Mettez en place votre premier pod
Découvrez les caractéristiques d’un pod
Vous connaissez les avantages des conteneurs pour déployer des applications. Vous avez pu mettre en pratique ces connaissances en utilisant les Deployments Kubernetes, qui sont des objets permettant de créer et de gérer des ensembles de pods.
Mais c’est quoi un pod ?
Alors, excellente question !! Un pod est différent d’un conteneur. Un conteneur contient l’application que l’on veut exécuter. Un conteneur n’est pas directement déployable sur Kubernetes. Il faut passer par un pod.
Un pod est la plus petite unité de déploiement que l’on peut avoir sur Kubernetes. C’est un groupe d'un ou plusieurs conteneurs, avec des ressources de stockage et de réseau partagées, et une spécification sur la façon d'exécuter les conteneurs. Ces conteneurs sont toujours placés sur le même serveur et démarrent en même temps. Ils partagent les mêmes ressources, ce qui facilite leur collaboration. Un pod modélise un « hôte logique » spécifique à une application : il contient un ou plusieurs conteneurs d'application qui sont relativement étroitement couplés.
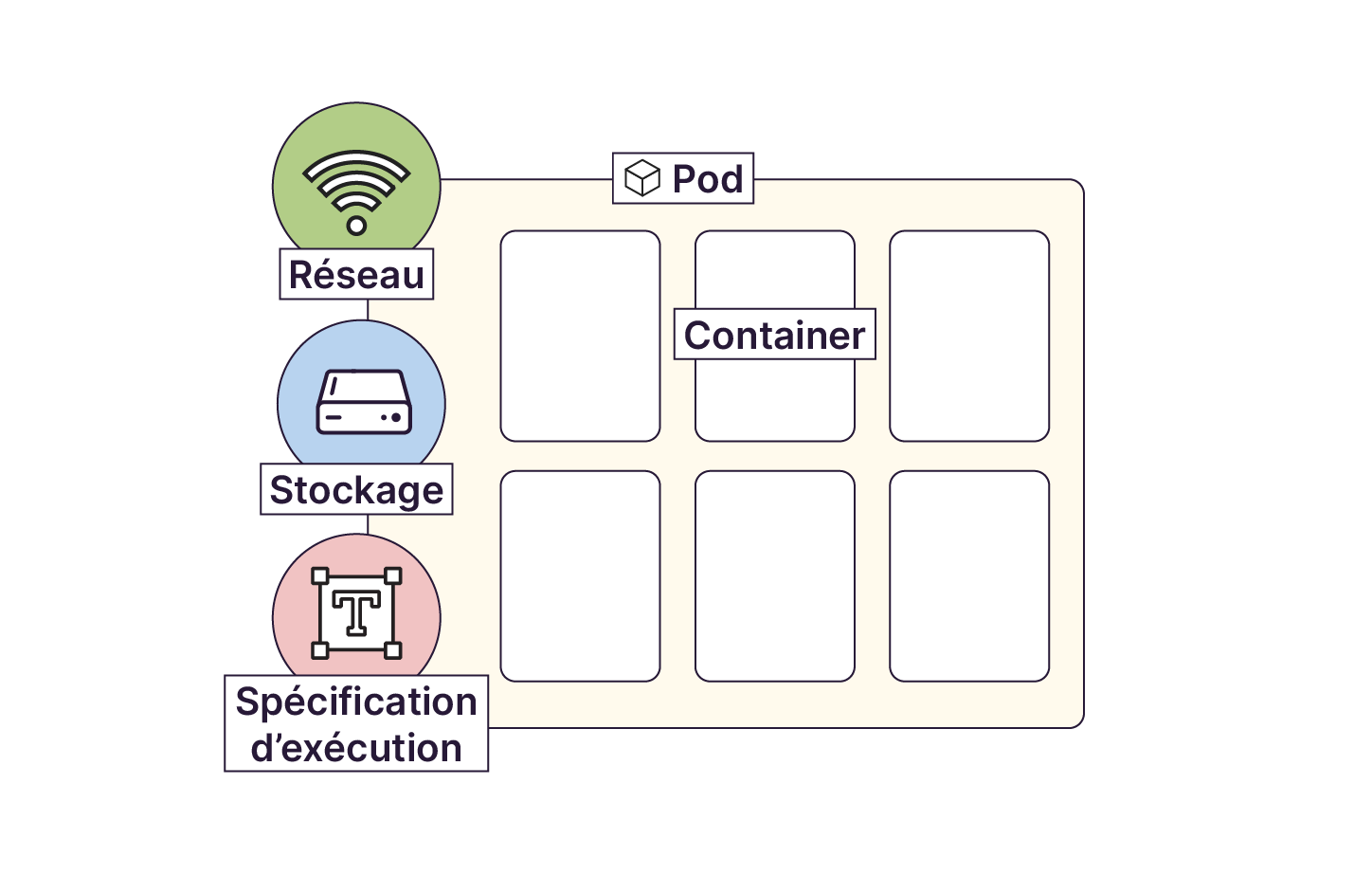
Si nous reprenons l’analogie maritime, un pod est un regroupement de conteneurs maritimes qui sont déployés au même endroit sur le même bateau.
Pourquoi avoir besoin de regrouper les conteneurs ?
Très bonne question ! Dans des cas complexes, il est nécessaire de toujours déployer certains pods au même endroit. Cela facilite la gestion des déploiements.
De plus, les conteneurs au sein du même pod peuvent partager les mêmes volumes, ce qui est pratique pour persister de la donnée sans avoir à la faire transiter.
Enfin, il existe des conteneurs spéciaux au sein du pod que l’on appelle des init-container et des sidecar-container. Voyons cela de plus près :
Initialisez votre application avec l’Init-container
Si nous reprenons le déploiement du site d’e-commerce de LiveCorp, l’application a besoin d’injecter des variables d'environnements au démarrage, comme la chaîne de connexion à la base de données. La valeur de cette chaîne peut changer entre les différents environnements, il est donc difficile de l'injecter dans l’image qui sera réutilisée entre les environnements. C’est là où intervient l’init-container !
Le pod peut avoir un conteneur qui démarre avant le conteneur principal, que l’on appelle init container, et dont le but est d’initialiser le conteneur principal. L’init container peut aussi avoir une image différente du conteneur principal.
Par exemple, lors du démarrage d’un conteneur de base de données, il arrive parfois que l’on veuille créer un schéma de base de données, ou mettre à jour ce dernier. L’init container peut alors prendre en charge cette initialisation sans devoir installer dans l’image principale des outils de migration. L’image principale reste alors légère.
De même, vu que le pod partage un volume avec tous les autres conteneurs, il est alors possible de déléguer la création de données dans un volume à un init container. Par exemple, s’il est nécessaire de récupérer des données sur Internet au premier démarrage ou de cloner un repository dans le volume, l’init container pourra s’en charger.
L’avantage d’un init container est que ce conteneur n’est exécuté qu’une fois au démarrage du pod et s’arrête une fois sa tâche accomplie.
Ajoutez des fonctionnalités grâce au sidecar container
De plus, le déploiement du site e-commerce de LiveCorp nécessite d’avoir accès à certaines métriques afin de bien exploiter l’application, comme le nombre d’utilisateurs connectés ou la consommation de processeur. Afin de se concentrer sur le développement de l’application, vous pouvez déléguer cette tâche à un système externe. C’est là où intervient le sidecar container !
Le pod peut aussi avoir un conteneur qui tourne à côté du conteneur principal que l’on appelle sidecar container.
Ces conteneurs sont utilisés pour améliorer ou étendre la fonctionnalité du conteneur de l'application principale en fournissant des services supplémentaires ou des fonctionnalités telles que la journalisation, la surveillance, la sécurité ou la synchronisation des données, sans modifier directement le code de l'application principale.
Contrairement à l’init container, ce conteneur continue de s’exécuter tant que le pod est en cours d’exécution. Ces deux conteneurs sont donc complémentaires.
Les sidecar containers exécutent généralement des fonctions de support comme par exemple récupérer les logs de l’application et les envoyer à un serveur central, ajouter une couche d’authentification ou avoir une gestion fine des permissions applicatives.
Analysez le cycle de vie d’un pod
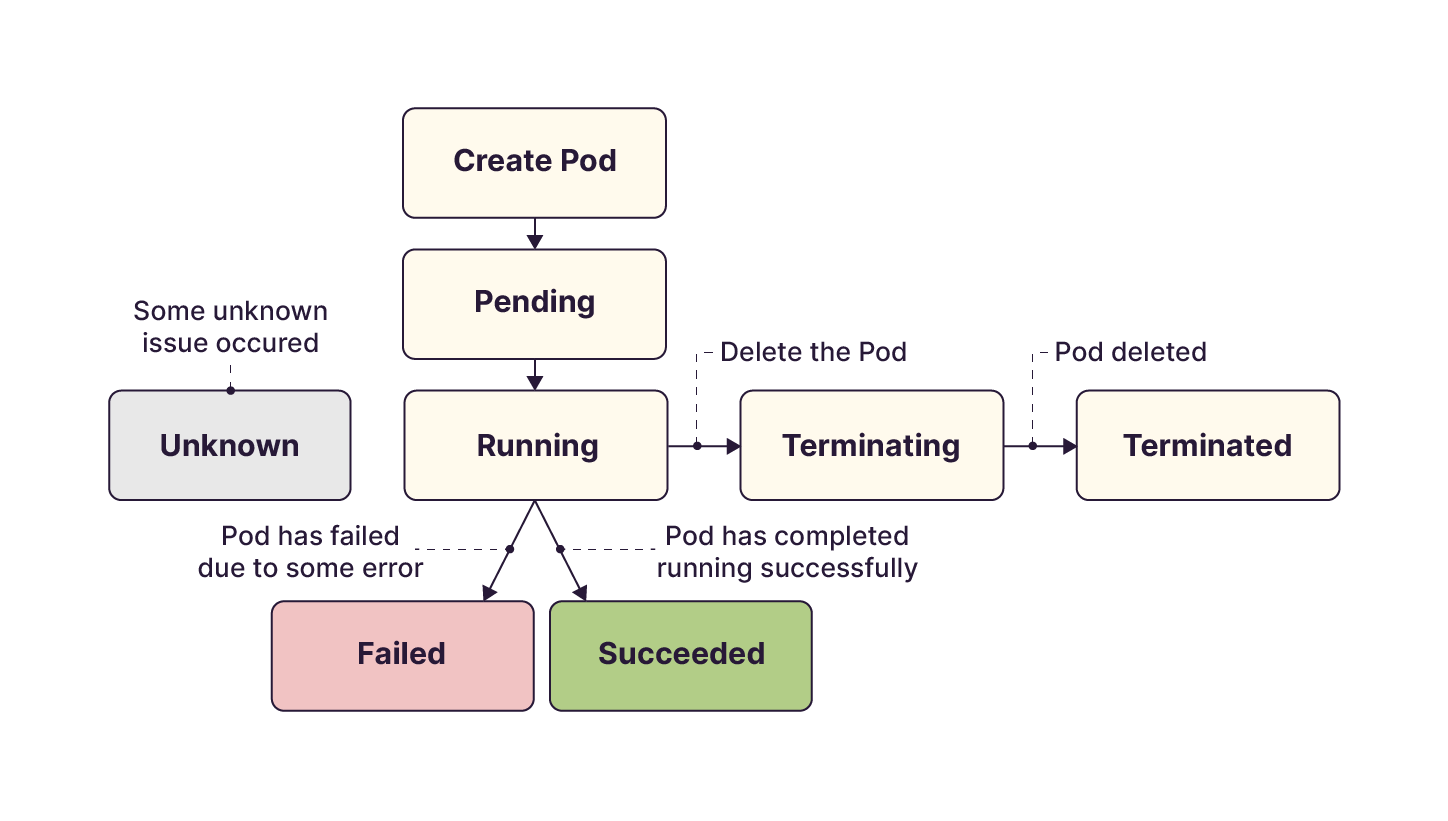
Un pod a un cycle de vie afin de connaître son état de santé. Lors du premier déploiement, son état est à Pending, ce qui signifie qu’il est prêt à être déployé. Kubernetes s’occupera alors de le déployer sur un nœud qui respecte les contraintes du pod (par exemple un nœud avec un GPU, avec beaucoup de mémoire ou beaucoup de CPU).
Une fois que le pod a été déployé, son état passe à Running. Cela signifie que le pod s’exécute correctement et que les conteneurs sont en bonne santé.
Son état peut passer à Failed si une erreur est présente lors du déploiement du pod. Il peut s’agir d’un mauvais nom d’image, d’un volume inexistant, de problèmes de permissions ou même un problème de capacité d’exécution du cluster.
Si le pod a fini de s’exécuter correctement, son état passe alors à Succeded.
Enfin, lors de la destruction d’un pod, son état passe respectivement de Terminating, à Terminated, indiquant que le pod a bien été détruit dans le cluster.
L’image ci-dessous résume le cycle de vie que peut avoir un pod.
Si je résume, le site e-commerce de LiveCorp a besoin de plusieurs conteneurs :
Le conteneur principal contenant l’application ;
Un init-container pour initialiser la variable de connexion de la base de données ;
Un sidecar-container afin d'accéder à différentes métriques.
Il est temps pour vous d’interagir plus fortement avec Kubernetes et de déployer votre premier pod !
Déployez votre pod dans le cluster
Dans ce screencast, vous avez vu comment :
récupérer les informations de connexion au cluster Kubernetes ;
déployer notre premier pod au sein du cluster ;
vérifier que le pod s’exécute bien ;
scaler ce pod pour pouvoir supporter la charge.
Interagissez avec le cluster
Comme vous l’avez sûrement remarqué, l'interaction avec le cluster Kubernetes passe par la commande kubectl .
kubectl est la commande principale avec laquelle vous interagissez avec le cluster. Elle permet de réaliser plusieurs opérations comme le déploiement d'applications, la gestion et l’inspection des différentes ressources, l'aperçu des logs des conteneurs, ainsi que gérer la configuration du cluster.
minikube embarque kubectl dans son interface. vous pouvez utiliser la commande minikube kubectl – <command> pour interagir avec Kubernetes.
Vous pouvez aussi créer un alias afin de faciliter ces commandes
alias kubectl="minikube kubectl --"
ou installerkubectl sur votre système comme indiqué sur Install Tools ici.
Dans la suite du cours, nous partirons du postulat que la commandekubectl fonctionne directement, sans passer par minikube.
kubectl s’appuie par défaut sur un fichier présent dans le dossier .kube qui s’appelle config et qui contient la configuration d'accès de tous vos clusters. Lors de l’installation, minikube vous a créé le fichier afin que vous puissiez accéder à minikube.
Voici un fichier d'exemple basé sur minikube :
apiVersion: v1
kind: Config
clusters:
- name: minikube
cluster:
certificate-authority: /home/laurent/.minikube/ca.crt
server: https://192.168.39.217:8443
users:
- name: minikube
user:
client-certificate: /home/laurent/.minikube/profiles/minikube/client.crt
client-key: /home/laurent/.minikube/profiles/minikube/client.key
contexts:
- name: minikube
context:
cluster: minikube
namespace: default
user: minikube
current-context: minikubeIl existe trois sections dans ce fichier YAML :
la section clusters qui liste tous les clusters que vous avez déjà connectés. Dans ce cas, il n'y en a qu'un seul, nommé minikube. Ce nom est arbitraire et peut être n'importe quel nom. Dans cette section, il existe deux sous-sections.
certificate-authority qui contient le certificat de connexion au cluster ;
server qui est l’adresse du serveur.
la section users liste tous les utilisateurs déjà utilisés pour se connecter à un cluster. Dans ce cas, il n'y a qu'un seul utilisateur, nommé minikube. Ce nom est arbitraire. Il existe deux sous-sections.
client-certificate contient un certificat pour l'utilisateur signé par l'autorité de certification de Kubernetes. Il peut s'agir d'un chemin d'accès à un fichier ou d'une chaîne Base64 au format PEM du certificat ;
client-key contient la clé qui a signé le certificat du client.
la section contexts spécifie une combinaison d'un utilisateur et d'un cluster. Elle définit également un namespace par défaut pour cette paire. Le nom du contexte est arbitraire, mais l'utilisateur et le cluster doivent être prédéfinis dans le fichier kubeconfig. Si le namespace n'existe pas dans Kubernetes, les commandes échoueront et afficheront le message par défaut de Kubernetes pour un namespace inexistant.
Maintenant que vous savez comment fonctionne kubectl et comment il interagit avec le cluster, voyons ensemble quelques commandes de base :
kubectl get nodesvous permet d’obtenir les informations sur les nœuds du cluster, comme le nombre de nœuds mais aussi la version de Kubernetes déployée sur ces nœuds. Les nœuds sont l’ensemble des machines qui vont supporter les conteneurs du cluster.kubectl get podsvous retourne tous les pods qui tournent dans le namespace par défaut. SI vous ne trouvez pas vos pods, il faut alors ajouter le flag-navec le nom du namespace qui vous intéresse, par exemplekubectl get pods -n monnamespace.kubectl get pods -Aaffichera tous les pods qui tournent sur le cluster, indépendamment du namespace dans lequel tourne le pod.
Déployez votre premier pod
Il est temps pour vous de déployer votre premier pod. Dans cette section, vous allez d’abord déployer une image, puis vérifier que celle-ci a été correctement déployée en récupérant la page d’accueil du site.
La commande suivante déploiera un pod basé sur l’image nginx et exposera le pod déployé sur le port 80 de la machine :
kubectl run nginx --image=nginx --port=80
Cette commande indique à Kubernetes de démarrer un pod avec comme image l’image publique et officielle de nginx, et d’exposer le port 80 en écoute dans le pod.
Vérifiez que votre pod tourne bien
Une fois la commande exécutée, vous pouvez vérifier que le pod a bien été déployé et est en cours d’exécution avec la commande kubectl get pod :
NAME READY STATUS RESTARTS AGE nginx 1/1 Running 0 26s
Vous pouvez enfin vérifier que le conteneur expose bien une page HTML sur le port 80 du pod en exécutant la commande suivante. Cette commande va se connecter au pod et exécuter une commande au sein de celui-ci :
kubectl exec nginx -- curl http://localhost
Cette commande va récupérer la page d’accueil de nginx et l’afficher dans le terminal. Vous devriez avoir le résultat suivant :
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
100 615 100 615 0 0 1068k 0 --:--:-- --:--:-- --:--:-- 600kFélicitations ! Vous venez de déployer votre premier pod !
Vous êtes maintenant prêt pour déployer le site de e-commerce de LiveCorp.
Alice vous explique qu’un seul pod n’est généralement pas suffisant pour supporter la charge des milliers de visiteurs qui se connectent. Il faut alors scaler le nombre de pods pour augmenter la capacité de traitement.
Scalez vos pods pour supporter la charge
Kubernetes permet de faire varier le nombre de pods manuellement. Cela est pratique dans le cas où un gros volume d’utilisateurs arrive sur l’application et que l’application a besoin de scaler pour supporter ce pic de charge.
Pour augmenter le nombre de pods, il suffit alors de démarrer autant de pods que nécessaire en répétant la commande précédemment définie, c’est-à-direkubectl run . Vous allez maintenant augmenter le nombre de pod avec la commandekubectl afin qu’il existe 5 pods dans le cluster.
kubectl run nginx2 --image=nginx --port=80 kubectl run nginx3 --image=nginx --port=80 kubectl run nginx4 --image=nginx --port=80 kubectl run nginx5 --image=nginx --port=80
Mais attendez, il n’existe pas une manière automatique de scaler l’application ?
Effectivement, vous n’allez pas passer votre temps à augmenter ou diminuer le nombre de pod manuellement. Dans Kubernetes existe aussi un composant qui s’appelle le Horizontal Pod Autoscaler (HPA). Son rôle est de scaler horizontalement les pods, c'est-à-dire augmenter le nombre de pods dans le cluster, afin que ceux-ci puissent traiter l’information plus efficacement en fonction de la demande. Il ajuste le nombre de pods d'un déploiement, d'un contrôleur de réplication ou d'un ensemble de réplicas en fonction de l'utilisation des ressources. On parle de scaling horizontal car on modifie le nombre d'instances exécutant l'application, plutôt que les ressources allouées à une instance individuelle (scaling vertical).
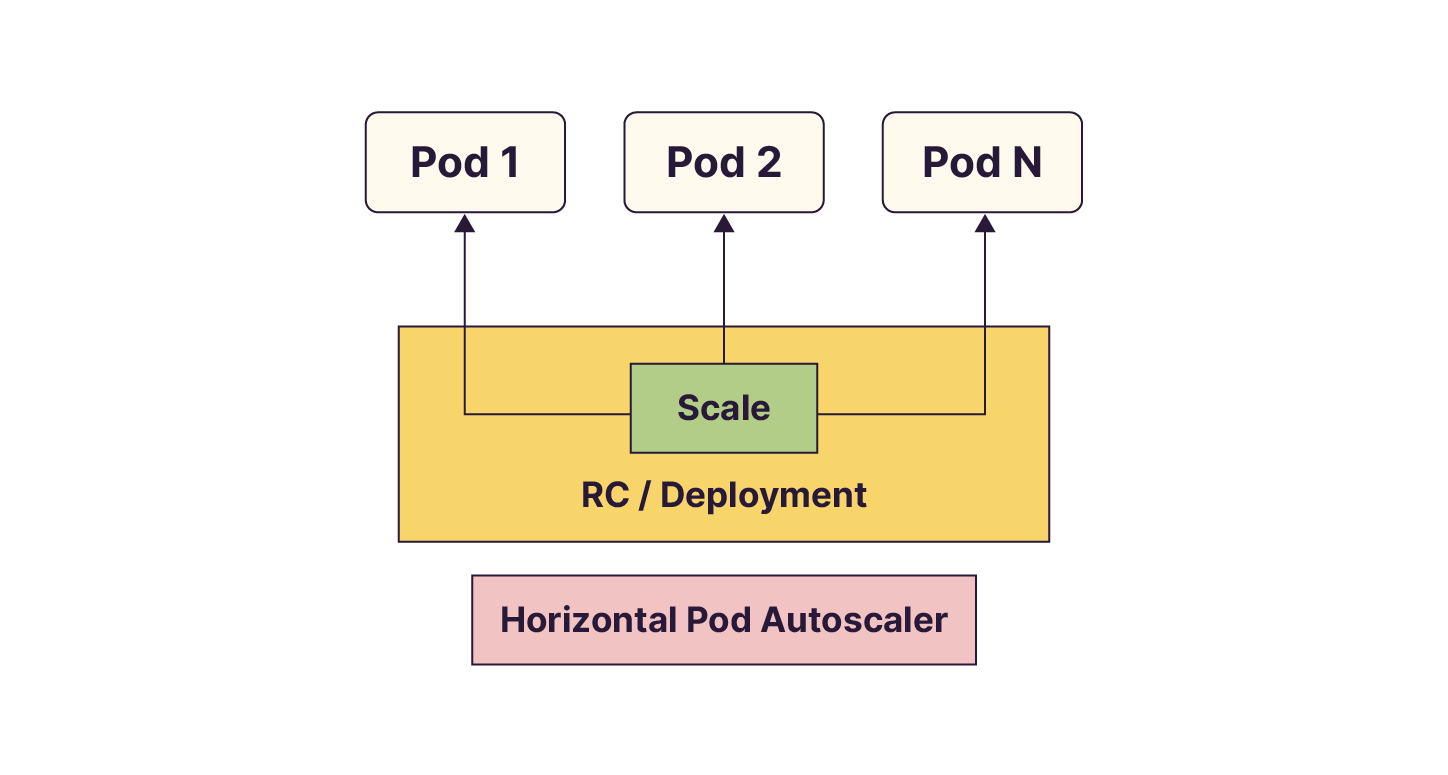
OK j’ai compris comment ça fonctionne. Mais il se base sur quoi pour décider de scaler ou non ?
Comme expliqué dans le déploiement d’un pod, vous pouvez déployer un sidecar-container qui contiendra des métriques propres à l’application. Ces métriques seront utilisées pour prendre des décisions de scaling. Vous pouvez définir des paramètres de scaling et configurer le HPA pour surveiller une métrique spécifique, comme l'utilisation du CPU.
Un objectif est ensuite défini, par exemple un taux d'utilisation CPU cible de 50 %. Enfin, une limite minimum et maximum de pods est spécifiée. Cette limite est le nombre de pods que l'HPA peut créer, par exemple minimum 2 pods afin de garantir une haute disponibilité et maximum 10 pour supporter la charge.
Et comment fonctionne le HPA ? Il se base sur des métriques, mais elles sont stockées où ?
Ces métriques sont stockées dans le cluster Kubernetes. L’HPA fonctionne en interrogeant régulièrement le cluster pour connaître l'utilisation moyenne des ressources des pods.
Et le HPA est aussi capable de réduire le nombre de pods s’il y en a trop ?
Alors, oui ! Si l'utilisation est supérieure à l'objectif, l'HPA crée des pods supplémentaires pour répartir la charge.
Si l'utilisation est inférieure à l'objectif et que le nombre de pods minimum n’a pas été atteint, l'HPA peut supprimer des pods afin de libérer des ressources pour d'autres applications.
L'HPA permet aux applications de scaler automatiquement pour répondre à une demande accrue et de réduire le nombre de pods lorsque la demande diminue. Cela se traduit par une meilleure utilisation des ressources et une meilleure réactivité de l'application.
À vous de jouer

Contexte
Alice : Maintenant que tu as construit l’image du site e-commerce et que tu l’as envoyé sur la registry, tu es prêt à la déployer sur Kubernetes !
Vous allez devoir déployer le site e-commerce avec la commandekubectl run sur le cluster minikube afin de déployer vos premiers pods. Cette première commande déploiera le site sur le cluster.
Par la suite, il faudra aussi démarrer 4 nouveaux pods afin que le total soit de 5 pods. Cela est nécessaire pour que le site puisse supporter la charge et assure une haute disponibilité de l’application.
Consignes
Récupérer les informations de connexion au cluster minikube ;
Déployer votre premier pod avec l’image du site e-commerce précédemment créée.
En résumé
Un pod est un regroupement de plusieurs conteneurs.
L’init-container sert à initialiser l’application durant son démarrage.
Le sidecar-container sert à ajouter des fonctionnalités à un conteneur principal.
La commande
kubectlpermet d’interagir avec le cluster Kubernetes.Les pods peuvent scaler pour absorber des pics de charge.
Le Horizontal Pod Autoscaler s’occupe de scaler les pods automatiquement.
Dans le prochain chapitre, vous allez découvrir la structure de ces fichiers et comment créer votre déploiement à travers ces fichiers.
