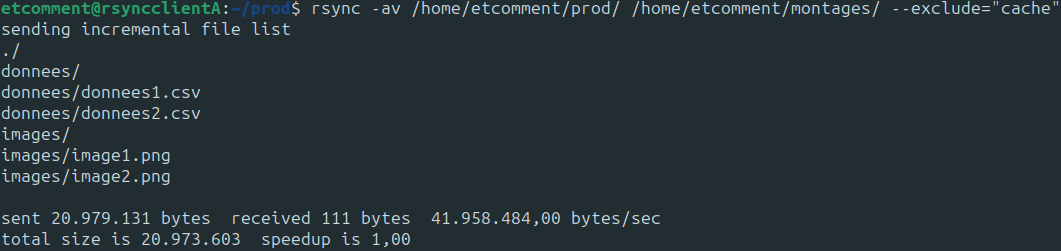
Toutes les données ont été copiées SAUF le dossier cache :

Synchronisation d’un dossier distant
Vous allez à présent voir en vidéo comment synchroniser un dossier, mais cette fois avec un dossier distant.
Vous avez pu voir dans la vidéo les éléments suivants :
La copie distante se fait en utilisant une option supplémentaire : l’option -e (ou --rsh=COMMAND), qui vous permet de spécifier le shell distant à utiliser. Dans votre cas, c’est SSH (secure shell) qui sera utilisé. Cette option vous permet aussi de préciser le port.
La syntaxe d’une synchronisation distante est celle-ci :
rsync -av -e ‘ssh -p 22’ /home/etcomment/prod etcomment@rsyncDestination:/var/sauvegardes/vm_source/
Le port SSH utilisé peut être modifié avec l’option -p et avec le port à utiliser, en fonction de la configuration du serveur SSH distant.
Utilisez Rsync pour effectuer vos sauvegardes
Savoir faire une synchronisation en local va beaucoup servir à Coffecao, qui monte un partage réseaux sur l’un de ses serveurs.
Mais pour les autres serveurs présents dans l’infrastructure, vous allez devoir montrer à Gwenaelle comment faire une synchronisation vers un serveur de sauvegarde distant.
Vous avez pu voir qu’avec la commande rsync et un paramètre supplémentaire, les synchronisations distantes peuvent être mises en place.
rsync -av -e ‘ssh -p 22’ /home/etcomment/prod etcomment@rsyncDestination:/var/sauvegardes/vm_source/
L’option -e (ou --rsh=COMMAND) vous permet de spécifier le shell distant à utiliser. Dans votre cas, c’est SSH (secure shell) qui sera utilisé. Cette option vous permet aussi de préciser le port.
Si c’est la première fois que vous vous connectez en SSH sur le serveur de sauvegarde, nous devriez avoir le message suivant qui apparaît :

Tapez yes puis validez avec la touche entrée, et rentrez votre mot de passe.
Planifiez la commande de sauvegarde avec crontab
Vous imaginez bien que vous n’allez pas pouvoir exécuter votre commande tous les jours manuellement sur chaque serveur.
Déjà, parce que ça peut prendre du temps, en fonction du nombre de serveurs, et surtout parce que, je vous le rappelle, les sauvegardes sont là pour fiabiliser le système en réduisant le risque de perte de données.
Et puis bon, Gwenaelle aussi a le droit de prendre des vacances !
Je vous propose de voir comment planifier l’exécution de la commande dans une tâche planifiée en utilisant l’outil crontab.
Commencez par regarder si une crontab existe avec la commande crontab et l’option -l, pour list.
crontab -l

Vous n’avez pas de tâches actuellement planifiées. Pas de soucis, à l’ajout d’une tâche, la crontab sera automatiquement créée.
Pour éditer votre tâche planifiée, exécutez crontab, mais cette fois avec l’option -e, pour edit.
crontab -e
Le système vous informe qu’il n’y a pas de crontab pour l’utilisateur et qu’il va en initialiser une. Crontab vous propose de choisir l’éditeur. Prenez celui avec lequel vous êtes le plus à l'aise.
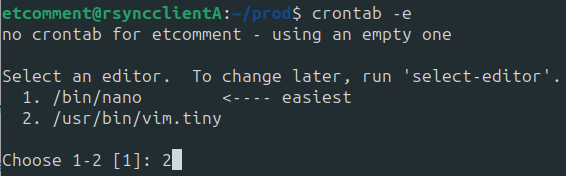
Vous êtes maintenant dans votre fichier de planification de tâche.
D’accord. Mais je fais quoi désormais pour exécuter ma synchronisation ?
Vous allez voir, je vais vous présenter très brièvement le fonctionnement de la planification avec crontab.
Pour ajouter votre commande rsync à votre crontab, il vous suffit d'ajouter une ligne en fin de fichier, avec dedans :
les minutes auxquelles la tâche s’exécute ;
les heures auxquelles la tâche s’exécute ;
les jours auxquels la tâche s’exécute ;
les mois auxquels la tâche s’exécute ;
les numéros de jours de la semaine auxquels la tâche s’exécute ;
la tâche à exécuter.
Par exemple, pour une exécution de la commande rsync, tous les soirs à 19 h du lundi au vendredi, vous pourrez écrire :
0 19 * * 1-5 rsync -av -e ‘ssh -p 22’ /home/etcomment/prod etcomment@rsyncDestination:/var/sauvegardes/vm_source/ >> /home/etcomment/sauvegardes.log

Restaurez les données du serveur distant vers la source
Pour compléter cette présentation à Gwenaelle de l’utilisation de rsync pour les sauvegardes, vous allez pouvoir lui montrer comment restaurer les données du serveur distant vers la source.
Vous avez pu voir dans cette vidéo tutorielle que pour restaurer une donnée, il suffit d’utiliser la commande rsync en inversant la source et la destination.
Mais dans le cas où vous souhaiteriez cibler un fichier précisément, vous pouvez utiliser les options –-include et –-exclude comme dans l’exemple suivant :
rsync -av -e 'ssh -p 22' etcomment@rsyncDestination:/var/sauvegardes/vm_source/prod/ /home/etcomment/prod/ --include="*/" --include="donnees2.csv" --exclude="*"
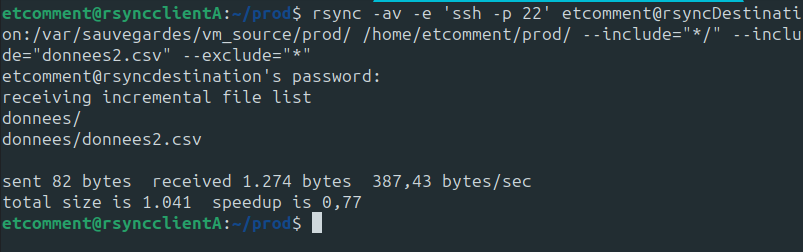
Dans cette commande, les options –-include sont utilisés avec 2 masques différents :
*/ : Qui dit à Rsync de cibler tous les dossiers.
donnees2.csv : Qui est le nom de notre fichier à restaurer.
Enfin, l’option –-exclude avec le masque * qui permet de lui dire de tout exclure par défaut.
À vous de jouer

Contexte
Vous implémentez une sauvegarde d’un des NAS de la nouvelle filiale d’EthicalIT en Inde. Celui-ci possède l’arborescence suivante :
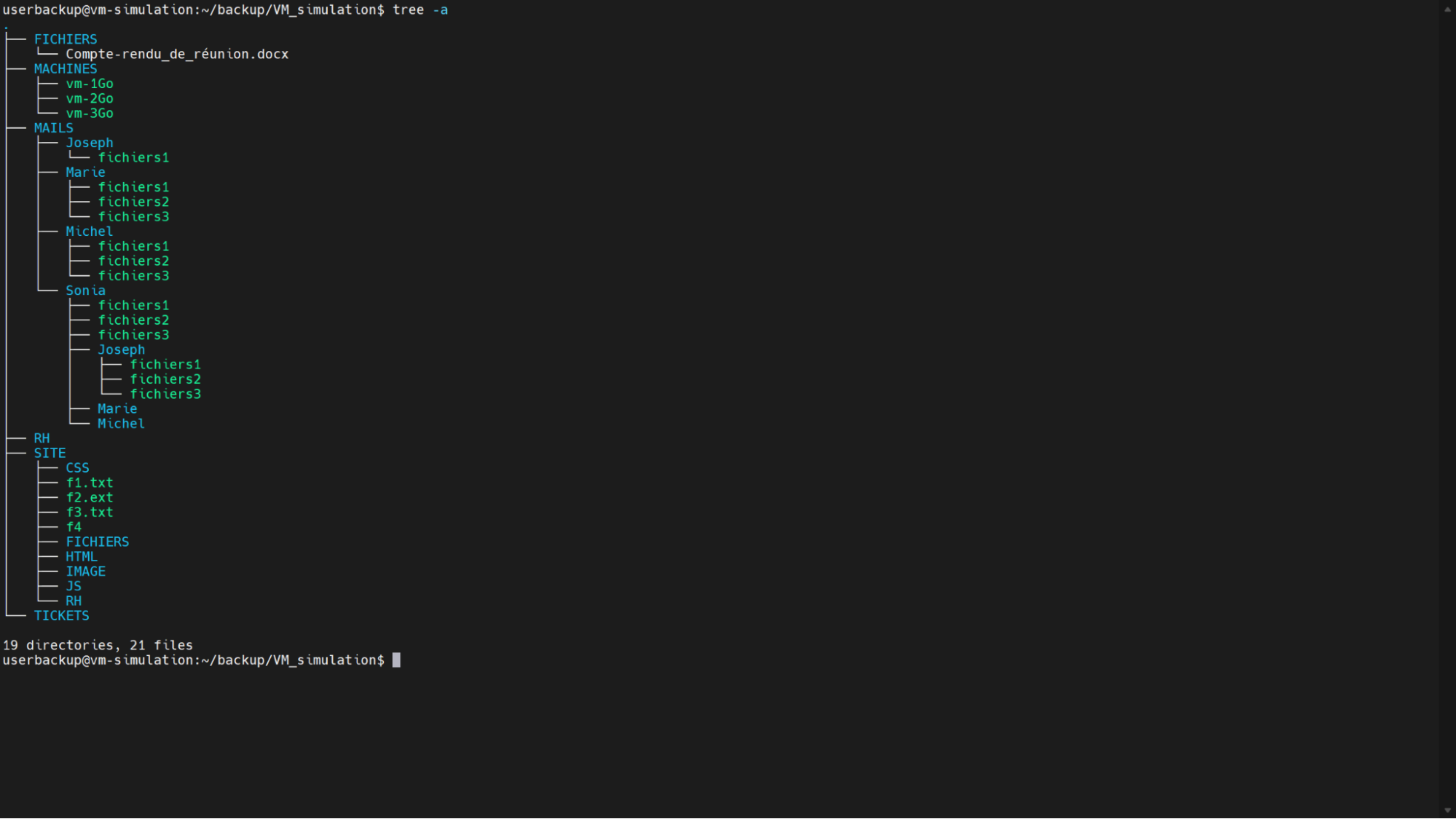
Votre sauvegarde devra être faite tous les premiers samedis du mois dans le dossier de sauvegarde d’un bucket S3 chez Amazon AWS.
Utilisateur SSH : ec2-user
Bucket S3 (nom d’hote) : fs-cee4feb7.efs.eu-north-1-cph1.amazonaws.com
Dossier de destination : /backup/
Exclusion de la sauvegarde : Dossier MAIL
Fichier de test à restaurer : ./MACHINES/vm-1go
Votre réplication est en place, il vous faut maintenant mettre la base de connaissance à jour avec la documentation de votre configuration.
Consignes
Préparez une documentation où vous préciserez les points suivants :
Commande rsync pour la sauvegarde des fichiers.
Planification dans la crontab.
Commande rsync pour la restauration d’un fichier.
En résumé
Rsync est un outil de synchronisation de fichier.
Il est possible d’utiliser rsync pour faire des sauvegardes différentielles ou incrémentales.
Rsync fonctionne de manière unidirectionnelle. Il faut inverser la source et la destination pour restaurer.
Vous pouvez exclure toute une arborescence avec l’option –-exclude et inclure des fichiers avec –-include.
Vous pouvez aussi bien utiliser rsync pour de la synchronisation locale qu’à travers SSH pour une synchronisation distante et sécurisée.
Vous pouvez utiliser Crontab pour planifier vos tâches de sauvegarde.
Vous avez démontré comment utiliser rsync pour faire des sauvegardes avec un système d’exploitation basé sur un noyau Linux. Vous allez à présent pouvoir montrer comment faire la même chose avec un OS Windows et l’utilisation de PowerShell.
