Installez UV et lancez votre premier environnement virtuel

Découvrez l’utilité d’UV
Avant de se lancer dans l’installation de Poetry, il est essentiel de comprendre que sans un tel outil ou un équivalent, votre projet Dev ou Data en Python peut être confronté à plusieurs problèmes. Dans ce cours, vous apprendrez à gérer votre environnement avec UV, un outil moderne, ultra-rapide et complet qui permet de centraliser la gestion des dépendances, des environnements virtuels et des versions de Python.
Qu’est-ce qui peut se passer quand on travaille sur un projet en Python sans utiliser UV ?
Imaginons que vous travaillez sur un projet Dev ou Data depuis quelques semaines. Votre code et/ou vos Jupyter Notebooks fonctionnent aujourd’hui très bien sur votre ordinateur. En revanche, au fur et à mesure que votre projet gagne en visibilité par son succès, les lignes de codes ainsi que la quantité de packages utilisés vont se multiplier. Vous risquez ainsi de rencontrer au moins l’un des problèmes suivants (si ce n’est pas plusieurs en même temps) :
1 - Votre collègue n’arrive pas à faire tourner votre code.
En partageant simplement votre notebook avec un de vos collègues (en règle générale via Git, mais le raisonnement reste le même par e-mail, sharepoint ou autre), il n’y a aucune garantie que votre collègue soit capable de reproduire votre code.
En effet, les versions de Python et des packages (Pandas, SQLAlchemy, Seaborn etc.) qu’il a installées sur son ordinateur pourraient ne pas être identiques aux vôtres.
Si votre code utilise des fonctionnalités nouvelles ou obsolète d’un package (car votre version est différente), votre code ne fonctionnera pas comme prévu lors de son exécution, voire ne fonctionnera pas du tout.
Rencontrer ce problème devient de plus en plus probable si le nombre de packages que vous utilisez augmente.
2 - Votre projet devient plus complexe, et vous n’arrivez pas à installer de nouveaux packages.
Si les besoins de votre projet vous poussent à installer d’autres packages de manière directe, vous pouvez rencontrer des problèmes d’installation à cause de conflits de version.
En effet, quand vous installez un package comme Pandas, vous installez en réalité plusieurs sous-packages simultanément sous le capot. Nous appelons ces packages dessous-dépendances. Les librairies incontournables en Python pour l’analyse de données (comme Pandas et scikit-learn par exemple) possèdent des sous-dépendances.
Prenons cet exemple fictif, mais tout à fait plausible pour illustrer :
Si vous avez installé la version 1.3.5 de Pandas, vous avez probablement comme sous-dépendance la version 1.17.3 de Numpy.
Si vous essayez alors d’installer scikit-learn de manière directe pour les besoins de votre projet, sans préciser de version spécifique, vous aurez probablement une version récente de scikit-learn qui utilise comme sous-dépendance la version 1.20.0 de Numpy.
L’installation de scikit-learn va échouer, car votre ordinateur ne peut pas faire coexister deux versions différentes de Numpy dans le même environnement.
Dans le monde du développement et de la data, nous appelons ce type de problème le “dependency hell” (autrement dit, l’enfer des dépendances). Il est très probable de le rencontrer quand vous multipliez les installations directes de packages, surtout quand vous utilisez des packages peu connus (et donc mis à jour moins souvent que des packages phares comme Pandas) ou alors au contraire connus pour leur quantité massive de sous-dépendances (Comme PyTorch ou Tensorflow).
3 - Votre package préféré fait peau neuve et vous voulez capitaliser sur ces nouvelles fonctionnalités
Admettons par exemple qu’un projet Dev ou Data sur lequel vous avez travaillé et déployé par le passé, utilise beaucoup Pandas pour manipuler et transformer de la donnée. Vous avez mis en production ce projet fin 2022 et vous y réalisez de la maintenance minimaliste de temps en temps pour gérer des bugs.
Vous apprenez ensuite que le tout nouveau Pandas 2.0 est désormais disponible depuis avril 2023 et qu’il propose :
Plusieurs nouvelles fonctionnalités qui permettent de simplifier le code de votre projet.
Une nouvelle sous-dépendance nommée PyArrow, qui accélère plusieurs calculs de Pandas et permet de diviser le temps d’exécution du code par 2 ou 3 ou plus !
Naturellement, vous souhaitez installer de manière directe cette nouvelle version. Mais vous êtes désormais confronté au dependency hell, car la nouvelle sous-dépendance PyArrow rentre en conflit direct avec tous les autres packages que le projet requiert. Vous gagnerez alors du temps sur le long terme en utilisant un outil qui gère automatiquement cette complexité à votre place.
Je comprends toute cette histoire de conflit de versions de packages et de dependency hell. Mais vous avez employé plusieurs fois l’expression “installer de manière directe”, qu’est-ce que cela signifie ?
Bonne question ! Par “installation directe” d’un package X, j’entends une installation qui ne va pas se soucier de la compatibilité de la version du package X (et surtout de ses sous-dépendances ) avec les packages qui existent déjà dans votre environnement de travail. C’est ce qu’on a envie d’éviter.
Par exemple, Pip est l’outil phare d’installation de packages en Python qui ne réalise que des installations directes. Il était d’ailleurs l’un des outils conventionnels dans le monde de la Data jusqu’à très récemment. Mais quand les équipes Data en entreprise ont commencé à rencontrer tous les problèmes cités plus haut et à s’intéresser au MLOps, ils se sont tournés vers des alternatives plus intelligentes comme UV.
Définissez UV
UV combine 2 concepts :
La gestion automatisée et intelligente des dépendances et sous-dépendances.
La création d’un environnement virtuel isolé pour votre projet.
Ce deuxième point est particulièrement important à comprendre !
En plus d’être très simple à utiliser, UV a l’avantage d’utiliser le format moderne .toml qui est le standard aujourd’hui en Python quand il s’agit d’installation de packages. Ainsi, UV s'intègre très bien avec d’autres outils contemporains utilisés par les Data Scientists, ML Engineers et Data Engineers, car ils utilisent également ce format.
Partager un environnement UV (via le fichier .tom et le fichier.lock dont on parlera tout à l’heure) avec un collègue lui permet alors de reproduire votre environnement de travail (et donc vos résultats) à l’identique dans la quasi-totalité des cas, dans un environnement virtuel qui se moque de savoir si votre collègue utilise Mac ou Windows, ou de savoir comment il a installé tous ces packages ou logiciels.
Et donc UV est la seule alternative à Pip qui peut gérer de manière intelligente les dépendances dans un environnement virtuel ?
Pas du tout, d’autres outils de package management existent comme Poetry, Pipenv ou Conda. Il y a de vastes débats concernant les avantages et les inconvénients de chacun, et les comparer en détail sortirait du cadre de ce cours. Mais nous allons nous contenter de citer les deux arguments suivants :
UV est le seul package manager à utiliser le langage Rust sous le capot. Ce qui fait de lui l’outil le plus rapide de très loin pour installer un ensemble complexe de packages
Conda, le package manager le plus connu chez les Data Scientists juniors, est souvent utilisé en conjonction avec la suite Anaconda qui n’est pas gratuite pour les entreprises de plus de 200 employés. Alors qu’UV est un outil 100% open source, ne nécessitant aucune licence commerciale.
Je pense que vous avez eu votre dose d’explications théoriques ;) Passons désormais à l’installation !
Installez UV et votre premier environnement
UV est très simple à installer. Il suffit de suivre les instructions de leur documentation officielle. Privilégiez une installation via votre Terminal, plutôt qu’avec pip en Python.
Une fois installé, vous pouvez vérifier que votre installation s’est correctement déroulée en tapant dans le même terminal la commande :
<span><span><span>‘’’(bash)
</span>
<span>uv
</span>
<span>‘’’
</span>
<span>Ce qui devrait vous afficher un message comme ceci :
</span>
<span>‘’’(bash)
</span>
<span>An extremely fast Python package manager.
</span>
<span>Usage : uv [OPTIONS] <command></command>
</span>
<span>etc.
</span>
<span>‘’’
</span></span></span>Si cette étape ne fonctionne pas, vous pouvez essayer de redémarrer le terminal avant de la retester.
Déclarez des packages
Lancer dans votre terminal la commande :
uv init nom_dossier_de_votre_choix
Cela va créer dans votre répertoire actuel, un nouveau dossier avec le nom que vous avez spécifié. Au sein de ce dossier, vous allez trouver 3 fichiers :
Un README.md, exactement le même que dans un répo Git. Il a le même objectif et ne vous fait que gagner un peu de temps au lieu de le créer par vous-même.
Un script python
main.py, qui n’est en réalité qu’un script générique, ne contenant pas grand-chose.Un fichier
pyproject.toml. C’est le fichier le plus important parmi les 3 et le plus central dans votre usage d’UV.
Si vous ouvrez ce fichier pyproject.toml (avec un VSCode par exemple), vous verrez une structure comme la suivante :
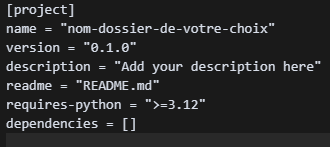
Les deux lignes les plus importantes pour le moment sont celles avec “requires-python” et “dependencies”.
La première ligne vient encadrer la version de Python qui doit être utilisée par le projet où se trouve le fichier pyproject.toml. En effet, le dependency hell n’est pas causé que par des versions différentes de package, mais également par des versions différentes de Python, d’un PC à l’autre (tout simplement car certaines versions de packages sont conçues pour certaines versions de Python et pas d’autres.).
Dans mon screenshot, il est précisé que seules les versions supérieures ou égales à Python 3.12.0 peuvent être utilisées. Cela aura toute son importance juste après.
La ligne “dependencies” se présente comme une liste vide. C’est dans cette liste que nous allons spécifier tous les packages principaux de notre projet.Et nous faisons cela, non pas en remplissant la liste directement, mais en utilisant la commande :
<span><span><span>‘’’(bash)
</span>
<span>uv add nom_du_package
</span>
<span>‘’’
</span></span></span>Assurez-vous toujours que vous vous trouvez dans le même dossier que celui contenant le pyproject.toml ! Je vais utiliseruv add pour ajouter plusieurs packages classiques d’un projet à base machine learning : pandas, scikit-learn, mlflow, matplotlib, ipykernel, shap.
Au moment de mon premier uv add, on voit ceci au niveau du terminal :

Déjà on voit qu’UV est allé chercher dans le PC une version de Python compatible avec ce qui a été spécifié dans le pyproject.toml. Sachez que si le PC n’avait pas cette version de Python d’installée, UV serait allé télécharger et installer cette version de manière autonome.
Ensuite, après la fin de la commande, si vous regardez votre répertoire, vous verrez qu’un nouveau fichier est apparu ! Il s’agit du fichier uv.lock. On va en parler juste après ;)
Après avoir installé tous les packages, regardons à quoi ressemble le fichier pyproject.toml
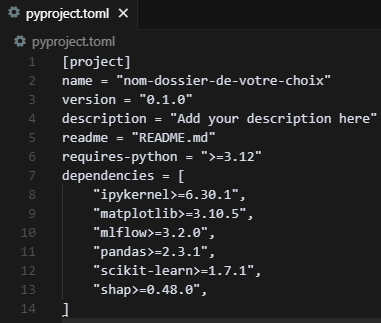
Non seulement les noms de packages sont présents, mais UV a également rajouté des contraintes sur leurs versions. En réalité, nous pouvons contrôler ces contraintes nous-mêmes ! On vous donnera un exemple tout à l’heure ;)
Maintenant passons au fichier uv.lock ! Si vous l’ouvrez, vous verrez un fichier très long … trop long. Toutefois, c’est un fichier très facile à comprendre ! Par exemple, faisons un Ctrl F pour trouver mlflow. Vous devriez trouver un screenshot ressemblant au suivant :
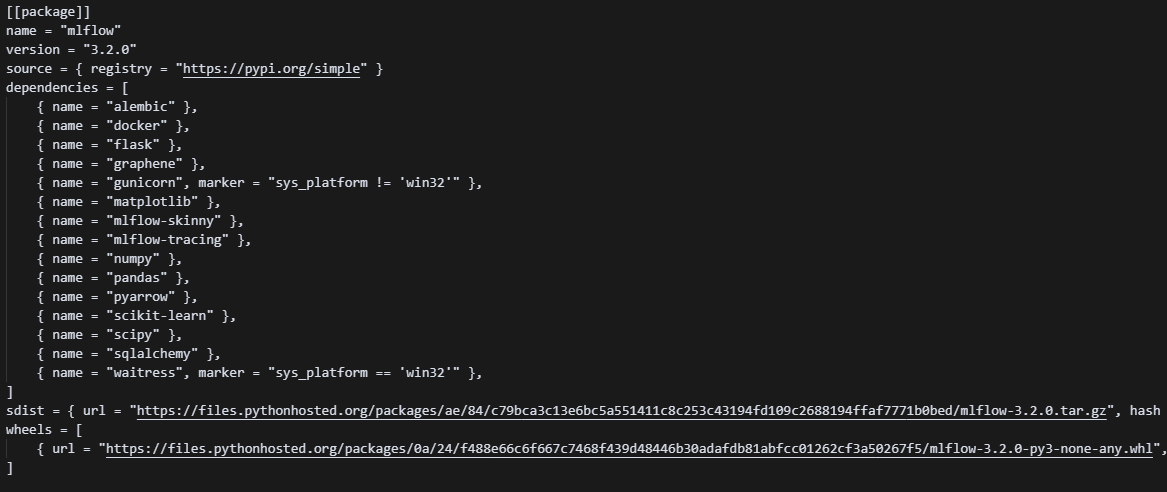
Toutefois, nous avons oublié d’installer certains packages. En effet, nous n’avons pas du tout déclaré à UV qu’on aura besoin de JupyterLab !
Ce n’est pas grave, vous n’avez pas besoin de rajouter vous-même vos dépendances dans le fichier pyproject.toml ! Vous pouvez très facilement rajouter un package manquant à votre environnement en utilisant la commandepoetry add.
Rentrez les commandes suivantes :
uv add ipykernel(si l’installation de la sous-dépendance jedi échoue avec l’erreur “[WinError 206] Nom de fichier ou extension trop long” alors référez-vous à cette réponse dans le forum StackOverflow pour solutionner le problème )uv add jupyterlab
On est tout bon !
Activez votre environnement virtualisé
Pour le moment, l’environnement a été créé grâce aux uv add successifs, mais il n’a pas encore été activé !
Pour ce faire, rentrez dans votre terminal la commande :
.venv\Scripts\activatesi vous êtes sous Windows en Powershellsource .venv/bin/activate
Maintenant, vous êtes dans l’environnement virtuel isolé et vous pouvez lancer votre Jupyter Notebook depuis le terminal avec la commande : jupyter lab .
Une fois que vous avez fini de travailler sur votre projet pour aujourd’hui, revenez sur votre terminal et tapez deactivate. Ceci vous fait quitter votre environnement virtuel dédié au projet.
Avec UV, vous pouvez également effectuer les opérations suivantes :
Désinstaller une dépendance :
uv removeRafraîchir votre environnement virtuel, si jamais vous avez modifié le fichier
pyproject.toml : uv syncSi vous êtes curieux, vous pouvez regarder toutes les sous-dépendances de vos packages avec :
uv treeSi vous êtes encore plus curieux, voici toutes les commandes possibles que vous pouvez réaliser avec UV.
En résumé
Le dependency hell est un problème récurrent dans tous les projets utilisant plusieurs packages.
UV est l’un des outils contemporains qui permet de contourner le dependency hell
UV permet le management des dépendances dans un environnement virtuel Python isolé
La “recette” de l'environnement UV est stockée dans le fichier
pyproject.toml. Cette “recette” cuisinée figure dans le fichieruv.lock
Maintenant, vous avez installé Poetry et que vous avez activé votre environnement, retrouvez-moi dans le chapitre suivant pour étudier les usages avancés de cet outil.
