Visualisez les données

Voici un extrait de la base de données de VertiGo que nous avons chargée dans Pandas. Quelle interprétation pouvez-vous en faire ?
Ce n’est pas évident, n’est-ce pas ? Eh bien c’est normal car le format CSV ou Pandas n’est pas très lisible ! C’est pour ça que la visualisation des données est une étape fondamentale dans l'analyse statistique. Elle permet de transformer ce genre d’ensemble de données complexes en informations visuelles claires et compréhensibles.
Mais avant de plonger dans la création de graphiques, il est crucial de définir l'objectif de cette visualisation. Que cherchons-nous à révéler ou à communiquer à travers ces données ? Il y a quatre objectifs principaux que l’on retrouve régulièrement lors des tests statistiques : la visualisation de la distribution, la comparaison de valeurs, la mise en évidence de tendances et l'identification de relations entre variables.
Sélectionnez des types de visualisation en fonction de vos objectifs
Chacun de ces objectifs s'appuie sur un format de visualisation spécifique et optimisé pour présenter l'information de manière efficace et intuitive.
Visualiser la distribution : c’est fondamental pour comprendre comment vos données sont réparties. Utiliser un histogramme, par exemple, va vous montrer combien de fois chaque valeur apparaît dans vos données. Ce graphique est univarié c’est-à-dire qu’il analyse la distribution d'une seule variable quantitative. C’est ici qu’il est intéressant de calculer la moyenne et la médiane, car elles offrent un aperçu des valeurs centrales de vos données. Mais la moyenne et la médiane ne révèlent pas tout sur la distribution de vos données. Nous allons approfondir le sujet de la distribution des données dans la partie suivante. En attendant, voici un exemple simple d’histogramme.
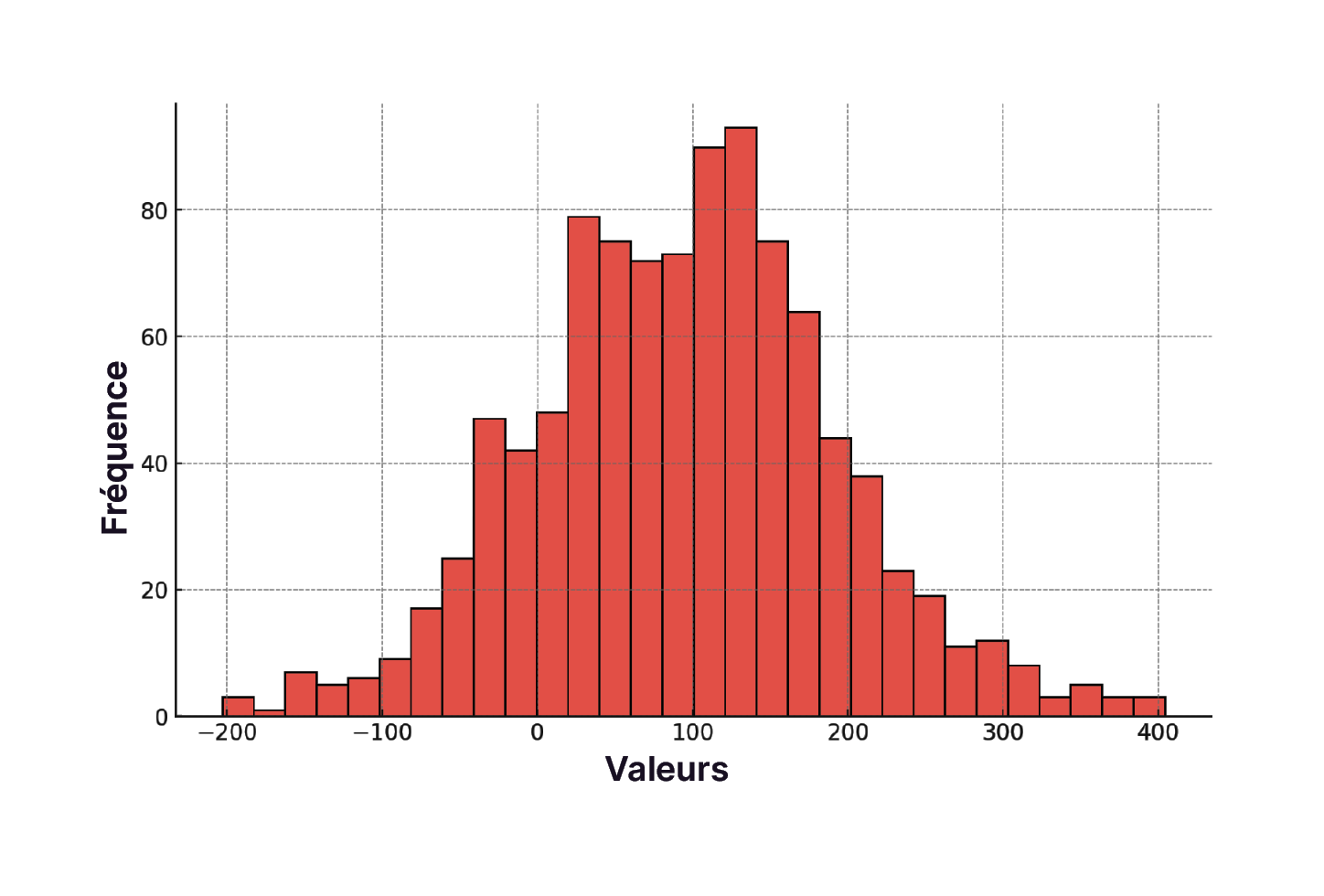
Histogramme représentant la distribution de données
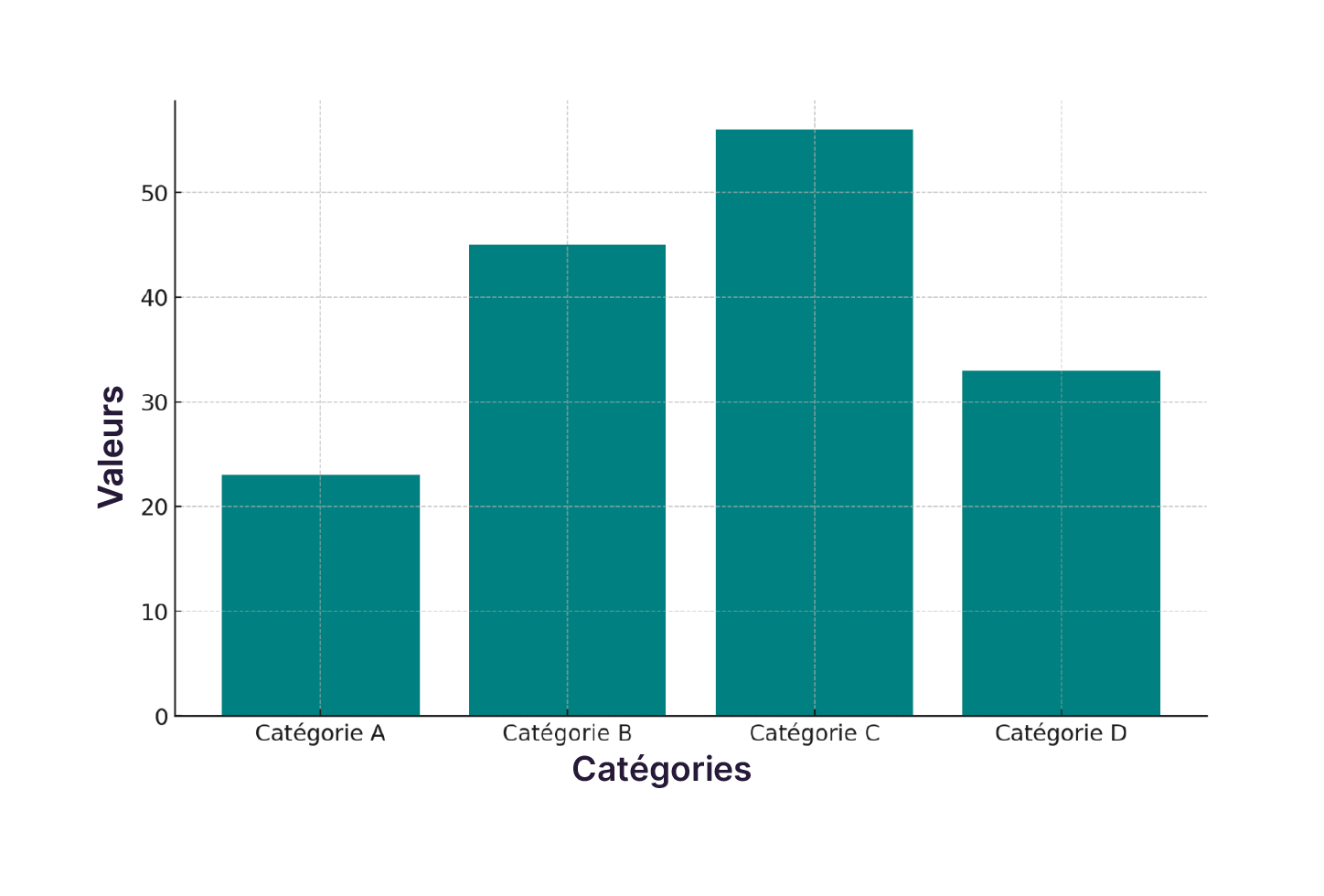
Comparer des valeurs : le graphique à barres est souvent utilisé pour comparer des quantités entre différentes catégories ou groupes (ex. : types de voyage, saison…). Contrairement à l'histogramme, on parle ici de graphique bivarié puisqu'il implique plus d’une variable : une variable catégorielle et une variable quantitative. Sa structure permet de présenter visuellement les différences de taille ou de valeur entre les éléments. Voici un exemple de graphique à barres.
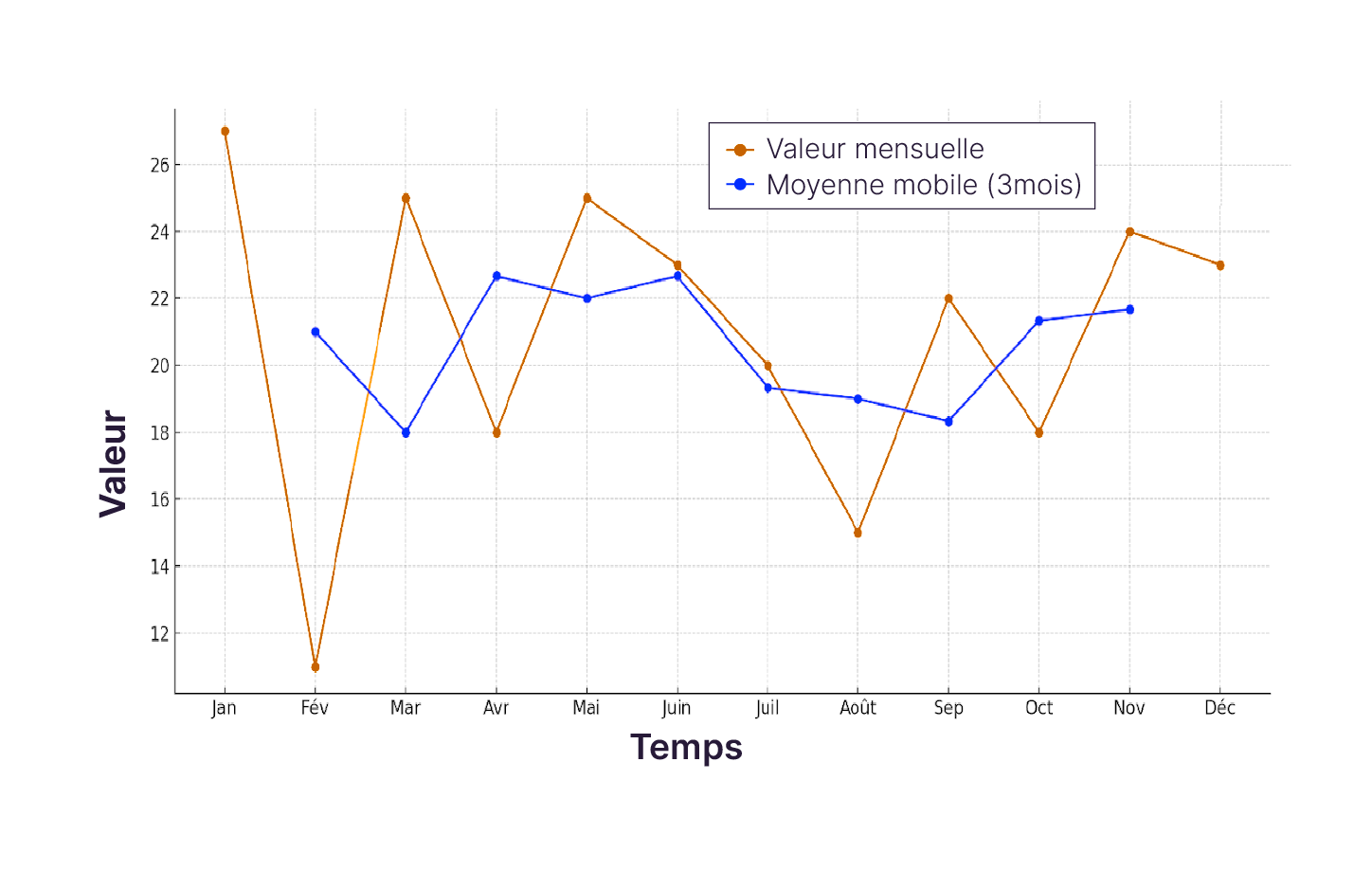
Montrer une tendance : Si on souhaite plutôt mettre en lumière l'évolution d'une variable au fil du temps, les graphiques en ligne sont plus appropriés. Ils permettent de tracer le parcours d'une variable en soulignant les augmentations, les diminutions et les plateaux. Dans cette optique, une moyenne mobile peut être utilisée pour lisser les fluctuations à court terme et mettre en évidence les tendances de fond.
Voici un exemple de graphique linéaire.
Identifier des relations : quand l'intérêt se porte sur l'examen des relations entre deux variables quantitatives, le nuage de points (scatter plot en anglais) est votre meilleure option. Elle offre une représentation graphique bivariée qui permet de détecter la présence de modèles, de tendances ou d'anomalies. Ce type de graphique illustre comment une variable peut influencer ou se comporter en fonction d'une autre, révélant des corrélations potentielles ou l'absence de relation significative entre les éléments analysés. Voici un exemple de nuage de points. La courbe de tendance nous donne une meilleure idée de la trajectoire.
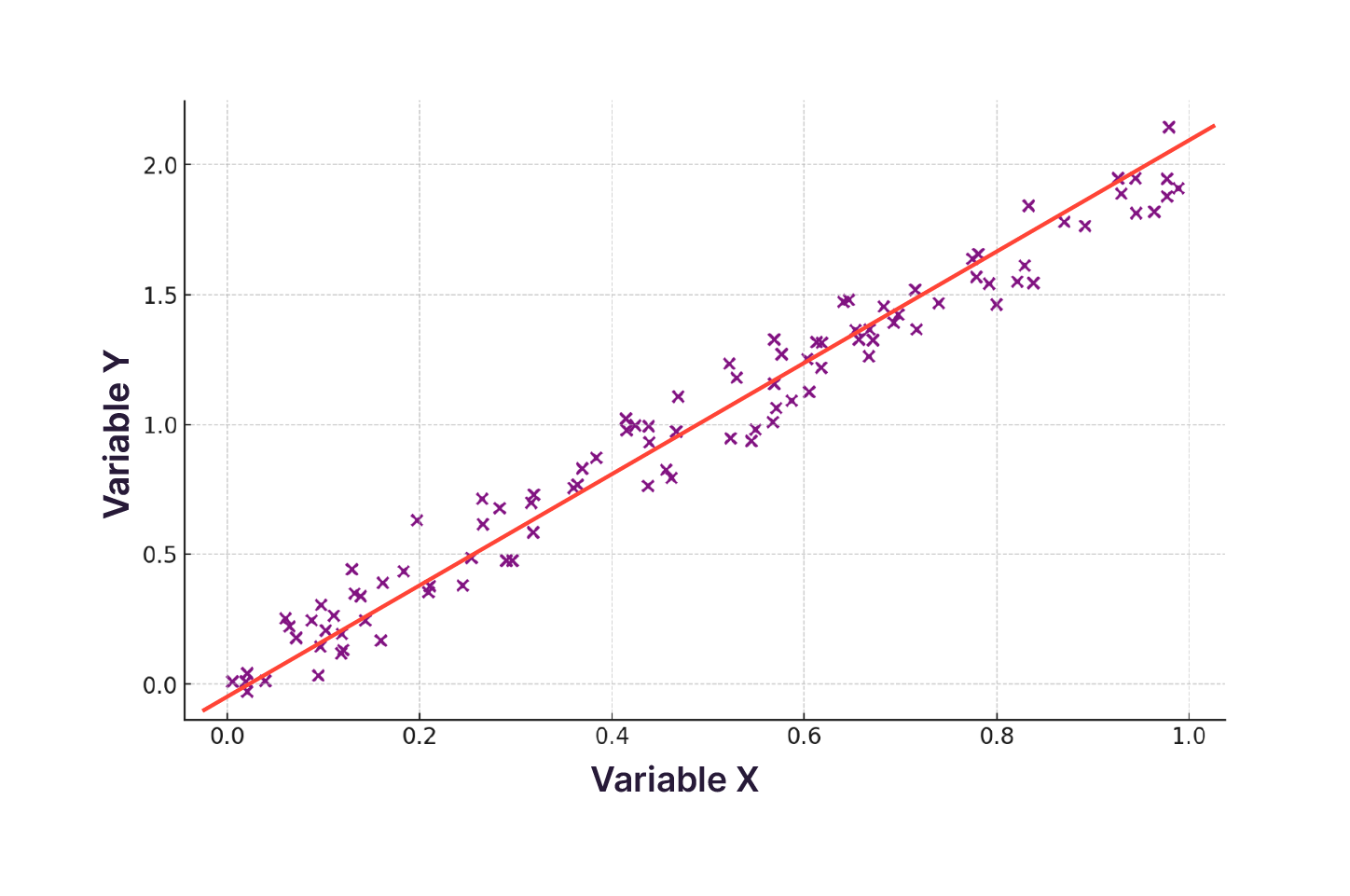
Quel type de format peut-on utiliser pour nous aider à vérifier notre hypothèse de départ ?
En fait, les types de graphiques ne sont pas mutuellement exclusifs ! Une analyse approfondie des données pourrait nécessiter l'utilisation combinée de plusieurs types de visualisations pour éclairer différents aspects d'un même ensemble de données. Par exemple, notre étude sur la performance des ventes peut commencer par un histogramme sur la distribution des prix totaux des voyages, suivie d’un graphique à barres pour comparer les types de voyages. Ensuite, un graphique en ligne est utile pour montrer l'évolution des prix totaux des voyages en fonction de la date de début des voyages. Enfin, le nuage de points va nous permettre d’explorer la relation entre la durée du voyage et le prix.
Voyons maintenant comment concrétiser tout ça dans le code.
Créez les visualisations
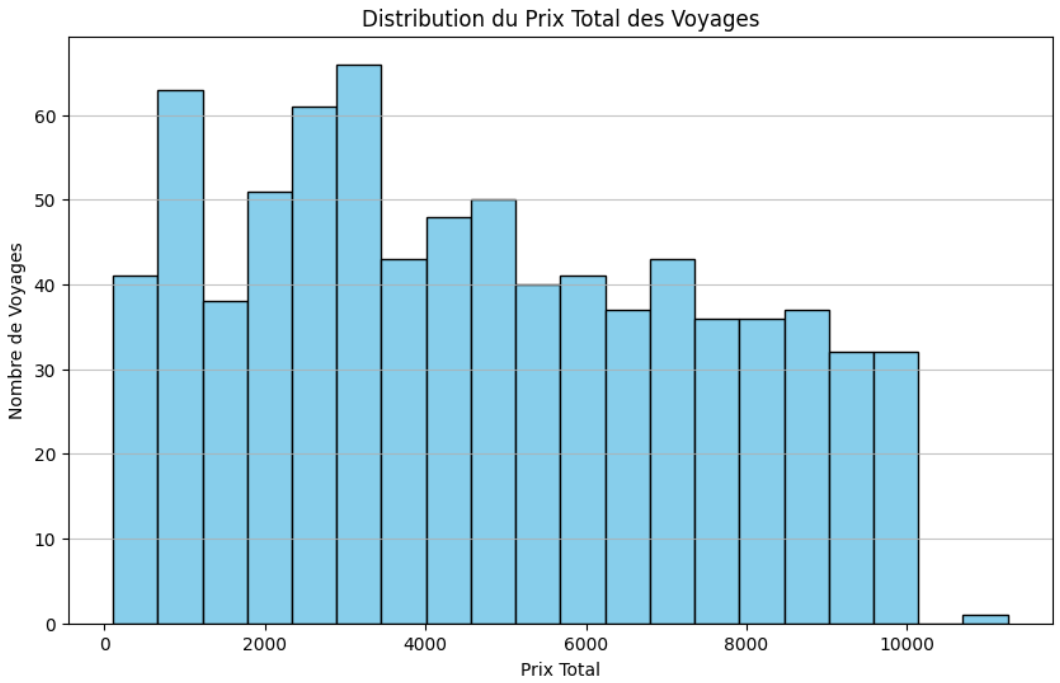
Histogramme sur la distribution des prix totaux des voyages
Cet exemple utilise matplotlib pour générer un histogramme, avec 20 bins par défaut, mais vous pouvez ajuster ce nombre selon la précision de distribution souhaitée. Commencez par importer les bibliothèques nécessaires, chargez vos données dans un DataFrame pandas, puis créez et affichez l'histogramme.
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv('chemin_vers_ton_fichier.csv')
#Remplace 'chemin_vers_ton_fichier.csv' par le chemin réel de ton fichier CSV
plt.figure(figsize=(10, 6))
plt.hist(data['prix total'], bins=20, color='skyblue', edgecolor='black')
plt.title('Distribution du Prix Total des Voyages')
plt.xlabel('Prix Total')
plt.ylabel('Nombre de Voyages')
plt.grid(axis='y', alpha=0.75)
plt.show()Et voilà, le tour est joué !
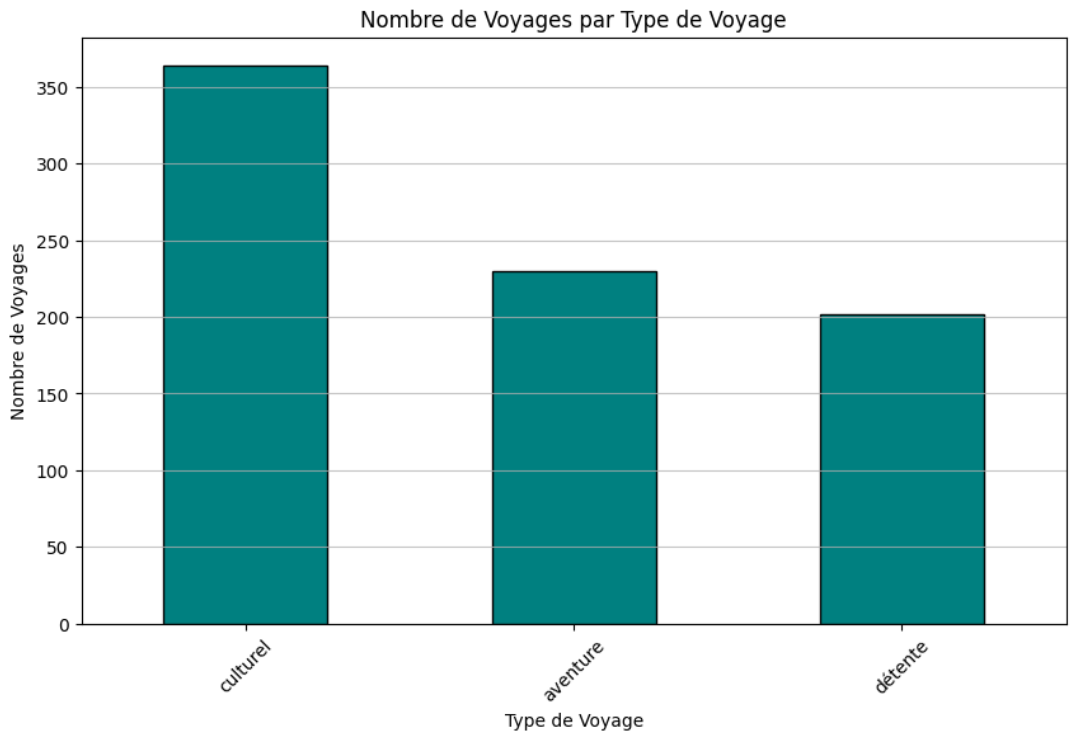
Graphique à barres pour comparer les types de voyages
La méthode.value_counts()est particulièrement utile pour obtenir le décompte des occurrences de chaque catégorie dans la colonne'type de voyage'. Ensuite,.plot(kind='bar')génère le graphique à barres, avec une personnalisation simple pour améliorer la lisibilité.
import matplotlib.pyplot as plt
import pandas as pd
# Chargement des données
data = pd.read_csv('chemin_vers_ton_fichier.csv')
# Assure-toi de remplacer cela par le chemin réel de ton fichier
# Calculer le nombre de voyages par type de voyage
voyages_par_type = data['type de voyage'].value_counts()
# Création du graphique à barres
plt.figure(figsize=(10, 6))
voyages_par_type.plot(kind='bar', color='teal', edgecolor='black')
plt.title('Nombre de Voyages par Type de Voyage')
plt.xlabel('Type de Voyage')
plt.ylabel('Nombre de Voyages')
plt.xticks(rotation=45)
# Rotation des étiquettes pour une meilleure lisibilité
plt.grid(axis='y', alpha=0.75)
plt.show()Pas mal, non ?
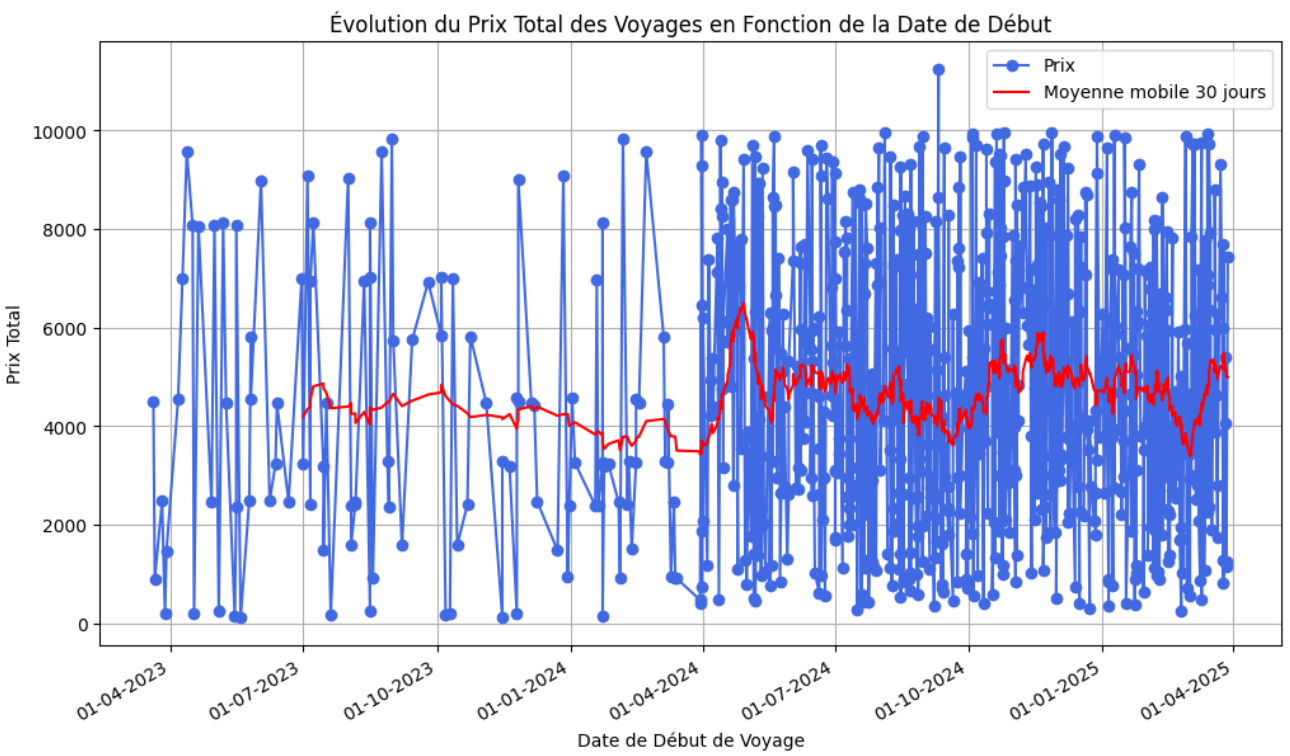
Graphique en ligne pour montrer l'évolution des prix totaux des voyages en fonction de la date de début des voyages
Ce code charge d'abord les données et convertit les dates de début de voyage en type datetime pour permettre une manipulation aisée des dates. Ensuite, il trie les données par la date de début de voyage. La fonctionplt.plot()est utilisée pour dessiner le graphique en ligne, en marquant chaque point de données et en reliant ces points par des lignes. Les fonctions dematplotlib.dates sont utilisées pour formater l'axe des X et afficher les dates de manière lisible.
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.dates as mdates
# Charger les données
data = pd.read_csv('chemin_vers_ton_fichier.csv') # Remplace par le chemin réel vers ton fichier CSV
data['date de début de voyage'] = pd.to_datetime(data['date de début de voyage'], dayfirst=True) # Assure-toi que le format de la date est correct
# Trier les données par date de début de voyage
data_sorted = data.sort_values('date de début de voyage')
# Création du graphique en ligne
plt.figure(figsize=(12, 7))
plt.plot(data_sorted['date de début de voyage'], data_sorted['prix total'], marker="o", linestyle='-', color='royalblue', label="Prix")
plt.plot(data_sorted['date de début de voyage'], data_sorted['prix total'].rolling(30).mean(), linestyle='-', color='red', label="Moyenne mobile 30 jours")
# Formater l'axe des X pour afficher les dates correctement
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%d-%m-%Y'))
plt.gca().xaxis.set_major_locator(mdates.AutoDateLocator())
plt.gcf().autofmt_xdate() # Rotation automatique des dates pour une meilleure lisibilité
plt.legend()
plt.title('Évolution du Prix Total des Voyages en Fonction de la Date de Début')
plt.xlabel('Date de Début de Voyage')
plt.ylabel('Prix Total')
plt.grid(True)
plt.show()La magie opère !
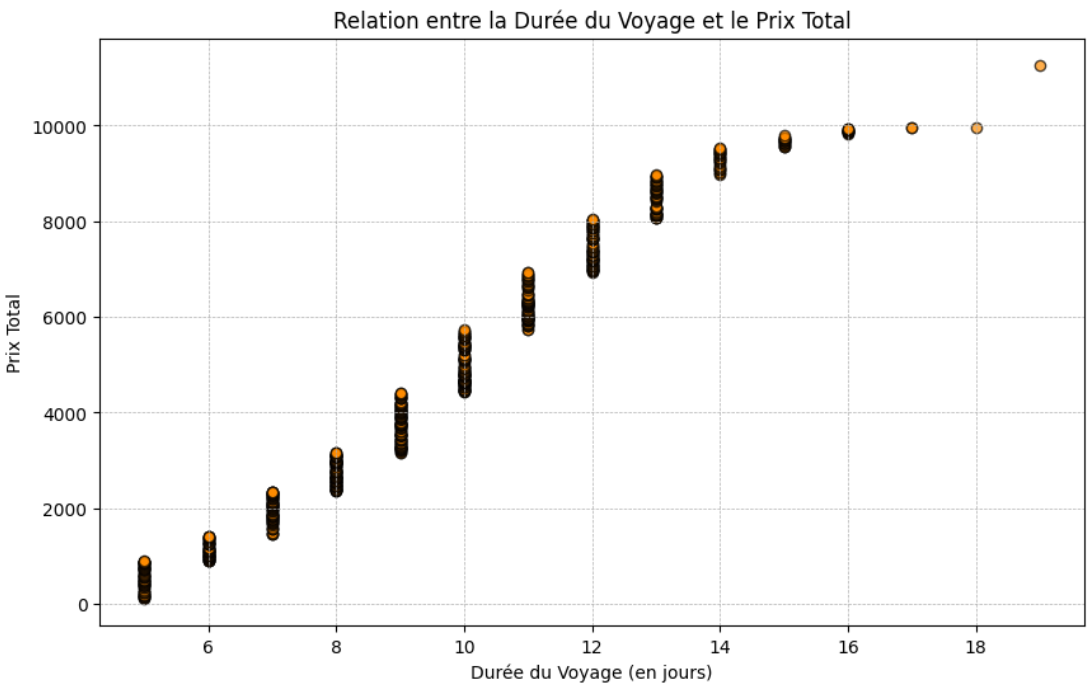
Nuage de points pour explorer la relation entre la durée du voyage et le prix.
Ce code crée un nuage de points qui illustre la relation entre la durée du voyage (en jours) et le prix total des voyages. La méthodeplt.scatter() est utilisée pour dessiner le nuage de points. Les paramètrescolor,edgecolor et alphapermettent de personnaliser l'apparence des points pour améliorer la lisibilité et l'esthétique du graphique.
import matplotlib.pyplot as plt
import pandas as pd
# Charger les données
data = pd.read_csv('chemin_vers_ton_fichier.csv') # Assure-toi de remplacer cela par le chemin réel de ton fichier
# Créer un nuage de points
plt.figure(figsize=(10, 6))
plt.scatter(data['durée de voyage (en jours)'], data['prix total'], color='darkorange', edgecolor='black', alpha=0.7)
plt.title('Relation entre la Durée du Voyage et le Prix Total')
plt.xlabel('Durée du Voyage (en jours)')
plt.ylabel('Prix Total')
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
plt.show()Voilà le résultat final !
Vous trouverez ici une vidéo qui récapitule comment tracer des graphiques en Python.
Interprétez les visualisations
Après avoir soigneusement mis en œuvre ces visualisations à l'aide de Python, nous atteignons une étape cruciale de notre analyse : l'interprétation des résultats. C’est là que les données transformées en graphiques commencent véritablement à raconter leur histoire. Interpréter les résultats va au-delà de la simple observation des tendances. Il s'agit de comprendre ce qu'ils signifient dans le contexte de notre étude. Interprétons ensemble les résultats que nous avons obtenus pour l’entreprise VertiGo par type de graphique.
Histogramme : pour rappel, l'histogramme révèle la distribution des prix totaux des voyages. Il met clairement en évidence une préférence pour les options économiques avec un pic dans les gammes de prix inférieures. Les consommateurs chez VertiGo sont sensibles au prix. Cette analyse aide à comprendre une partie de la stratégie de tarification. Elle va aussi permettre à l’entreprise d'identifier les segments de marché cibles, avec une base pour optimiser les offres de produits et les stratégies de prix.
Graphique à barres : il compare le nombre de voyages par type de voyage. Cette visualisation souligne les tendances du marché et aide à identifier les offres les plus attrayantes pour les consommateurs. Le graphique montre une légère préférence pour les sorties culturelles. En mettant ça en lumière, le graphique va guider VertiGo dans l'ajustement de son portefeuille de produits.
Graphique en ligne : Le graphique en ligne représente l'évolution du prix total des voyages en fonction de la date de début du voyage. Il montre des fluctuations notables des coûts au fil du temps. On observe une augmentation globales des prix à partir du 1/04/24 probablement dû à un changement de tarification de tous les voyages côté entreprise. D'autres variations semblent plutôt refléter l'impact de facteurs saisonniers (vacances ou événements spéciaux) sur la tarification des voyages ou la capacité de dépense des clients. L'interprétation de ces tendances suggère une opportunité pour VertiGo d'ajuster ses prix dynamiquement en fonction de la demande anticipée.
Nuage de points : ce graphique explore la relation entre la durée des voyages et leur prix total. Il révèle une corrélation très forte entre ces deux variables. Les voyages plus longs se traduisent quasi systématiquement par des coûts plus élevés. Cette observation suggère qu’il pourrait être intéressant d’augmenter l’importance d'autres facteurs, comme le type de voyage, la destination, ou les inclusions de service, pour jouer un rôle plus déterminant dans la fixation des prix (dans la mesure du possible, bien entendu).
Quand ils sont bien interprétés, ces outils de visualisation peuvent orienter des décisions stratégiques, informer sur les ajustements de produit ou de service nécessaires et révéler des opportunités d'optimisation. L’interprétation des visualisations est une compétence essentielle dans l'analyse de données. C’est sur cette base solide que vous allez approfondir l’étude et commencer vos tests statistiques.
À vous de jouer
Contexte
Pour rappel, vous devez améliorer les ventes de VertiGo et June a maintenant besoin de visualiser clairement les tendances démographiques pour personnaliser les offres VertiGo et pour mieux répondre aux besoins et préférences des clients.
Consignes
À partir de “Données clients VertiGo nettoyées”, produisez un graphique univarié de la distribution des âges des clients.
Calculez la médiane.
Interprétez les résultats.
Livrable
Rédigez un script Python et un rapport qui fournit l’interprétation des résultats obtenus.
En résumé
L’histogramme révèle la distribution d'une seule variable, permettant d'identifier rapidement la dispersion dans un ensemble de données.
Le graphique à barres est idéal pour comparer des quantités ou des fréquences entre catégories, mettant en évidence les différences ou similitudes au sein de l’ensemble de données.
Le graphique en ligne montre les tendances et les variations d'une variable au fil du temps, facilitant l'identification de cycles et de tendances croissantes ou décroissantes.
Le nuage de points explore la relation et la corrélation potentielle entre deux variables quantitatives, permettant de visualiser des modèles, des clusters ou des anomalies.
Après avoir exploré et interprété visuellement les données, vous êtes prêts à approfondir l’analyse. La sélection du type de tests statistiques (quantitatif, qualitatif ou mixte) sera votre prochaine étape pour valider et enrichir vos observations. Mais avant ça, place au quiz pour tester vos connaissances et vos compétences de préparation des données.
