Appliquez des modifications avancées
 Bravo ! Camille vous félicite pour l’import des données dans RStudio. Elle aimerait maintenant que vous vérifiiez la présence de toutes les données utiles à votre mission grâce au blueprint que vous avez rédigé… Voyons cela ensemble !
Bravo ! Camille vous félicite pour l’import des données dans RStudio. Elle aimerait maintenant que vous vérifiiez la présence de toutes les données utiles à votre mission grâce au blueprint que vous avez rédigé… Voyons cela ensemble !
Identifiez les données nécessaires aux besoins
Après avoir chargé le jeu de données dans votre environnement R, il vous reste à vérifier que les données fournies permettent de répondre aux demandes du blueprint. Pour cela, vous allez explorer les données et les comparer à l’attendu.
En liant les données disponibles aux besoins, vous vous êtes rendu compte que vous aviez déjà :
les températures moyenne, minimale et maximale journalières sur 6 ans ;
le nom du chef-lieu et les coordonnées géographiques, le département et la région associés ;
la présence du département sur le continent ou non.
Mais que vous aviez besoin de :
multiplier la densité de population par mille ;
créer une variable qualitative de densité de population à partir de la variable quantitative de densité
Résumez vos données à l’aide de tableaux
Grâce à la fonction summary() du package {base} , vous pouvez afficher un aperçu des données. Cela vous permet de voir qu’il y a des valeurs manquantes uniquement pour les variables tmin , tmoy et longitude .
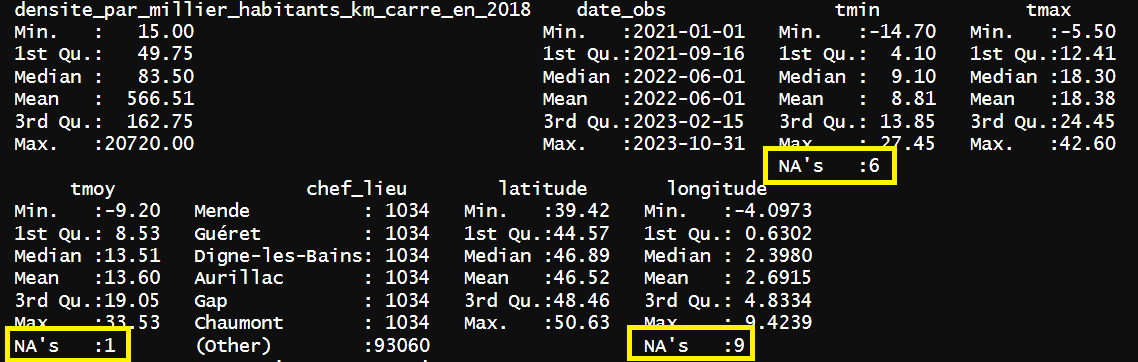
Vous aurez donc des remplacements à ne faire que sur ces colonnes-là.
En lisant bien le blueprint, vous vous rendez compte que vous attendez les données de température pour les 101 départements de France pendant 6 ans. Vous calculez donc rapidement que vous devriez avoir : 101 * 6 * 365 = 221 190.
La fonction {glimpse} de {dplyr} vous permet de savoir que le jeu de données fait 99 264 lignes pour 12 colonnes. Les mêmes informations sont présentes dans l’onglet Environment .
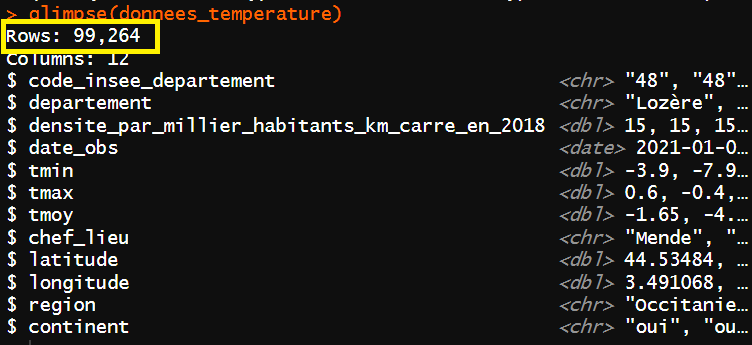
Il vous manque donc des lignes. Pour les identifier, vous allez avoir besoin d’explorer vos données. C’est à cela que sert l’analyse descriptive univariée décrite dans la prochaine partie.
Créez de nouvelles colonnes
Dans le blueprint, vous avez noté que la variable attendue était la densité d'habitants au km², mais ne l’avez que par milliers d’habitants ; vous allez donc devoir la modifier en multipliant par mille le nombre présent.
Les données de densité sont en milliers d’habitants par km², il faut les remettre en habitants par km². Afin de ne pas multiplier plusieurs fois la colonne, il est conseillé de :
Créer une nouvelle colonne avec
mutate()du package{dplyr}contenant les valeurs multipliées par 1 000. Cette fonction permet de modifier des colonnes existantes et de créer de nouvelles colonnes.Supprimer la colonne d’origine grâce à
select()du même package. Cette fonction permet de sélectionner les colonnes à conserver ou à supprimer.Vérifier le résultat grâce à
glimpse().
donnees_temperature <- donnees_temperature |>
mutate(densite_humaine_par_km_carre = densite_par_millier_habitants_km_carre_en_2018 * 1000) |>
select(- densite_par_millier_habitants_km_carre_en_2018)
# vérification
glimpse(donnees_temperature)Nous aurions pu faire cela en une fois en modifiant la colonne d’origine ?
Oui effectivement, mais le nom de la colonne doit être modifié pour correspondre à la réalité. Attention, si le code est lancé trois fois, les données seront multipliées par 1 000 * 1 000 * 1 000 !
En passant par une nouvelle colonne, il n’y a pas de risque.
donnees_temperature <- donnees_temperature |>
mutate(densite_par_millier_habitants_km_carre_en_2018 = densite_par_millier_habitants_km_carre_en_2018 * 1000)
# renommer la colonne
donnees_temperature <- donnees_temperature |>
rename(densite_humaine_par_km_carre = densite_par_millier_habitants_km_carre_en_2018)Requalifiez vos données
En résumé, voilà ce que nous avons fait :
Selon le blueprint, l’étude nécessite une variable qualitative sur la densité de population avec quatre modalités :
surpeuplé,très peuplé,peupléetpeu peuplé.La création de la variable demandée à partir de la colonne
densite_par_millier_habitants_km_carre_en_2018est réalisée grâce à la fonctioncase_when()de{dplyr}. Cette fonction associe une valeur à une colonne en fonction des valeurs d’une ou plusieurs colonnes.Ici nous allons utiliser uniquement les valeurs de la colonne
densite_par_millier_habitants_km_carre_en_2018.Si la densité est supérieure à 20 000 habitants au km², le département est
surpeuplé, entre 20 000 et 5 000 habitants au km² il esttrès peupléet en dessous de 500 habitants par km² il estpeu peuplé.
donnees_temperature <- donnees_temperature |>
mutate(
densite_pop = case_when(
densite_humaine_par_km_carre > 20000000 ~ "surpeuplé",
densite_humaine_par_km_carre > 5000000 ~ "très peuplé",
densite_humaine_par_km_carre > 50000 ~ "peuplé",
TRUE ~ "peu peuplé"
)
)Remplacez les données manquantes
Vous avez trois variables avec des données manquantes :
la longitude : 7 lignes concernées dont 1 à laquelle il manque aussi la température minimale ;
la température moyenne : 1 ligne ;
la température minimale : 6 lignes concernées dont 1 à laquelle il manque aussi la longitude.
Comme il n'y a qu’une seule variable pour laquelle il manque des données sur plusieurs colonnes, on ne va pas la traiter différemment. Par contre, dans le cas où il y aurait beaucoup de lignes qui ont les mêmes données manquantes, un temps d’investigation sur les données serait nécessaire.
Dans le cas des données de longitude manquantes, ces données vont pouvoir être récupérées à partir des autres lignes. C’est donc le cas idéal, où les données manquantes peuvent être remplacées par la vraie valeur.
Dans le cas des températures, il n’est pas possible de remplacer par la vraie valeur, mais les valeurs manquantes vont être calculées à partir des données des jours qui précèdent et qui suivent.
Remplacez les longitudes manquantes
Pour récupérer les coordonnées manquantes, il faut créer un sous-dataset avec les chefs-lieux et les coordonnées géographiques.
En amont, il faut tout de même vérifier qu’une ville n’est associée qu’à un seul couple de coordonnées en utilisant les fonctions :
distinct(), qui permet de supprimer les doublons ;count(), qui permet de compter le nombre de répétitions ;filter(), qui permet de trouver les villes concernées par les deux vecteurs.
Toutes ces fonctions sont du package {dplyr} .
donnees_temperature |>
filter(!is.na(longitude)) |>
distinct(chef_lieu, longitude, latitude) |>
count(chef_lieu) |>
filter(n > 1)Toutes les villes ont bien un seul couple de coordonnées, sauf les 7 lignes avec les valeurs manquantes. Avec les mêmes fonctions, vous allez pouvoir créer une table de correspondance ville - coordonnées, et remplacer les coordonnées manquantes.
table_ville_coordonnees <- donnees_temperature |>
filter(!is.na(longitude)) |>
distinct(chef_lieu, longitude, latitude)
# jointure pour créer la nouvelle colonne corrigée
donnees_temperature_longitude_corr <-
inner_join(
donnees_temperature,
table_ville_coordonnees,
by = join_by(chef_lieu, latitude),
suffix = c(".origine", ".corrige")
)
# vérification de la correction
donnees_temperature_longitude_corr |>
filter(is.na(longitude.origine))
# suppression de la colonne d'origine et renommage de la colonne corrigée
donnees_temperature <- donnees_temperature_longitude_corr |>
select(- longitude.origine) |>
rename(longitude = "longitude.corrige")
# vérification
naniar::gg_miss_upset(donnees_temperature)Félicitations, vous avez remplacé les données de longitude manquantes par les vraies valeurs !
Remplacez la température moyenne manquante
La température moyenne manquante va être remplacée par la moyenne des températures moyennes enregistrées dans le même département la veille et le lendemain.
Pour cela, il faut que le jeu de données soit trié selon le département et le jour d’observation grâce à la fonction arrange() de {dplyr} . Puis que le numéro de ligne concerné soit trouvé grâce à l’utilisation de la fonction rowid_to_column() du package {tibble} qui crée une colonne contenant les numéros de lignes et l’utilisation de la fonction filter() déjà vue. Enfin, la valeur manquante est remplacée par la moyenne entre les valeurs juste avant et juste après.
# tri sur les données pour avoir les jours qui se suivent dans chaque département
donnees_temperature <- arrange(donnees_temperature, departement, date_obs)
# recherche du numéro de la ligne pour laquelle la température moyenne est manquante
num_ligne <- donnees_temperature |>
rowid_to_column() |>
filter(is.na(tmoy))
# remplacement de la valeur manquante par un calcul de la température de la veille et du lendemain
donnees_temperature[num_ligne$rowid, "tmoy"] <- (
donnees_temperature[(num_ligne$rowid - 1), "tmoy"] +
donnees_temperature[(num_ligne$rowid + 1), "tmoy"]
)/2
# vérification
donnees_temperature |>
filter(is.na(tmoy)) Bravo, vous avez remplacé la valeur manquante de la température moyenne par une valeur calculée probable !
Malheureusement cette méthode n’est pas l’idéal quand plusieurs lignes sont concernées.
Remplacez les températures minimales manquantes
Lorsque plusieurs lignes sont concernées, il vaut mieux utiliser les fonctions lag() et lead() du package {dplyr} qui permettent de récupérer les lignes avant ( lag ) ou après ( lead ) un emplacement.
donnees_temperature <- donnees_temperature |>
mutate(
tmin = case_when(
is.na(tmin) ~ (lag(tmin) + lead(tmin))/2,
TRUE ~ tmin
)
)
# vérification
summary(donnees_temperature)Félicitations, vous n’avez plus de valeurs manquantes !
Il ne vous reste plus qu’à exporter votre jeu de données complété pour le sauvegarder : write_csv(donnees_temperature, "donnees_temperature_completees.csv")
À vous de jouer

Contexte
Lors de l’import des données et la comparaison avec le blueprint, vous vous êtes rendu compte que la colonne "Nombre d’habitants" n’était pas directement utilisable, et qu’il vous manquait la colonne pour le niveau de densité de population.
Consignes
Vous allez donc devoir modifier et créer des colonnes.
L'aperçu des données vous a aussi amené à vous rendre compte de la présence de valeurs manquantes. Avant de vous lancer dans l’analyse, vous devez vous en occuper en les remplaçant si possible.
En résumé
Le traitement des données suit un cycle itératif de vérification, modification, validation des données qui permet une amélioration continue.
Il est important de savoir ce qu’on attend des données (nombre et type) pour les vérifier.
La modification des données est facile avec les fonctions de
{dplyr}.Il existe plusieurs méthodes pour remplacer les valeurs manquantes.
Les données sont maintenant prêtes pour l’analyse descriptive. Avant de vous lancer dans l’analyse univariée, évaluez vos connaissances avec le quiz clôturant cette partie !
