Manipulez des variables quantitatives
La liste des valeurs des variables quantitatives vous donnera peu d'informations. Par exemple, vous pouvez passer du temps à lire les températures de janvier et de juin, mais vous n’en tirerez pas nécessairement d’information. Par contre, le calcul des moyennes de chaque mois peut vous permettre de les comparer.
L’analyse univariée quantitative permet de mieux comprendre les données, en ayant une vision globale grâce aux paramètres calculés, tels que la moyenne, mais aussi d’identifier les erreurs.
Les variables quantitatives sont souvent considérées commes les variables les plus naturelles. En effet, la prise de température, le calcul de distance, sont des éléments de la vie courante.
Les variables quantitatives peuvent être discrètes, comme le nombre de départements, ou continues, comme la température.
Qu’elles soient continues ou discrètes, le but est d’étudier la distribution des données et d’estimer des paramètres qui les résument.
Il existe différents types de paramètres qui décrivent :
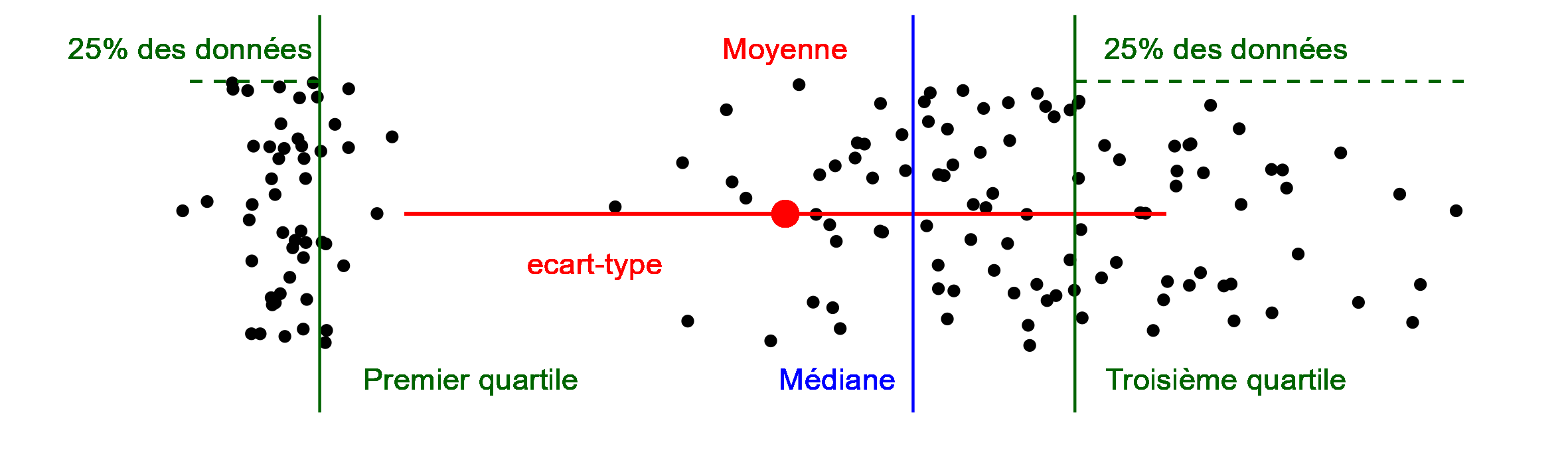
le centre, avec le calcul de la moyenne ou la détermination de la médiane ;
la dispersion, comme l’écart-type, la variance, l'étendue ou l’utilisation des quartiles.
Les paramètres qui décrivent le centre des données
La moyenne permet de calculer le centre des données. Il en existe différentes sortes si les données n’ont pas la même importance, mais ce n’est pas le cas dans notre jeu de données. Nous allons donc calculer la moyenne arithmétique, qui est la plus utilisée ; c’est la plus classique, qui revient à donner le même poids à chaque individu. Dans R elle se calcule grâce à la fonction mean() du package {base} .
Par exemple, mean(donnees_temperature$tmin) .
La médiane permet de positionner le centre des données sans calcul. Les données doivent être triées, et la médiane est positionnée afin d’avoir 50 % des données au-dessus et 50 % des données en dessous de cette valeur. Si on a un nombre impair, c’est directement la valeur, sinon c’est la moyenne entre les deux valeurs centrales.
Par exemple, prenons les températures de différents départements :
Avec 5 températures : 12, 17, 13, 15 et 11, la médiane est 13. 11 et 12 sont en dessous, 15 et 17 au-dessus.
Avec 6 températures : 19, 12, 17, 13, 15 et 11, la médiane est 14, car située à égalité entre 13 et 15.
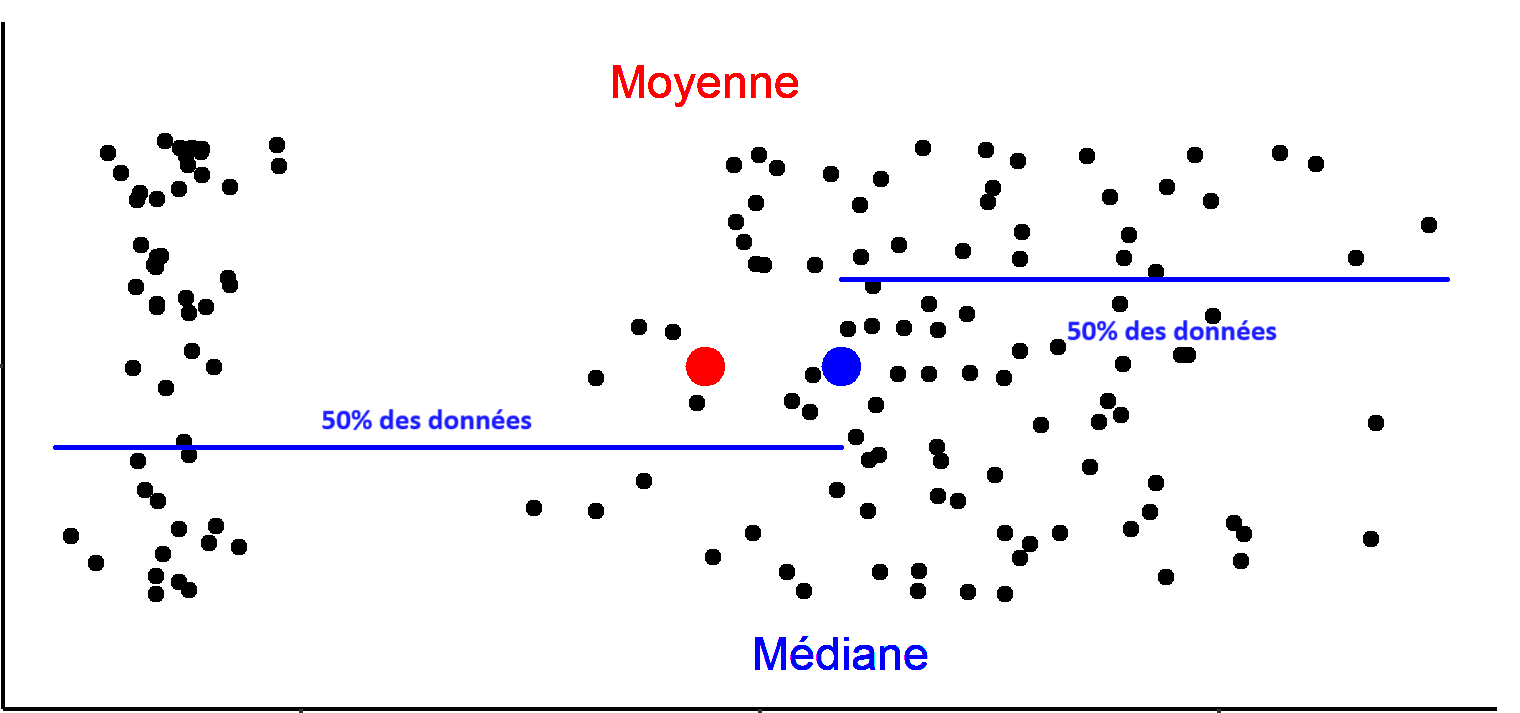
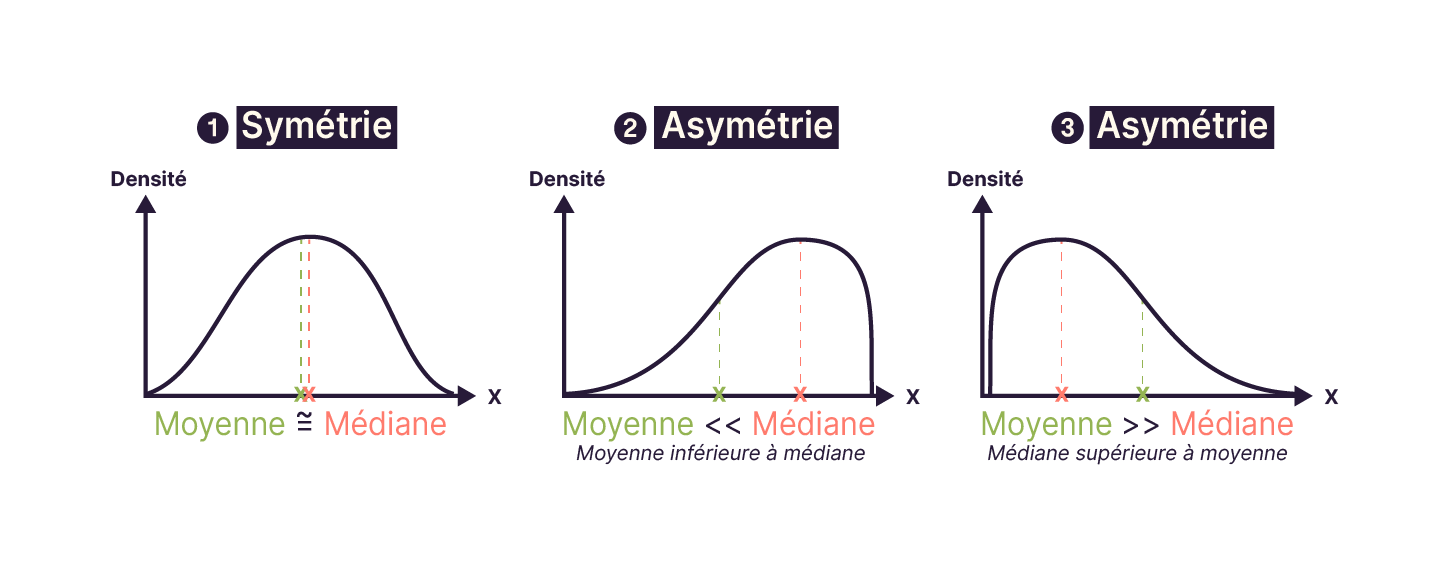
Comparer les valeurs de la moyenne et de la médiane permet d’avoir un aperçu de la symétrie des données :
Si la médiane et la moyenne sont similaires, les données sont distribuées symétriquement autour du centre.
Si la médiane est largement supérieure à la moyenne, il y a beaucoup de grandes valeurs et quelques très petites.
Si la médiane est largement inférieure à la moyenne, il y a beaucoup de petites valeurs et quelques très grandes.
Les paramètres qui étudient la dispersion des données
Connaître la position du centre des données n’est pas suffisant pour les décrire. En effet, il faut aussi regarder à quel point les données sont plus ou moins éloignées du centre. C’est l’étude de la dispersion. Il existe plusieurs paramètres qui permettent de calculer la dispersion, du plus simple au plus complexe :
Le paramètre le plus simple à calculer est l’étendue, qui prend comme résultat la soustraction de la plus petite des valeurs à la plus grande :
e = max - min. Pour calculer l’étendue avec R, il faut utiliser les fonctionsmin()etmax()du package{base}.L’écart-type et la variance sont liés l’un à l’autre :
var = 𝜎 ². L’écart-type a la même unité que les mesures, et mesure la dispersion de chaque valeur par rapport à la moyenne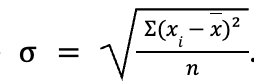
Formule Dans R, sa fonction est
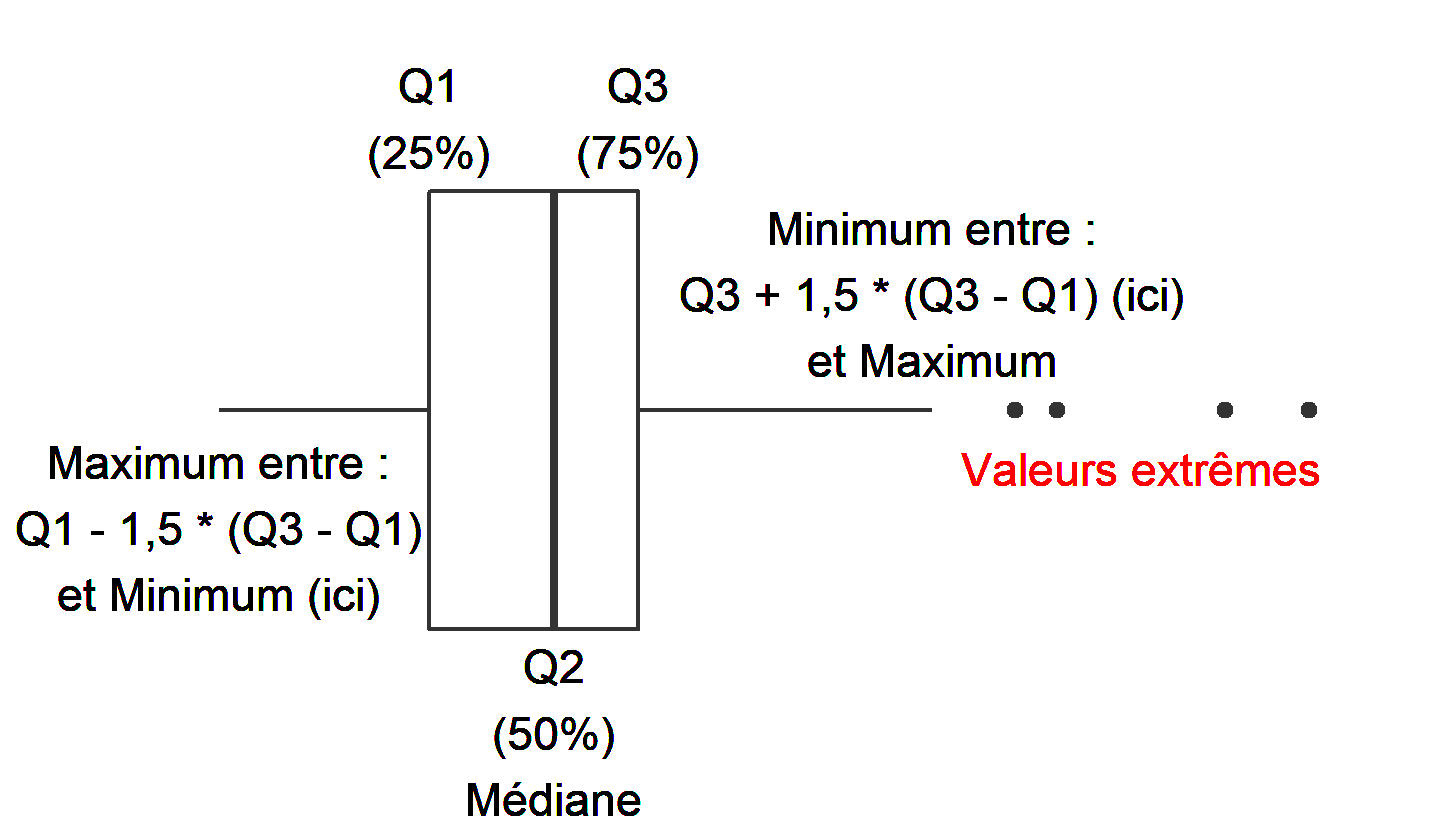
sd()du package{stats}. La variance est l’écart-type au carré, dans R, la fonction estvar()du même package.Enfin, les quartiles sont les quantiles qui découpent les données en quatre groupes de même taille. Il y a 25 % des valeurs en dessous et 75 % au-dessus du premier quartile, Q1, et l’inverse pour le troisième, Q3. Pour le deuxième quartile, Q2, il y a 50 % des valeurs en dessous et au-dessus.
50 % au-dessus et 50 % en dessous ? Cela me rappelle quelque chose !
En effet, la médiane est le deuxième quartile.
La détermination des valeurs extrêmes
Les valeurs extrêmes sont des données intéressantes. En effet, elles peuvent provenir d'erreurs (de mesure, de frappe…) ou de cas particuliers. Si une valeur extrême est liée à une erreur, il faut choisir entre la corriger ou la supprimer, et dans ce cas la traiter comme une valeur manquante. Si une valeur extrême est liée à un cas particulier, par exemple la densité de population sur Paris, il faut choisir entre la conserver ou réaliser l’analyse sans.
Les valeurs extrêmes vont être détectées grâce aux quartiles. Lorsqu’une valeur est plus faible que Q1 - 1,5 (Q3-Q1) ou plus grande que Q3 + 1,5 (Q3-Q1), Q3-Q1 est appelé l’écart interquartile.
Vous avez acquis des connaissances sur la nature des paramètres qui résument les données quantitatives, il ne reste plus qu’à les mettre en place.
Menez une analyse descriptive sur les données quantitatives
Dans le jeu de données lié à la mission, vous avez quatre variables quantitatives : les données de températures ( tmin , tmoy et tmax ) et la densité de population.
Dans la vidéo, les différentes valeurs sont calculées sur la variable tmin .
Voici les lignes de code utilisées :
La moyenne :
mean(donnees_temperature$tmin)La médiane :
median(donnees_temperature$tmin)L’étendue :
max(donnees_temperature$tmin) - min(donnees_temperature$tmin)L’écart-type :
sd(donnees_temperature$tmin)La variance :
var(donnees_temperature$tmin)Les quartiles :
quartiles <- quantile(donnees_temperature$tmin)Les valeurs extrêmes :
minimales :
donnees_temperature |> filter(tmin < (quartiles[2] - 1.5*(quartiles[4] - quartiles[2])))maximales :
donnees_temperature |> filter(tmin > (quartiles[4] + 1.5*(quartiles[4] - quartiles[2])))
Cela prend du temps de le faire sur toutes les variables, ce n’est pas possible d’aller plus vite ?
Si, effectivement.
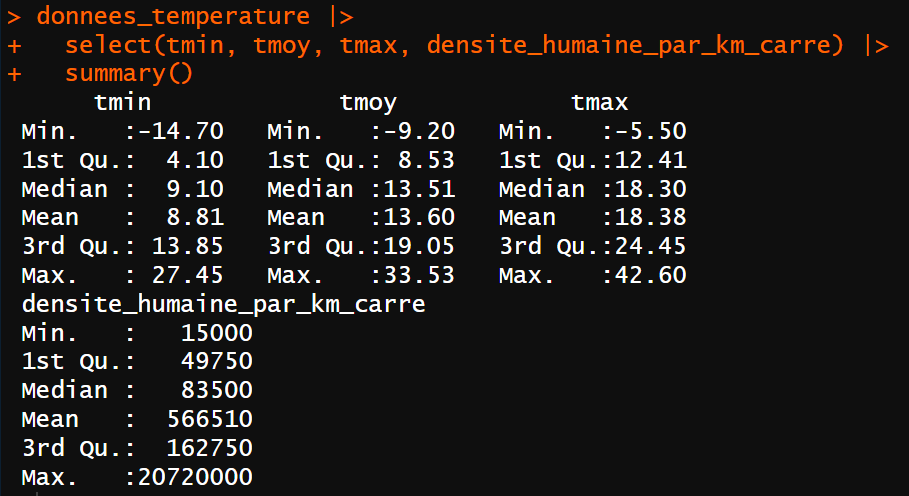
La première solution est d’utiliser la fonction summary() du package {base} pour le calcul des valeurs minimales, maximales, des quartiles et de la moyenne : summary(donnees_temperature) .
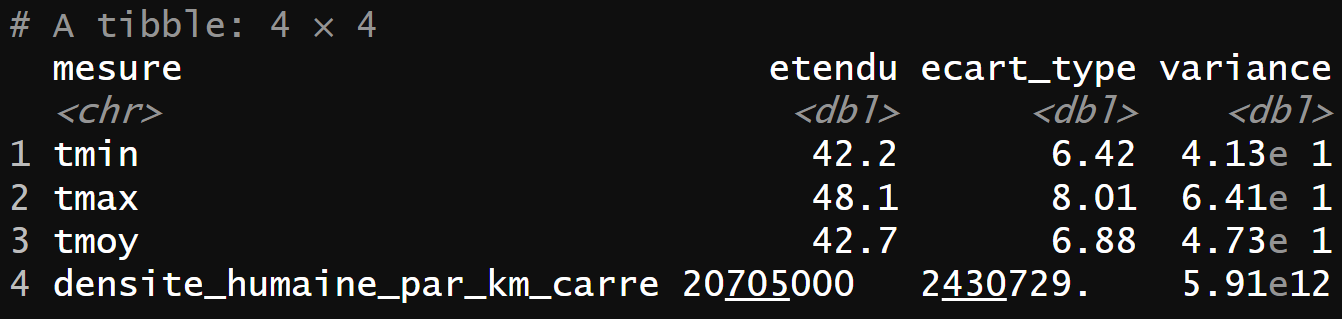
Pour avoir d’autres caractéristiques que celles disponibles dans summary() , il faut utiliser les fonctions suivantes :
summarise()pour calculer les autres valeurs : écart-type, variance et étendueaccross()pour sélectionner les colonnes d’intérêt.
Ces deux fonctions viennent du package {dplyr} qui appartient au {tidyverse} .
Ensuite les fonctions pivot_longer() et everything() permettent de mettre sous la forme d’un tableau à double entrée comme détaillé ci-dessous :
donnees_temperature |>
summarise(
across(
.cols = c(tmin:tmoy, densite_humaine_par_km_carre),
.fns = list(
etendu = ~ max(.x) - min(.x),
ecart_type = sd,
variance = var
),
.names = "{col} {fn}"
)
) |>
pivot_longer(
everything(),
cols_vary = "slowest",
names_to = c("mesure", ".value"),
names_pattern = "(.+) (.+)"
)
Vous avez maintenant une bonne connaissance des données quantitatives du jeu de données ; en particulier, vous vous attendez à ce que la densité de population soit asymétrique, et que les trois mesures de température soient plutôt symétriques. La représentation va permettre de valider cela.
Représentez vos données quantitatives
La première représentation des données apparue avec l’écriture est la réalisation de tableaux.
Vous avez déjà vu précédemment comment créer un tableau résumé avec summary() et summarise() .
Le graphique par excellence pour visualiser la distribution des données quantitatives est l’histogramme, en calculant les effectifs dans chaque intervalle. Un intervalle, c’est un ensemble de points entre deux bornes. Les intervalles sont appliqués par défaut, mais vous pouvez les faire varier en fonction des besoins grâce aux arguments bins ou binwidth .
C’est le package {ggplot2} du {tidyverse} qui va être utilisé pour faire les représentations graphiques. Il fonctionne par couche et ne fait pas de présupposition sur le type de graphique à créer. Il faut donc paramétrer ce que l’on veut représenter grâce à la fonction aes() , et le type de représentation grâce aux fonctions commençant par geom_ .
ggplot(donnees_temperature) + # choix du jeu de données
aes(x = tmin) + # choix de la variable à représenter
geom_histogram() + # choix du type de graphique
theme_classic() # choix d'un thème pour la représentation graphique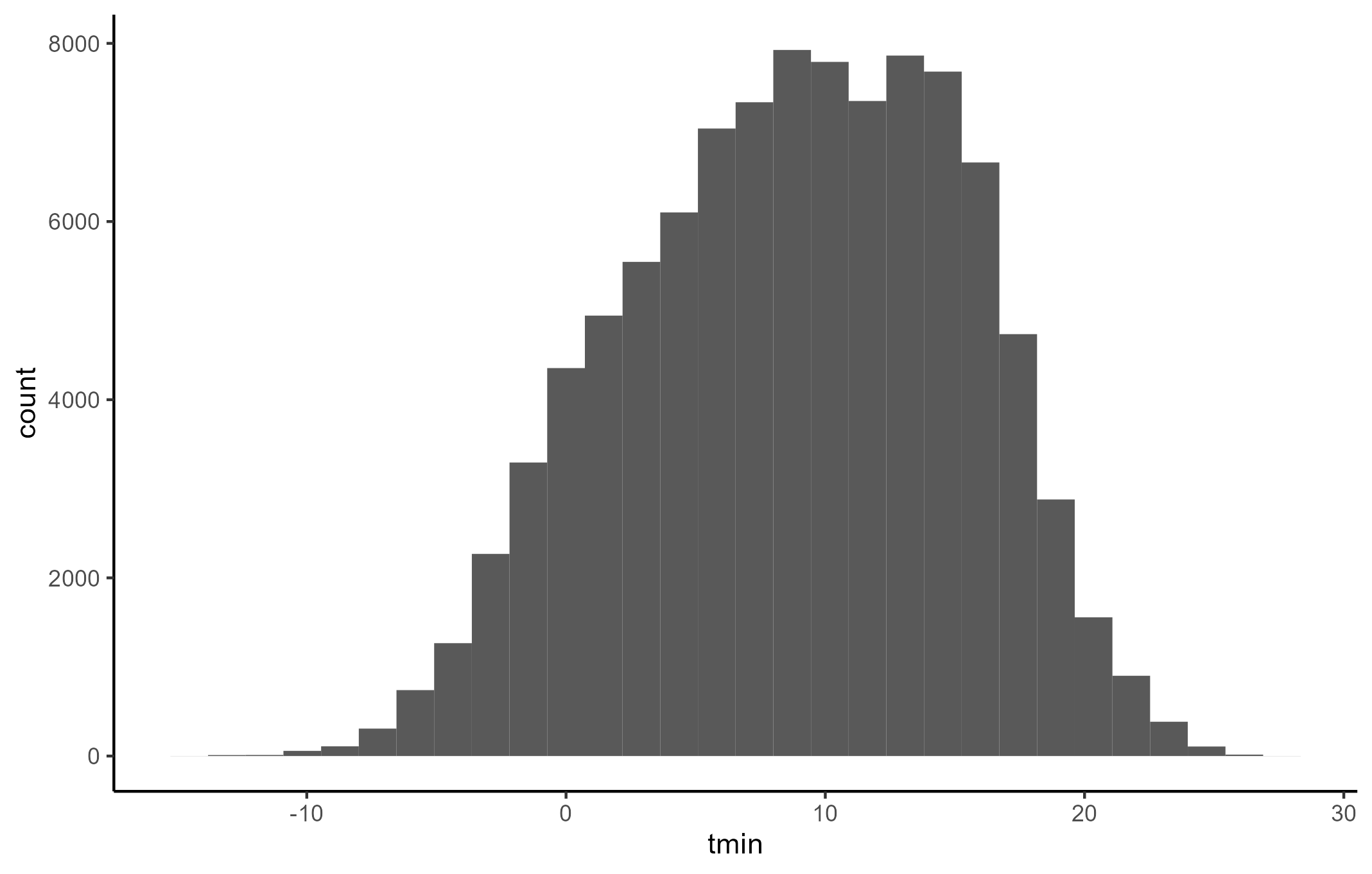
Grâce à ce graphique, il est visible que la tmin varie entre -15 et 30, avec une très légère asymétrie à droite.
Il est aussi possible de représenter toutes les données numériques en changeant la forme du jeu de données grâce à pivot_longer() du package {tidyr} , puis grâce à la fonction facet_wrap() de {ggplot2} .
donnees_temperature |>
select(tmin:tmoy, densite_humaine_par_km_carre) |>
pivot_longer(
everything(),
names_to = "mesure",
values_to = "valeur"
) |>
ggplot() +
aes(x = valeur) +
geom_histogram() +
facet_wrap(~ mesure, scales = "free") +
theme_bw()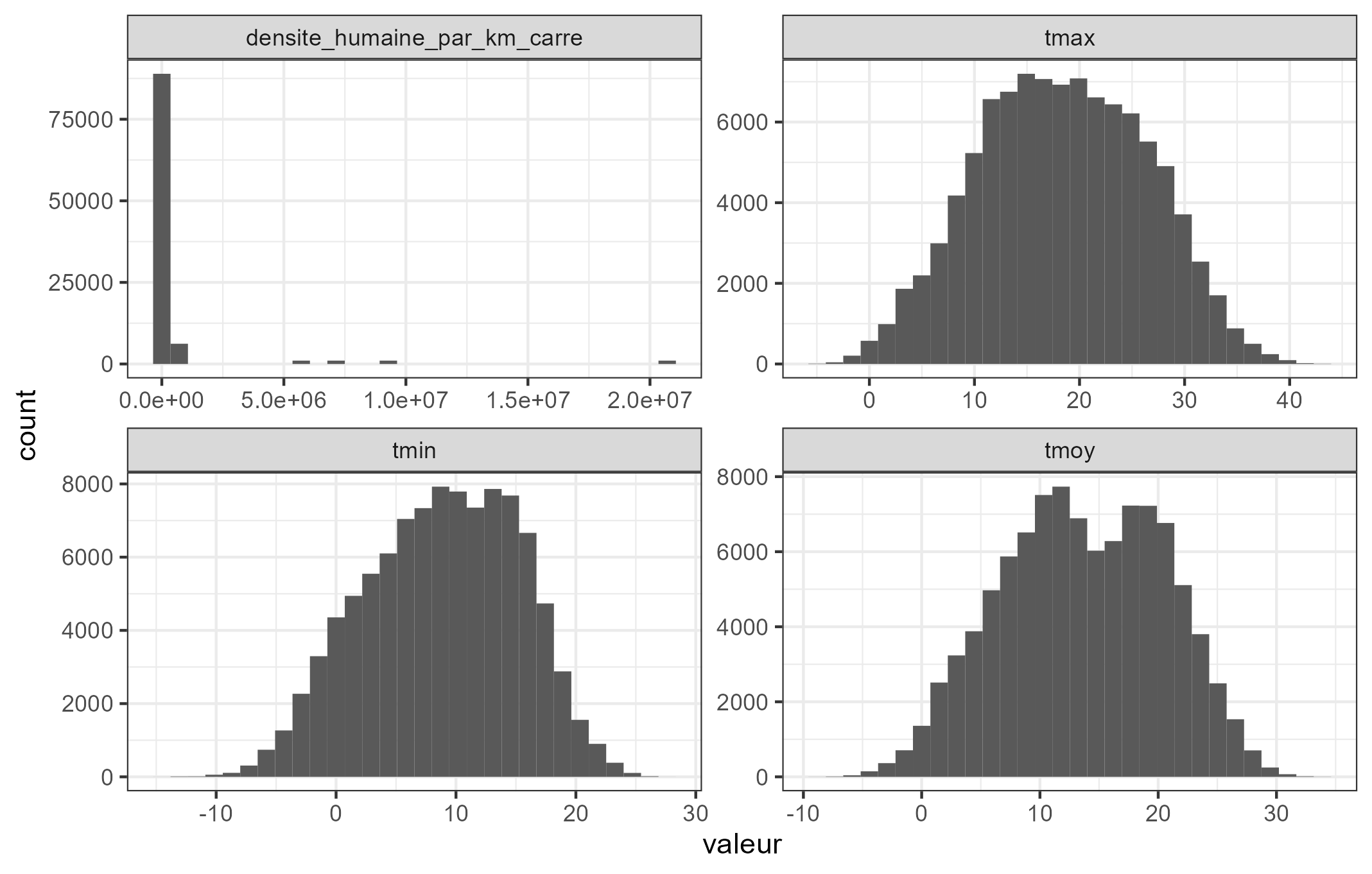
Si la densité de population humaine est clairement asymétrique avec beaucoup de petites valeurs et quelques très grandes, ce n’est pas trop le cas des autres. Par contre, la température moyenne présente deux bosses. Peut-être liées aux saisons ; cette piste sera explorée lors de l’analyse bivariée.
Une autre représentation pour comparer les données de température entre elles est la réalisation de boîtes à moustaches. La boîte à moustaches s’appuie sur les quartiles, comme représenté ci-dessous.
donnees_temperature |>
select(tmin:tmoy) |>
pivot_longer(
everything(),
names_to = "mesure",
values_to = "valeur"
) |>
ggplot() +
aes(x = valeur, y = mesure, color = mesure) +
geom_boxplot() +
theme_bw()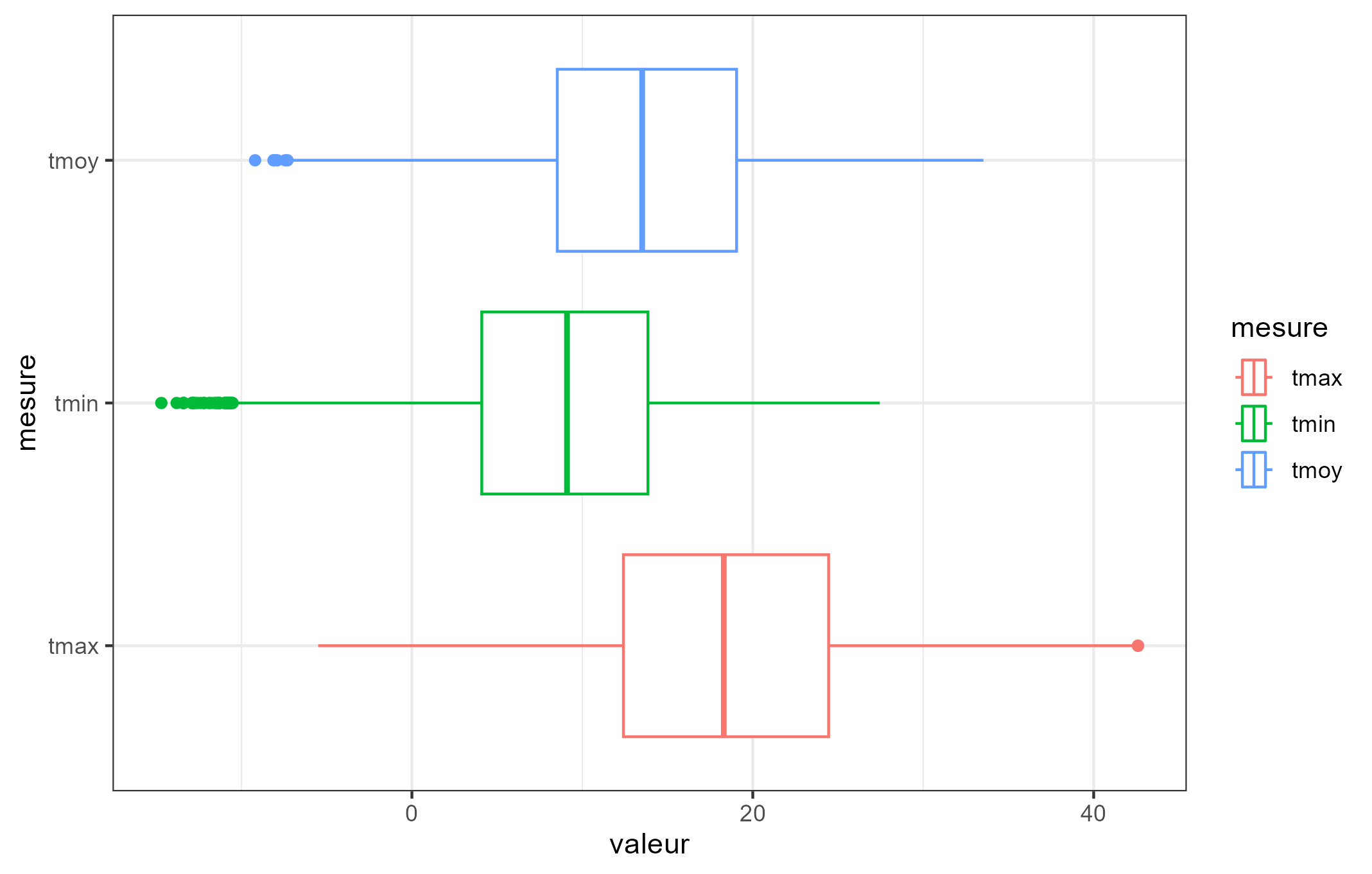
À vous de jouer

Contexte
Camille vous envoie le message suivant :
Le support Quarto que tu m’as envoyé me convient. Tu peux maintenant réaliser la partie analyse statistique descriptive univariée !
Personnellement je préfère commencer par les variables quantitatives, mais c’est à toi de voir.
Consignes
Vous décidez donc de suivre le conseil de Camille et grâce aux fonctions présentes dans le cours, vous analysez les données de températures journalières minimales, maximales et moyennes, ainsi que la densité de population.
En résumé
Les données quantitatives peuvent être résumées par des paramètres de position et de distribution.
Il est possible de calculer les paramètres sur plusieurs variables en même temps.
L’histogramme est l’idéal pour visualiser la distribution des variables quantitatives.
Les boîtes à moustaches permettent de comparer les distributions de plusieurs variables en même temps.
Vous avez acquis les connaissances pour traiter les variables quantitatives, vous allez pouvoir passer aux variables qualitatives.
