Résumez des variables qualitatives
Le jeu de données fourni par Camille contient des variables quantitatives que vous avez appris à résumer, mais aussi des variables qualitatives, comme le nom des départements ou des régions.
Vous ne pouvez pas étudier les variations des variables qualitatives comme vous étudiez celles des variables quantitatives. En effet, quel sens donner à la moyenne des noms des départements ?
Par contre, vous pouvez étudier leurs variabilités autrement ; c’est l’objet de ce chapitre. 😉
Identifiez les bases des variables qualitatives
Les données qualitatives sont les plus variées. Comme vu précédemment, elles peuvent avoir un ordre sous-jacent, comme le numéro du département associé à l’ordre alphabétique des noms, avoir un nombre infini de modalités, comme les avis sur un service, ou un nombre fixe de modalités, comme les noms des régions de France. Enfin, les données peuvent être dichotomiques, c’est-à-dire n’avoir que deux valeurs, comme la localisation du département sur le continent ou en dehors.
C’est quoi une modalité ?
Une modalité, ce sont les différentes valeurs que peut prendre une variable qualitative.
Les modalités peuvent avoir un ordre sous-jacent, on appelle cela un facteur. C'est un vecteur avec des modalités ordonnées, c'est-à-dire que derrière les mots il y a un vecteur numérique. Par exemple, le numéro des départements en France est associé à l’ordre alphabétique.
À l’inverse, certaines variables qualitatives peuvent apparaître sous la forme de valeurs numériques, comme par exemple le code Insee du département.
Les données qualitatives avec un nombre de modalités fini sont souvent représentées sous la forme de tableaux de comptage.
Découvrez les données qualitatives
Dans le jeu de données, il existe plusieurs variables qui sont des données qualitatives, toutes liées au département. En effet, un département a toujours le même code_insee_departement , le même nom de departement , le même chef_lieu , fait partie de la même region et appartient ou non au continent .
La première étape est donc de vérifier l’unicité de cet assemblage, c’est-à-dire que dans le jeu de données, il n’y a pas d’erreur et qu’un département est bien lié à une seule modalité des quatre autres variables.
Pour cela, il faut utiliser la fonction distinct() de {dplyr} qui permet de ne garder que les assemblages uniques.
Il est possible de visualiser la table dans un autre onglet grâce à la fonction View() du package {utils} .
L’utilisation de count() en fonction de departement sur la table créée permet de vérifier l'unicité des associations.
# visualiser la table
donnees_temperature |>
distinct(
code_insee_departement,
departement,
chef_lieu,
region,
continent
) |>
View()
# verifier l'unicite
donnees_temperature |>
distinct(
code_insee_departement,
departement,
chef_lieu,
region,
continent
) |>
count(departement) |>
filter(n == 1)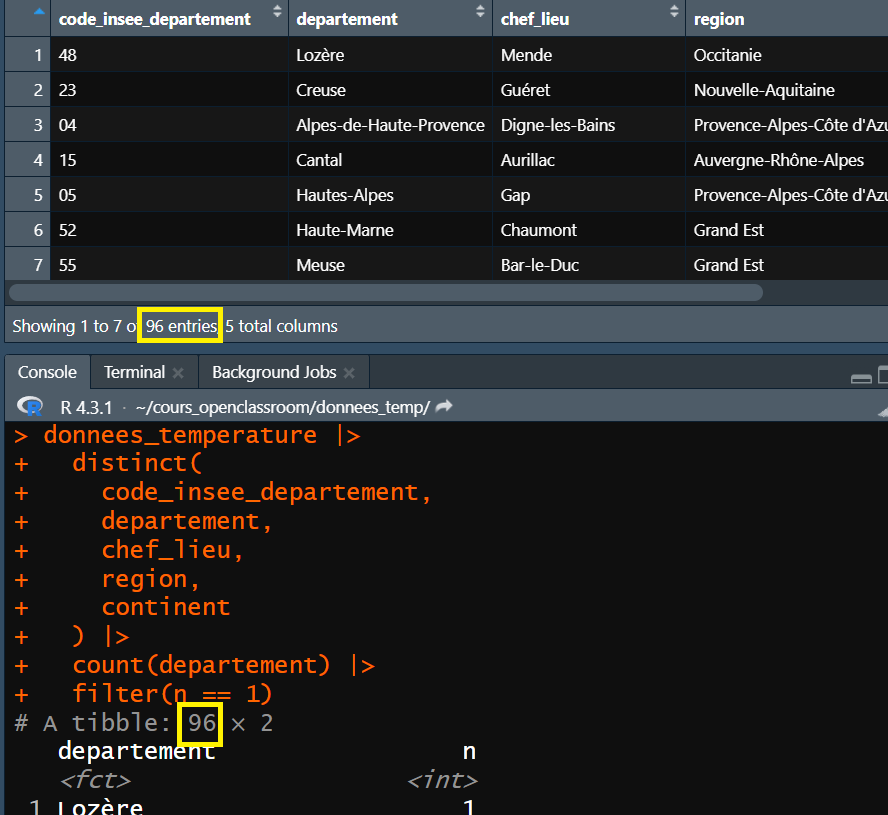
Il y a le même nombre de lignes, 96, en appliquant le filtre ( n == 1 ) que sans, donc les associations code_insee_departement , departement , chef_lieu , region et continent sont uniques, il n’y a pas d’erreur.
96 départements ? Mais il n’y en a pas 101 en France ?
Si, effectivement. En explorant la table créée par les lignes précédentes, vous vous rendez compte qu’il n’y a aucun département ou territoire d’outre-mer. Vous faites donc tout de suite remonter l’information à Camille, votre cheffe de projet.
Elle vous répond de changer le blueprint en retirant les demandes liées à ces départements, et de continuer l’analyse.
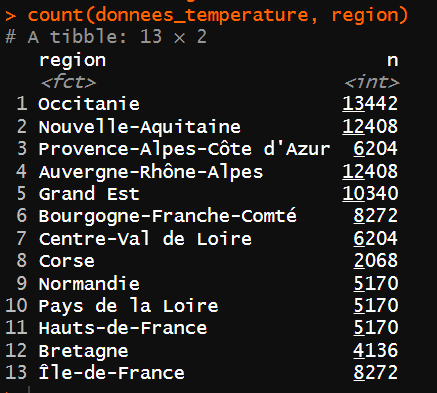
Vous allez maintenant vérifier que vous avez bien 13 régions face aux nouveaux attendus. Pour cela, vous réutilisez distinct() uniquement sur les régions : distinct(donnees_temperature, region) .
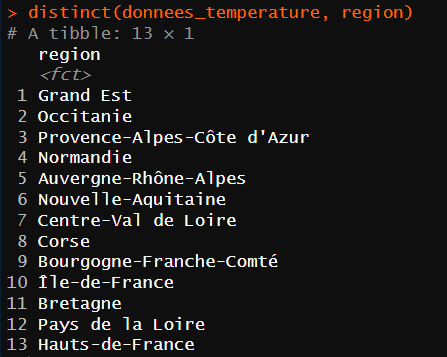
En lisant la liste des régions, vous prenez conscience qu’une seule région, la Corse, sera considérée comme n’appartenant pas au continent. Vous le vérifiez en utilisant la fonction count() de {dplyr} :
donnees_temperature |>
distinct(region, continent) |>
count(continent)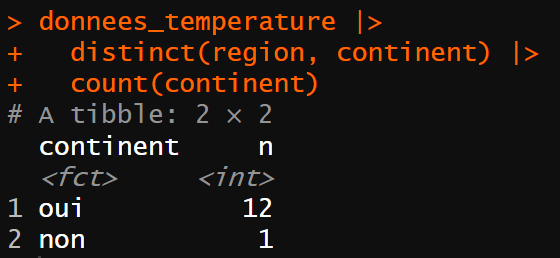
En en discutant à la pause avec l’équipe, vous décidez de laisser le blueprint avec la demande sur le continent.
La variable departement est ordonnée par ordre alphabétique mais pas region . Il va falloir homogénéiser cela.
Manipulez les modalités
Dans cette vidéo, vous avez appris à visualiser l’ordre des modalités d’un facteur grâce à la fonction fct_unique() , ordonner selon l’ordre alphabétique les modalités d’un facteur avec la fonction fct_relevel() et selon la valeur numérique avec la fonction fct_inseq() , toutes du package {forcats} .
# visualisation des modalités de la variable region
fct_unique(donnees_temperature$region)
# visualisation des modalités de la variable departement
fct_unique(donnees_temperature$departement)
# visualisation des modalités de la variable code_insee_departement
fct_unique(donnees_temperature$code_insee_departement)
# réordonne les modalités des variables département, region et code_insee_departement
donnees_temperature <- donnees_temperature |>
mutate(
departement = fct_relevel(donnees_temperature$departement, sort),
region = fct_relevel(donnees_temperature$region, sort),
code_insee_departement = fct_inseq(donnees_temperature$code_insee_departement)
)
# vérification
fct_unique(donnees_temperature$departement)
fct_unique(donnees_temperature$region)
fct_unique(donnees_temperature$code_insee_departement)Représentez vos données qualitatives
Comme demandé dans le blueprint, vous avez besoin de représenter la disponibilité des données selon les départements. Vous pouvez choisir de les représenter sous forme de tableaux, grâce à la fonction count() de {dplyr} :
# selon les départements
count(donnees_temperature, departement)
# selon les régions
count(donnees_temperature, region)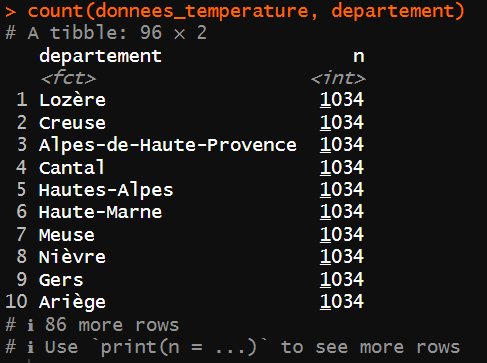
Vous pouvez aussi représenter l’inégalité de ces variables grâce à des graphiques.
Le diagramme en barres, par exemple, permet de montrer en un coup d'œil les régions qui ont le plus de points de mesure.
La mise en forme du texte à l’horizontale se fait grâce à la fonction
theme()avec l’argumentaxis.text.xdu package{ggplot2}.Le tri selon l'occurrence des modalités grâce à la fonction
fct_infreq()vue précédemment.
## initial
ggplot(donnees_temperature) +
aes(x = region) +
geom_bar() +
theme_classic()
## titres des modalités à la verticale
ggplot(donnees_temperature) +
aes(x = region) +
geom_bar() +
theme_classic() +
theme(axis.text.x = element_text(angle = 90))
## tri selon l'occurrence
ggplot(donnees_temperature) +
aes(x = fct_infreq(region)) +
geom_bar() +
theme_classic() +
theme(axis.text.x = element_text(angle = 90))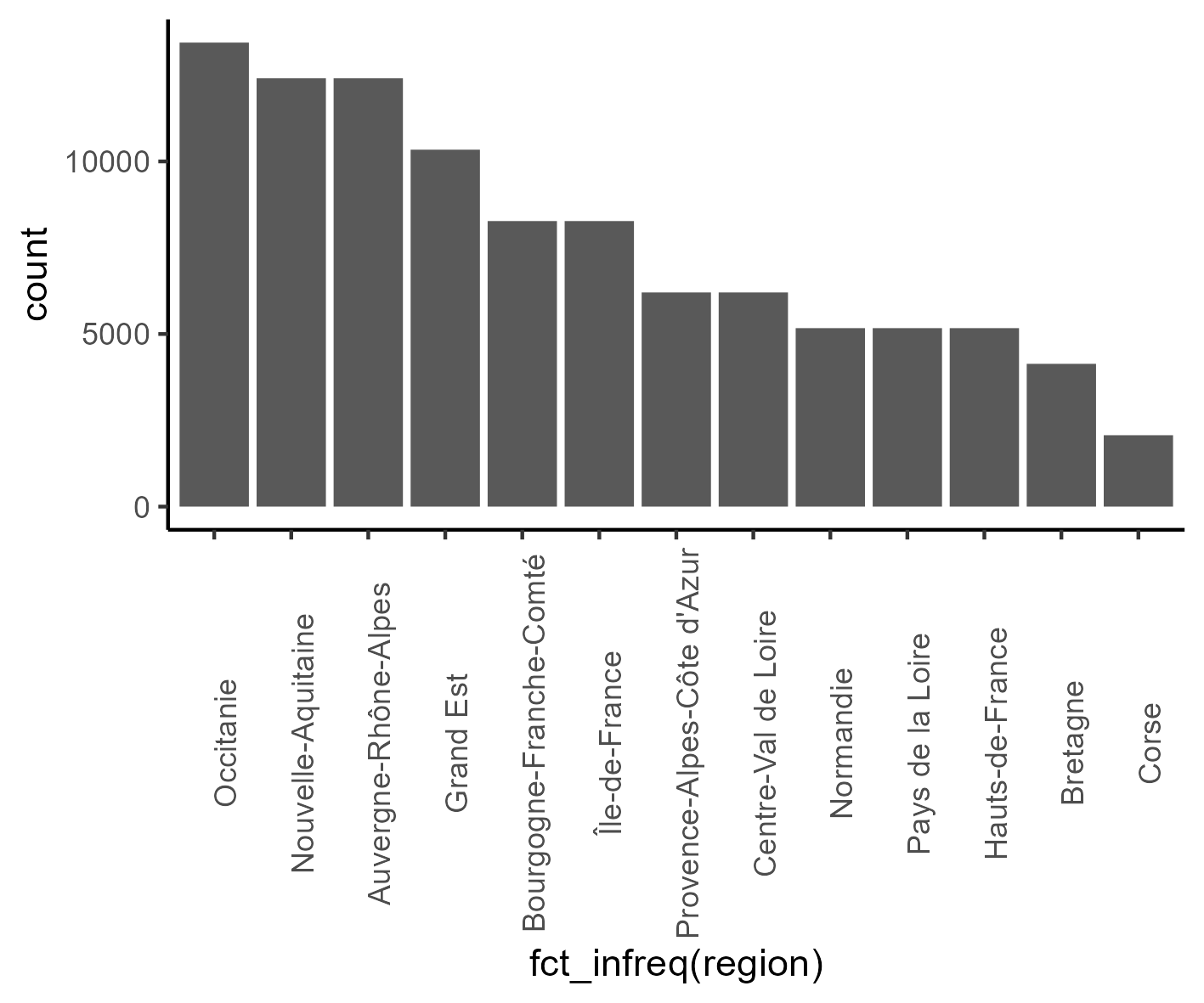
Occitanie compte 13 départements alors que Nouvelle-Aquitaine et Auvergne-Rhône-Alpes comptent chacune 12 départements, soit deux fois plus que Centre-Val-de-Loire et Provence-Alpes-Côte-d’Azur, trois fois plus que la Bretagne et six fois plus que la Corse.
Une autre représentation possible est la réalisation d’un diagramme circulaire qui permet de visualiser la proportion de chaque modalité.
donnees_temperature |>
count(continent) |>
ggplot() +
aes(x = "", y = n, fill = continent) +
geom_bar(stat = "identity") +
coord_polar("y") +
scale_fill_manual(values = c("oui" ="darkblue", "non" = "darkgreen")) +
theme_void() 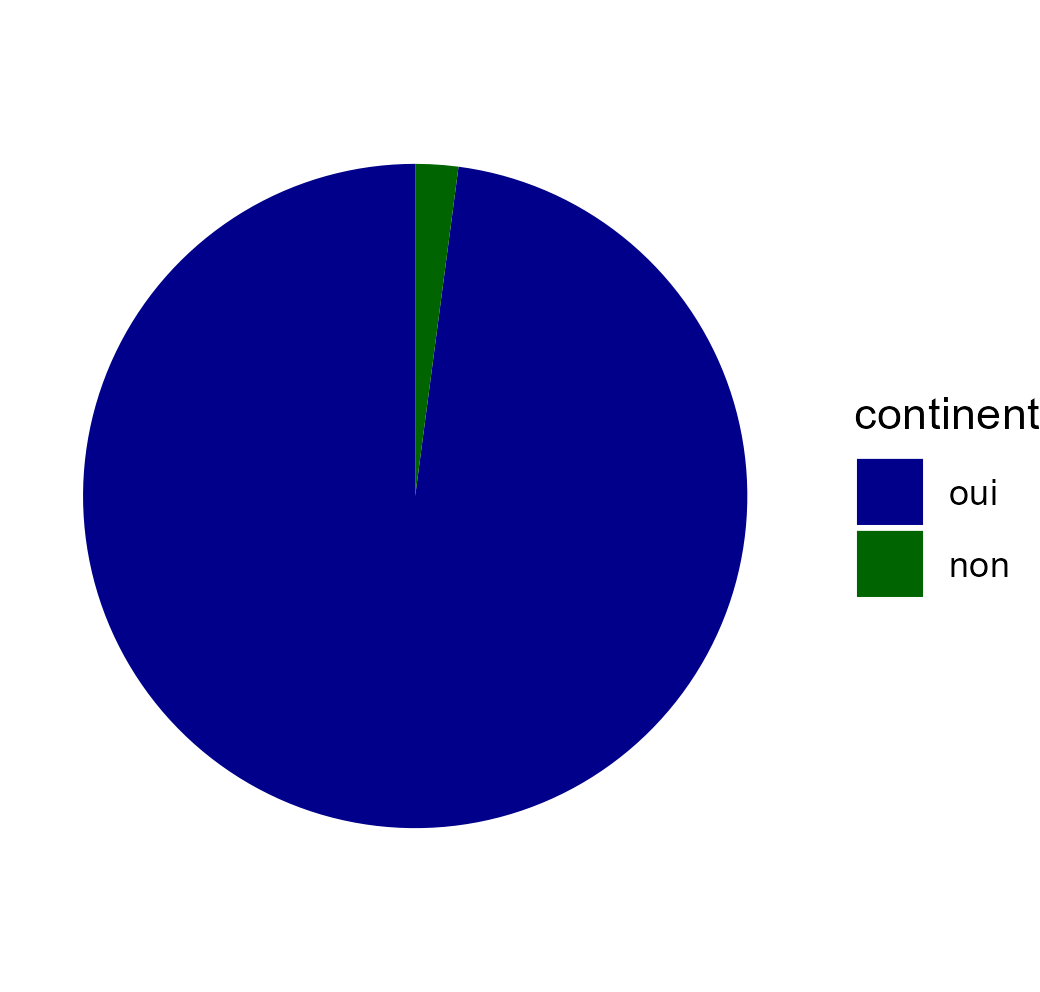
J’aurais très bien pu faire un diagramme circulaire pour représenter les différentes régions, non ?
Le diagramme circulaire est à privilégier pour les variables avec peu de modalités et de très grosses différences. Le diagramme en barres permet une comparaison plus facile lorsqu’il y a un grand nombre de modalités et que l’on souhaite les comparer entre elles.
À vous de jouer

Contexte
Camille vous croise dans le couloir : “Merci pour l’analyse descriptive quantitative. Tu penses pouvoir m’envoyer rapidement la qualitative ?”.
Vous répondez que vous vous y mettez immédiatement et qu’elle devrait pouvoir l’avoir dans la semaine.
Consignes
C’est à vous de travailler sur les variables qualitatives :
Vérifier l’unicité des informations contenues dans les colonnes
code_insee_departement,departement,chef_lieu,regionetcontinent.Lister les modalités des variables pour vérifier l’absence de coquilles.
Changer l’ordre des modalités.
Représenter les variables.
En résumé
Les variables qualitatives sont les plus variées.
Le traitement des variables qualitatives dépend de leur nature.
La première représentation des données qualitatives est le tableau de comptage.
Lorsqu’il y a beaucoup de modalités, la représentation à privilégier est le diagramme en barres.
Le diagramme circulaire n'est utile que pour des variables avec peu de modalités et de très grosses différences.
Les données sont souvent caractérisées comme qualitatives ou quantitatives, mais c’est nier la répétition des mesures dans le temps et l’espace.
