Construisez votre script de vérification
Félicitations, votre blueprint est finalisé et vous sentez toute l’énergie de votre équipe derrière vous, il ne vous reste plus qu’à vous atteler à l’analyse de données !
Camille vous envoie un message pour s'assurer que vous avez réussi à prendre en main les données. Quand vous lui répondez que vous n’avez pas encore commencé, elle vous conseille d’utiliser Quarto pour créer un script d’importation réutilisable et répétable.
Identifiez les 4 types de variables
Votre but est donc de construire des outils pour informer votre clientèle des températures mesurées dans chaque département. Il ne vous reste plus qu’à vous approprier le jeu de données, et en particulier les différentes variables.
Il existe quatre types de variables :
Quantitatif : les données sont numériques. Elles peuvent être continues (la température, par exemple) ou discrètes (nombre d’habitants par ville).
Spatial : les données sont des coordonnées géographiques. Dans le jeu de données vous avez la latitude et la longitude du chef-lieu du département.
Temporel : Les données sont des dates, des mois, des jours ou des numéros de semaines. Par exemple, la semaine 52 est plus proche d’un point de vue température de la semaine 1 que de la semaine 30.
Qualitatif : ce sont les données textuelles qui ne sont pas temporelles (les noms des mois ne sont pas des données qualitatives en tant que telles). Par exemple, dans le jeu de données, la région, le nom du département ou du chef-lieu sont des variables qualitatives.
Les données qualitatives peuvent être dichotomiques, c’est-à-dire deux modalités mutuellement exclusives. Dans le jeu de données, l’appartenance de la région à la France continentale l’est.
Les données qualitatives peuvent avoir un ordre sous-jacent, comme pour les tailles de vêtement S < M < L qui ne correspondent pas à l’ordre alphabétique, mais pas comme les noms de région ou de département dans le jeu de données.
Les données qualitatives peuvent avoir un nombre fini de modalités, ici le nom du département, par exemple. Dans ce cas, on parle de facteur. Les données telles que des avis sur des commerces, des titres de livres, ont un nombre infini de modalités, et sont traitées sous forme de chaîne de caractères. Ce type d’analyse ne sera pas présenté ici.
Pour résumer, dans le jeu de données, vous avez :
3 variables quantitatives continues :
tmin,tmaxettmoy;1 variable quantitative discrète :
densite_par_millier_habitants_km_carre_en_2018;1 variable temporelle :
date_obs;2 variables géographiques :
latitudeetlongitude;1 variable qualitative sous forme de nombre :
code_insee_departement;3 variables qualitatives non ordonnées :
departement,chef_lieuetregion;1 variable qualitative dichotomique :
continent.
Afin de réaliser une analyse reproductible et répétable, vous allez construire un script Quarto.
Liez les besoins aux variables
En reprenant votre blueprint, vous vous rendez compte que certaines données sont utilisables directement, comme le departement ou la region .
Par contre, vous n’avez pas dans le tableau des colonnes Mois ou Année, seulement des dates. Il vous faudra donc créer ces colonnes.
Les demandes d’Antoine sur les densités de population prennent deux formes :
la densité d'habitants au kilomètre carré ;
le niveau de densité.
Malheureusement vous n’avez d’origine que la densité d’habitants au km carré ; vous allez donc avoir besoin de modifier cette colonne et de créer une nouvelle colonne avec les niveaux de densité.
Après discussion, Antoine vous conseille de créer 4 niveaux :
surpeuplépour une densité supérieure à 20 000 habitants au km carré.très peuplépour une densité entre 20 000 et 5 000 habitants au km carré.peuplépour une densité entre 5 000 et 500 habitants au km carré.peu peuplépour une densité en dessous de 500 habitants par km carré.
Vous vous rendez compte que vous aurez aussi besoin des contours des départements. Heureusement, votre collègue Anna vous dépanne en vous donnant le lien vers le site géoservices, qui donne accès au découpage administratif du territoire français.
Après une dernière vérification au blueprint, vous vous sentez prêt à importer vos données dans R grâce à un script Quarto .
Créez votre script à partir du blueprint
Votre plan d’action est établi, il vous reste à travailler sur les données.
Pour commencer, dans RStudio vous allez créer un nouveau document Quarto.
Il est conseillé de nommer le fichier d’import par un nom simple, informatif et numéroté tel que 01_import_des_donnees_de_temperature.qmd.
Dans ce script vous pouvez décider de compléter l’en-tête pour donner à votre rapport un titre, un auteur, une date et un format de sortie. Par exemple :
---
title: "Import et vérification des données de températures"
author: "Marie Vaugoyeau"
date: "2024/01/01"
format:
pdf:
toc: true
number-sections: true
editor: visual
---Charger les packages
L’une des bonnes pratiques est de mettre dans le premier chunk l’import des packages utilisés. Ici vous allez devoir utiliser le {tidyverse} ; il faut donc l’installer sur votre PC et le charger dans l’environnement à chaque session grâce à la fonction library() .
# import des packages
```{r}
library(tidyverse)
```Le {tidyverse} , c’est quoi ?
Le {tidyverse} est un ensemble de packages open-source développé pour rendre l’analyse de données plus facile, plus rapide et surtout plus fun. Les fonctions qui composent ces packages ont une philosophie, une démarche similaire, et des noms d’arguments communs, ce qui facilite leur apprentissage.
Les packages que nous utiliserons dans ce cours sont :
{dplyr}pour la manipulation des données (filtrer, trier...) – à ne pas confondre avec{tidyr}qui manipule le format du jeu de données ;{readr}pour l’import des fichiers (format CSV et texte pris par défaut) ;{forcats}pour la transformation des facteurs ;{stringr}pour la modification des chaînes de caractères (du texte) ;{ggplot2}pour la visualisation des données ;{purrr}pour l’application de blocs de données sur plusieurs objets. Les fonctions qui le composent remplacent avantageusement les boucles ;{lubridate}pour le travail sur les dates.
Importer les données
Le fichier est un format csv , la fonction de read_csv() du package {readr} appartenant au {tidyverse} est adaptée à cet import.
Le travail sous forme de projet permet d’enraciner le chemin d’accès du fichier au répertoire et de ne pas avoir besoin de l’expliciter.
# import des données
```{r}
donnees_temperature <- read.csv(
"donnees_temperature.csv"
)
```Vérifier le format des données
Une fois les données importées, il faut vérifier qu'elles soient bien chargées.
Pour cela, la fonction glimpse() de {dplyr} permet d’avoir un résumé de ces données.
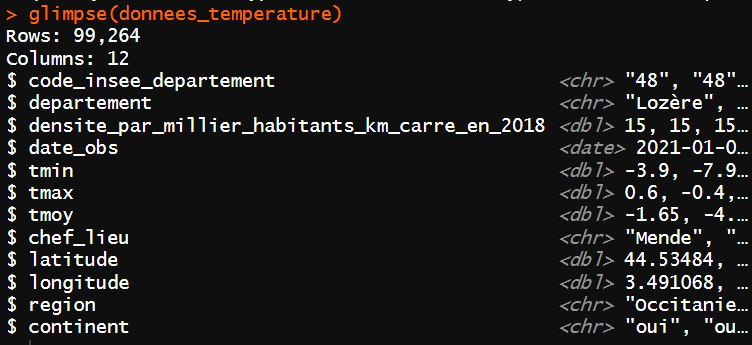
Il est nécessaire de vérifier que les variables chargées dans l’environnement et issues du jeu de données ont bien la nature attendue.
Les cinq variables qualitatives ont été importées sous forme de <chr> , c’est-à-dire des chaînes de caractères. Ici le format chaîne de caractères ne correspond pas à la réalité, car le nombre de modalités de chacune de ces variables est fini. Il faut donc à l’import utiliser l’argument col_types dans la fonction read_csv() , qui permet de lister le format des données avec f pour facteur , d pour double – soit une valeur numérique non entière, D pour Date .
donnees_temperature <- read_csv(
"donnees_temperature.csv",
col_types = "ffdDdddfddff"
)Je croyais que la colonne departement était sous forme numérique, pourquoi a-t-elle été importée sous forme de chaîne de caractères ?
Si vous regardez la liste des modalités de cette colonne, vous verrez2A et 2B pour la Corse, ce qui fait passer la colonne comme du texte pour R.
De la même manière, les coordonnées géographiques, chargées sous forme dbl , donc une valeur numérique avec décimales, doivent être transcrites comme telles grâce à la fonction st_as_sf() du package {sf} qui permet la manipulation d'objets géographiques.
donnees_temperature <- donnees_temperature |>
sf::st_as_sf(coords = c("longitude", "latitude"))Malheureusement, lorsque vous utilisez la fonction sur votre jeu de données, R vous renvoie le message : Erreur dans st_as_sf.data.frame(donnees_temperature, coords = c("longitude", : missing values in coordinates not allowed
Il faut donc commencer par traiter les données manquantes avant de finir la mise en forme de votre jeu de données.
Traitez la problématique des données manquantes
Les données manquantes, représentées parNA, peuvent avoir plusieurs origines :
La donnée n’est pas compatible. Par exemple, une personne entre son numéro de téléphone sous forme de texte au lieu de le mettre sous format numérique. Dans ce cas le système ne prend pas en charge la réponse et la qualifie en
NApourNot Applicable.La donnée n’existe pas. Par exemple la personne n’a pas de numéro de téléphone ; dans ce cas, le système la qualifie de
NApourNot Available.La donnée existe mais n’a pas été communiquée. Par exemple la personne a refusé de donner son numéro ; dans ce cas, le système la qualifie de
NApourNo Answer.
Dans tous les cas, la seule information transmise est que la donnée n’est pas disponible. Il n’est pas toujours possible de cerner l'origine du problème, mais cela n’empêche pas d’agir.
Il faut commencer par se demander ce que signifie cette absence et comment elle va impacter notre système.
Dans le jeu de données des températures, l’absence des données empêche la transformation en coordonnées géographiques.
Pour commencer, il faut quantifier et localiser les valeurs manquantes.
Le package {naniar} est spécialement adapté à la visualisation des données manquantes. La fonction gg_miss_upset() permet de représenter sur un graphique les variables qui ont des données manquantes et le lien entre les colonnes.
naniar::gg_miss_upset(donnees_temperature)Ce graphique est composé de deux parties :
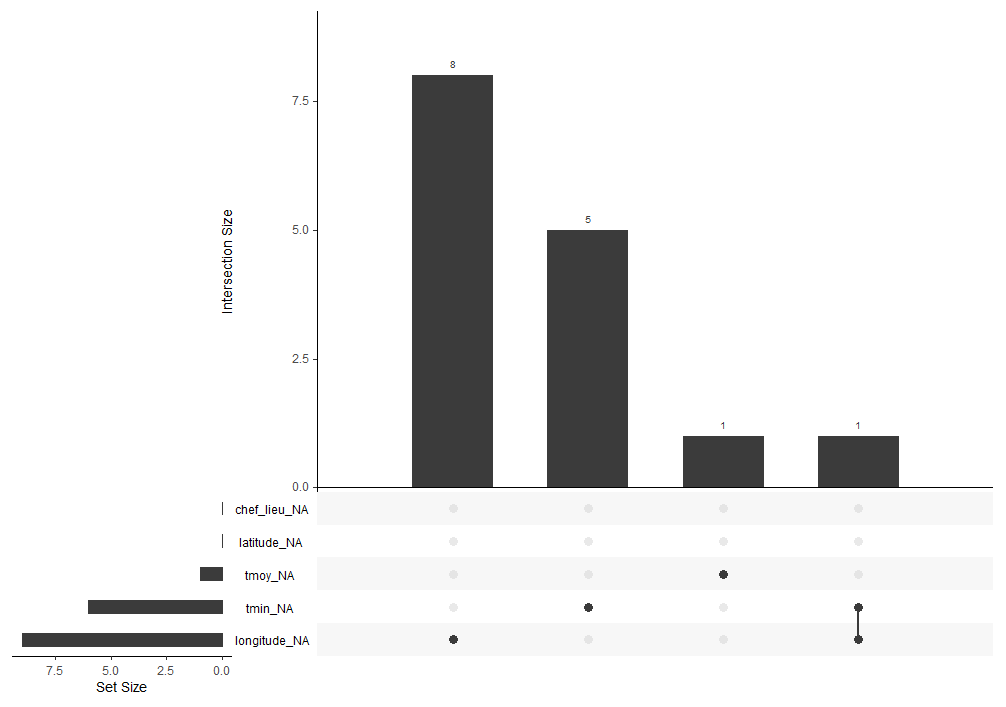
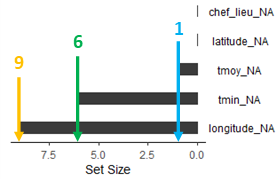
En bas à gauche, le diagramme en barres horizontales montre le nombre de données manquantes par variable : il manque 9 données pour la longitude, 6 pour la température minimum et 1 pour la température moyenne.
Il ne manque pas de valeur pour latitude ou chef-lieu.
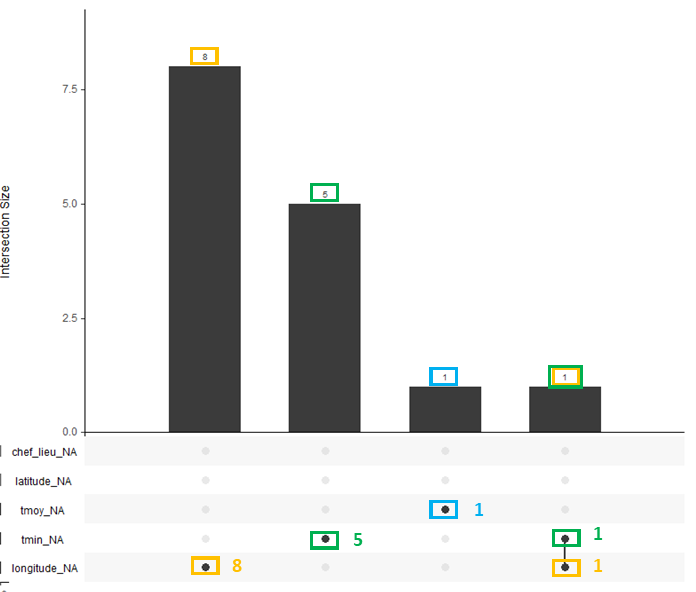
Le diagramme en barres verticales au centre montre la distribution des lignes. Pour 8 des valeurs manquantes de la longitude, il n’y a pas d’autres valeurs manquantes sur les mêmes lignes, comme pour 5 des 6 lignes qui ont des valeurs manquantes sur la température minimum. La ligne avec la température moyenne manquante n'a pas d'autre valeur manquante. Par contre, pour une ligne, il manque la température minimum et la longitude.
Une fois que les données manquantes sont localisées, plusieurs solutions sont possibles :
1. Remplacer la donnée manquante par :
La vraie valeur s’il est possible de la retrouver. C’est le cas avec les coordonnées dans notre situation.
Une valeur de remplacement :
Déterminée à partir des autres données de la variable : moyenne, médiane, minimum, maximum…
Modélisée à partir des autres variables grâce à une régression linéaire, une analyse en composantes principales…
2. Ne pas remplacer la donnée mais garder leNA .
3. Supprimer la ligne ou la colonne concernée. Cette solution est la moins envisageable et ne doit être mise en place que si les deux autres ne sont pas possibles.
Les données manquantes seront remplacées dans le chapitre suivant lors des modifications des données.
À vous de jouer

Contexte
Votre première version du blueprint est validée par vos collègues de “A tout chemin”. Vous pouvez en retrouver une version à cette adresse.
Il vous reste à créer le script Quarto qui va vous permettre de faire l’analyse des données envoyées par Camille.
Consignes
Vous allez pouvoir faire le lien entre les données disponibles et les données nécessaires listées dans le blueprint. N’hésitez pas à lister ce qui vous manque !
En résumé
Il existe différents types de données : qualitatives, quantitatives, temporelles et spatiales. Chacune a des caractéristiques qui lui sont propres.
Lors de l’importation, il est important de vérifier que les données chargées soient du bon type.
Un projet et un script Quarto sont indispensables pour permettre une analyse de données reproductible, répétable et réutilisable.
Les données manquantes doivent être traitées au cas par cas, l’idéal étant de les remplacer par des valeurs cohérentes.
Comme nous avons vérifié l’unicité des couples ville - coordonnées géographiques, il faut maintenant vérifier les autres variables.
