Passez à l'échelle avec Docker Swarm
En arrivant au bureau, vous voyez un nouveau message de Sarah en attente dans le chat d’entreprise :
Hello ! Bon, je viens de terminer les estimations de coûts d’infrastructure vis-à-vis de la volumétrie attendue. On ne pourra pas assumer le prix des ressources RAMs/CPUs si on essaye de tout faire fonctionner sur une seule machine… Il faudrait qu’on puisse répartir la charge sur plusieurs machines plus petites, ce serait plus abordable.
Heureusement, vous savez qu’il existe une solution à ce problème : Docker Swarm !
Dans ce chapitre, nous allons explorer Docker Swarm, une fonctionnalité native de Docker permettant de gérer des clusters de conteneurs, facilitant le passage à l’échelle de vos applications conteneurisées.
Une bonne maîtrise de celui-ci peut améliorer votre capacité à affronter la montée en charge et la résilience de vos services.
Découvrez Docker Swarm
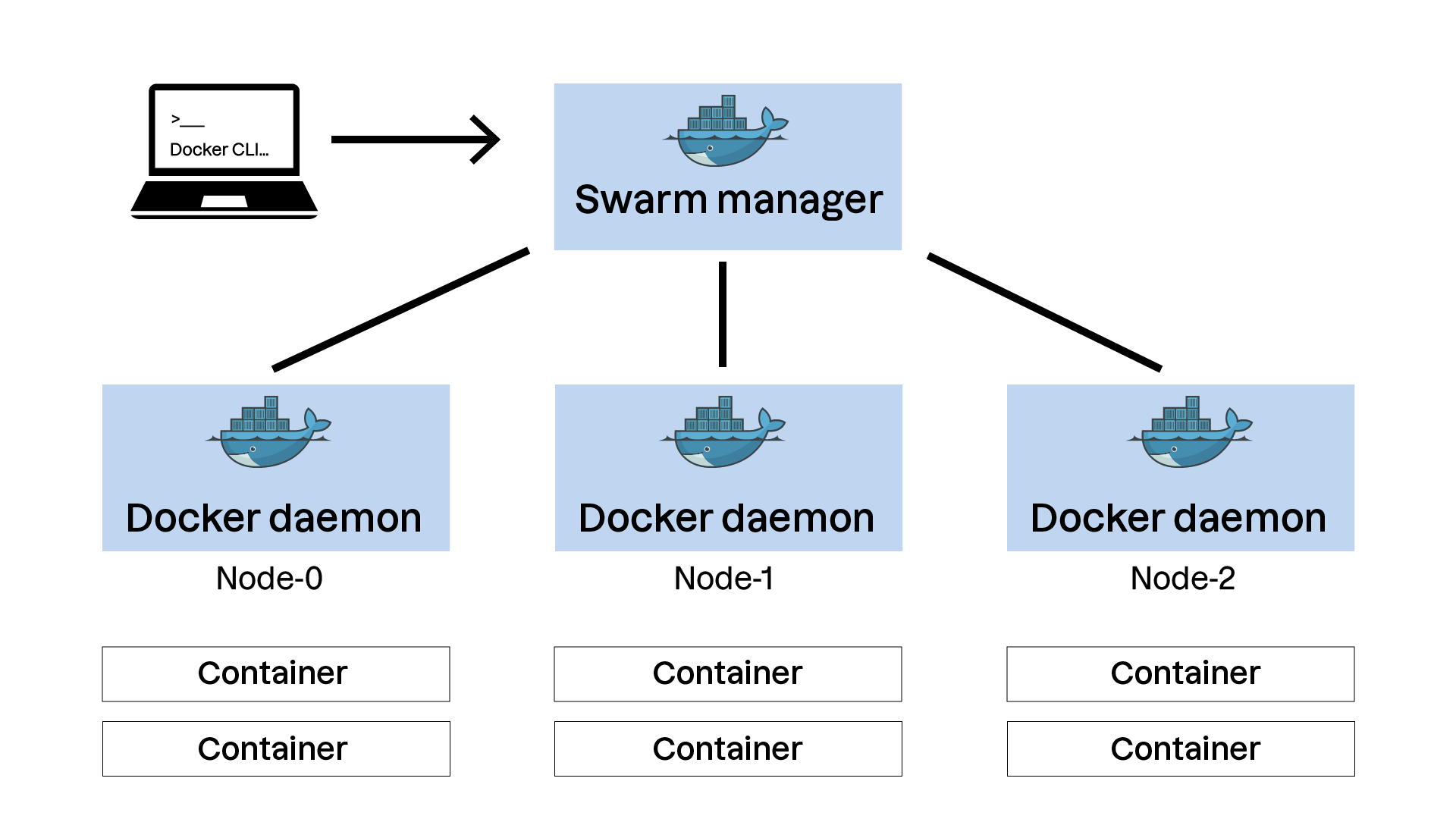
Docker Swarm vous permet de regrouper plusieurs hôtes Docker en un cluster et de les gérer de manière centralisée.
Un cluster ?
Un est un groupe de plusieurs ordinateurs ou serveurs interconnectés qui travaillent ensemble pour accomplir une tâche commune. L'objectif principal d'un cluster est d'augmenter les performances, la disponibilité et la redondance.
Un cluster Docker Swarm est composé de plusieurs nœuds, chacun exécutant le moteur Docker. Il existe deux types de nœuds :
Nœuds Managers (gestionnaires) :
Ils gèrent l'état global du cluster et prennent les décisions concernant le déploiement et la gestion des services.
Ils peuvent également exécuter des conteneurs, mais leur rôle principal est la gestion du cluster.
Pour garantir la haute disponibilité, il est recommandé d'avoir un nombre impair de nœuds managers (au moins 3).
Nœuds Workers (travailleurs) :
Ils exécutent les conteneurs et répondent aux ordres des nœuds managers.
Ils ne prennent pas de décisions de gestion du cluster.
Le client Docker est ensuite utilisé pour envoyer des instructions à un des noeuds “manager”, qui se chargera de transformer celles-ci en opérations concrètes sur le cluster.
Et la sécurité dans tout ça ?
La communication entre les nœuds est sécurisée grâce à des certificats TLS, générés automatiquement lors de l'initialisation du cluster. Cela garantit que seules les machines autorisées peuvent rejoindre et interagir avec le cluster. Lors de l’ajout d’un nœud au cluster, un token à usage unique est utilisé pour l’authentification du nouveau nœud.
D’un point de vue conceptuel, Docker Swarm s’axe autour de 3 grandes fonctionnalités :
Un modèle déclaratif
Dans Docker Swarm, vous définissez l'état désiré de votre application à l'aide d'un fichier de configuration, tel qu'un fichier Docker Compose. Docker Swarm se charge ensuite de maintenir cet état. Plus précisément, ce modèle déclaratif suit les principes suivants :
Déclaration : Vous décrivez les services, réseaux et volumes dans un fichier de configuration.
Orchestration : Docker Swarm orchestre le déploiement et la gestion des services pour correspondre à la déclaration.
Auto-réparation : En cas de défaillance, Swarm rétablit automatiquement l’état souhaité.
Un réseau “overlay”
Docker Swarm utilise un réseau overlay pour permettre une communication sécurisée entre les conteneurs sur différents hôtes au sein du cluster.
Celui-ci est automatiquement créé par Docker lorsque vous initiez un cluster Swarm. Il permet aux services de communiquer entre eux via des réseaux virtuels, indépendamment de l'hôte physique sur lequel ils s'exécutent.
Ceci offre plusieurs avantages :
Isolation du réseau : La couche réseau étant décorrélée du réseau physique, chaque service peut avoir son propre réseau isolé des autres.
Sécurité : Le trafic entre conteneurs peut être chiffré directement au niveau du réseau overlay.
Simplicité : Les conteneurs peuvent être déplacés entre les hôtes sans reconfiguration réseau, et de manière automatisée.
Rolling updates
Les rolling updates (mises à jour progressives) sont une fonctionnalité clé de Docker Swarm. Elles permettent de mettre à jour les services sans interruption de service en déployant progressivement les nouvelles versions des conteneurs et en retirant les anciennes versions. Ce mécanisme apporte les avantages suivants:
Gradualité : Les mises à jour sont déployées par étapes pour éviter une coupure totale.
Contrôle : Vous pouvez spécifier le nombre de conteneurs à mettre à jour simultanément
Rollback (retour arrière) : En cas de problème, vous pouvez revenir à la version précédente.
Concrétisons la théorie en passant à la pratique : il est temps de créer votre premier cluster Swarm.
Créez votre premier cluster Swarm
Dans cette vidéo nous allons découvrir ensemble comment amorcer un cluster Swarm et explorer ensemble les principales commandes de gestion de celui-ci.
Dans cette vidéo, nous avons vu :
1/ L’initialisation d’un cluster Swarm avec la commande :
docker swarm init
2/ La commande permettant de générer un jeton d’authentification pour joindre un nouveau nœud au cluster :
docker swarm join-token worker
3/ Comment joindre un nœud au cluster avec la commande :
docker swarm join --token <worker-token> <manager-ip>:2377
4/ La commande permettant de lister les nœuds du cluster :
docker node ls
5/ La commande permettant d’inspecter un nœud spécifique :
docker node inspect <node-id>
Maintenant que votre cluster est prêt à l’emploi, adaptons notre premier environnement applicatif à celui-ci et déployons-le !
Déployez une stack Compose sur votre cluster
Une “stack” Swarm est également décrite par un fichierdocker-compose.ymlintégrant des sections spécifiques au déploiement sur un cluster.
Voyons un exemple :
services:
web:
image: myapp:1.0
deploy:
replicas: 3
update_config:
parallelism: 1
delay: 10s
restart_policy:
condition: on-failure
ports:
- "80:80"Dans cet exemple :
Le service web utilise l'image
myapp:1.0.Il est déployé avec 3 réplicas i.e. 3 instances du même conteneur seront déployées et réparties sur les différents nœuds du cluster Swarm, permettant ainsi une répartition potentielle de la charge.
Les mises à jour progressives sont configurées pour mettre à jour un conteneur à la fois (
parallelism: 1) avec un délai de 10 secondes entre chaque mise à jour (delay: 10s).La politique de redémarrage
restart_policyest définie pour redémarrer le conteneur en cas d'échec.
Comme vous pouvez le voir, il n’y a aucune différence fondamentale entre un fichierdocker-compose.ymlclassique et celui utilisable par Docker Swarm.
Les instructions supplémentaires permettent simplement d’indiquer au moteur de conteneurisation comment gérer la topologie de déploiement à partir du moment où notre environnement applicatif doit être distribué sur plusieurs machines.
Déployons maintenant cet environnement sur notre cluster Swarm ! Dans la vidéo suivante, nous aborderons les commandes permettant d’effectuer cette opération.
Dans cette vidéo, nous avons vu :
1/ La commande permettant de déployer une “stack” sur le cluster Swarm :
docker stack deploy -c docker-compose.yml <stack-name>
2/ La commande permettant de lister les stacks déployées :
docker stack ls
3/ La commande permettant de lister les tâches (conteneurs) en cours d’exécution dans une stack spécifique :
docker stack ps <stack-name>
4/ La commande permettant de supprimer une stack :
docker stack rm <stack-name>
Vous êtes désormais en mesure de déployer des applications conteneurisées capables d’absorber des hautes volumétries d’utilisateurs en profitant des fonctionnalités offertes par Docker Swarm !
À vous de jouer

Contexte
Dans un email, Sarah vous informe que les machines virtuelles sont prêtes pour réaliser l’expérimentation de déploiement sur Docker Swarm !
Dans cet email, vous retrouvez les informations de connexion SSH ainsi qu’un message :
Voilà, à la demande de Liam voici 3 machines prêtes pour tester la création du cluster et le déploiement de Libra sur celui-ci. Ta clé SSH est déjà déployée sur le compte
operator, il estsudoer.Préviens-nous quand le déploiement est réalisé, et pense à prendre des notes afin qu’on puisse reproduire à notre tour le déploiement ensuite !
Dans le cadre de cet exercice, vous devrez initier votre propre cluster Docker Swarm sur une infrastructure virtualisée.
Consignes
Initiez un cluster Docker Swarm en utilisant l’environnement mis à votre disposition sur ce dépôt Github
Adaptez le fichier
docker-compose.ymlréalisé dans le cadre du chapitre 3 afin de le préparer pour une utilisation sur un cluster Docker Swarm. Notamment :L’application Libra devrait avoir 3 instances.
Le parallélisme pour la mise à jour progressive devrait être à 1.
Le délai pour la mise à jour progressive devrait être à 5 secondes.
Déployez l’environnement sur votre cluster Swarm.
Vérifiez que le déploiement est fonctionnel en inspectant les tasks en cours d’exécution sur le cluster Swarm avec les commandes dédiées.
En résumé
Un cluster Swarm est composé de nœuds managers, qui gèrent l'état global du cluster, et de nœuds workers, qui exécutent les conteneurs selon les instructions des managers, assurant une orchestration efficace.
Une “stack” est définie par un état désiré dans un fichier de configuration, et Docker Swarm maintient automatiquement cet état, assurant ainsi l'auto-réparation et la continuité du service.
Docker Swarm utilise un réseau overlay pour permettre une communication sécurisée et isolée entre les conteneurs sur différents hôtes du cluster.
Docker Swarm facilite les mises à jour continues en déployant progressivement les nouvelles versions de conteneurs, minimisant les interruptions de service.
À ce stade, vous avez déjà une assez bonne vision de l’ensemble des fonctionnalités qu’offre Docker, et ainsi comment déployer vos propres applications sous forme de conteneurs.
Il est temps pour vous de passer à l’étape suivante : la fiabilisation et l’optimisation de vos déploiements. Mais avant cela, je vous invite à tester vos connaissances dans le quiz clôturant cette partie.
