Découvrez la plateforme d’orchestration Kestra
Qu’est-ce que la programmation déclarative ?
L’approche déclarative est l’un des principes majeurs des dernières années dans le domaine de la data et de l’informatique de façon plus globale : les frameworks les plus utilisés, comme React, Terraform ou encore Kubernetes, utilisent tous une syntaxe déclarative pour faciliter la vie des développeurs.
Dans l'approche déclarative, vous partez du résultat souhaité et vous décrivez la structure et les étapes du workflow sans vous soucier des détails d'implémentation. Kestra utilise ce même principe pour permettre à l’utilisateur de décrire simplement son plan d’orchestration.
Ça semble intéressant. Mais comment est-ce que ça fonctionne, en pratique ?
La sémantique de Kestra s’articule autour d’un format YAML, qui réduit significativement la barrière à l’entrée – aussi bien pour débutants que pour les ingénieurs expérimentés. Vous pouvez intégrer de nouveaux membres d’équipes et maintenir une collection de flux avec un effort minimal.
Utilisez le langage de votre choix
Utiliser un langage adapté est l’un des problèmes majeurs quand on travaille dans la data. Je ne parle pas uniquement de langage de programmation : il existe plusieurs niveaux de langages entre les humains qui gèrent un projet, du cas d’usage (niveau métier) jusqu’à l’infrastructure informatique (niveau technique) en passant par la logique d’orchestration.
Le data engineering se retrouve souvent entre deux niveaux : la logique métier et la logique d’orchestration. Voici une illustration pour mieux comprendre :
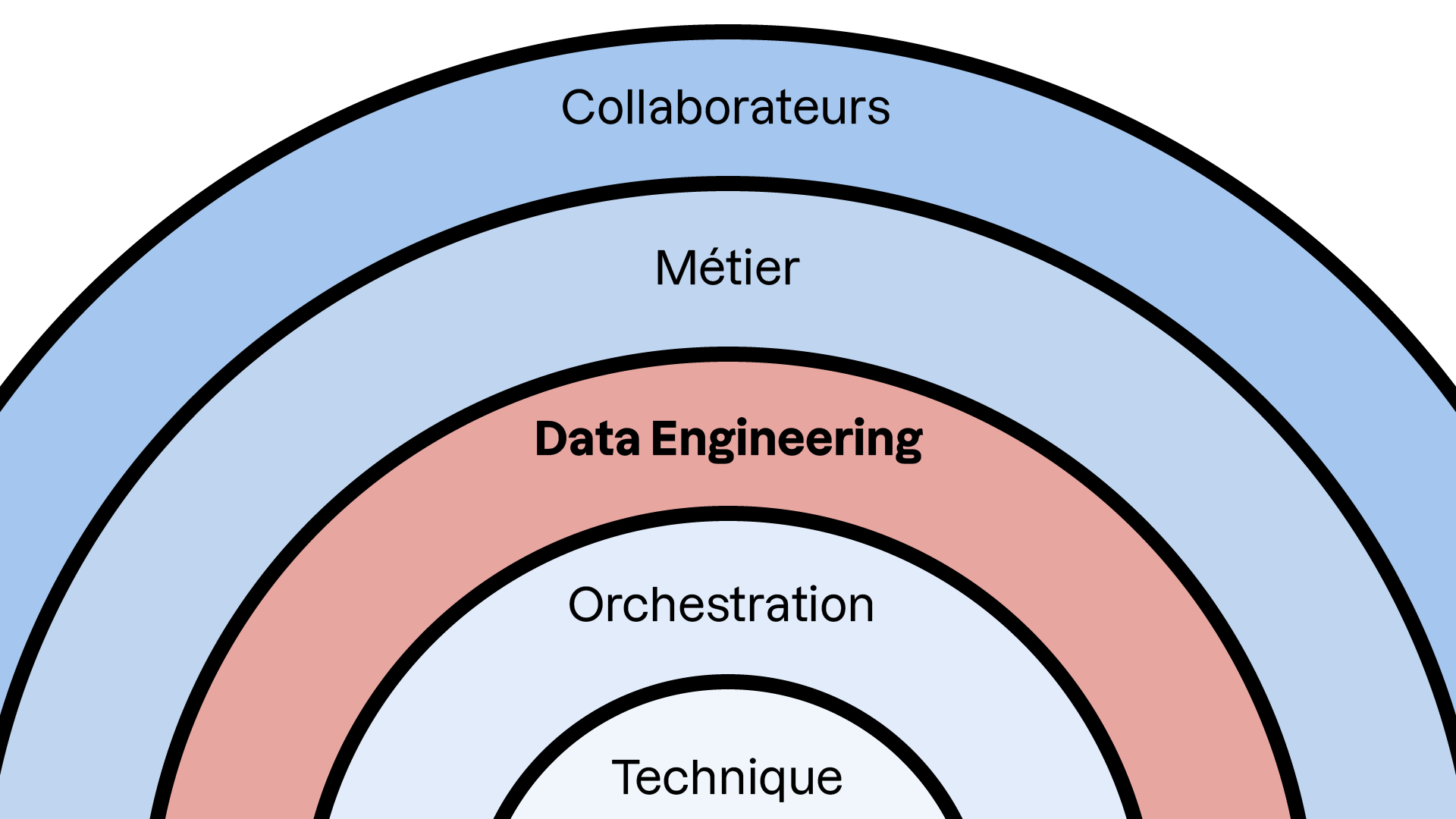
La logique métier consiste en des règles et processus qui décrivent les opérations au sein de l’entreprise. Cette logique est souvent proie à des changements récurrents. La complexité inhérente à la logique métier nécessite très fréquemment l’usage de langages de programmation.
De son côté, la logique d’orchestration ne consiste qu’en la coordination et la gestion de simples tâches : faire des branches selon des conditions, exécuter des tâches en parallèle, etc. L’enjeu principal ici est de maintenir le contexte entre plusieurs exécutions et tâches.
La logique d’orchestration ne nécessitant pas une complexité sémantique majeure, l’utilisation d’un langage déclaratif et du YAML permet de simplifier complètement cette logique.
De plus, Kestra permet d’utiliser n’importe quel langage de programmation (Python, SQL, Javascript, Shell, etc.) pour manipuler les artéfacts qui transitent dans un flux. Ainsi, il est facile d’orchestrer de la logique métier avec Kestra.
Je ne suis pas sûr de comprendre. Est-ce que vous pouvez donner un exemple ?
Oui, pas de soucis ! Par exemple, vous pouvez très bien utiliser Python pour ingérer et normaliser des données venant de sources externes et manipuler et transformer ces mêmes données avec des requêtes SQL. Kestra ici fait office de chef d’orchestre, vous permettant de mieux ordonner ces tâches et gérer les cas d’erreurs, les notifications, les exécutions en parallèle, les déclencher automatiquement, etc.
Découvrez l’interface Graphique
L’un des avantages principaux de Kestra est son interface graphique qui permet de créer, d’exécuter et de monitorer vos pipelines d’orchestration. La page d’accueil – avec son dashboard principal – vous donne une vue complète des dernières exécutions et de la santé globale du plan de production. À travers celui-ci, vous pouvez facilement trouver les exécutions à reprendre et connaître la charge de travail au quotidien.
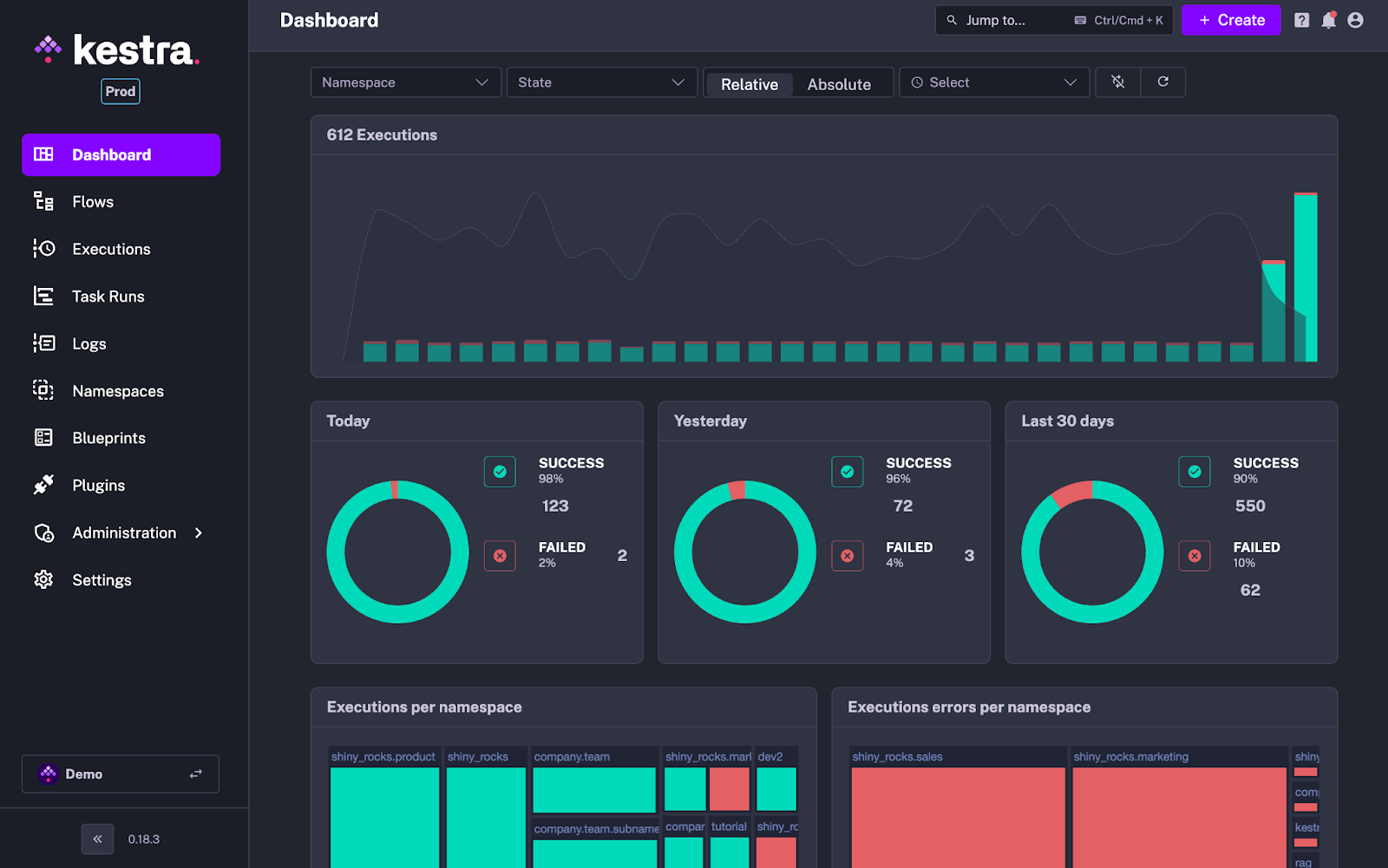
Différents onglets sont accessibles via la barre à gauche, notamment :
Flows :
Cette partie permet d’afficher tous les flux créés au sein de Kestra. Vous pouvez aisément filtrer ces flux selon plusieurs dimensions (nom du flux, namespaces ou via des labels).
Executions :
Cette page liste toutes les exécutions de flux ayant déjà eu lieu. Ici, vous pouvez filtrer les exécutions par état (SUCCESS, FAILURE, etc.), par namespace, ou via une dimension temporelle (lister les exécutions des 15 dernières minutes par exemple).
Logs :
Cet onglet permet un accès précis à tous les logs venant des exécutions.
Namespaces :
L’onglet Namespaces permet de lister tous les Namespaces. Nous verrons plus loin dans le cours leur place dans l’écosystème Kestra.
Blueprints :
Les blueprints consistent à un catalogue organisé et consultable d'exemples de flux. Ils sont prêts à l'emploi et conçus pour vous aider à démarrer votre workflow. Chaque blueprint combine du code et de la documentation, de plus ils sont validés et documentés. Vous pouvez facilement les personnaliser et les intégrer à vos flux en un seul clic avec le bouton "Use". Les blueprints sont très pratiques pour débuter dans Kestra. N’hésite pas à les essayer !
Plugins :
Les plugins sont la base des tasks et des triggers de Kestra. Leurs composants interagissant avec des systèmes externes et effectuant le traitement de données dans vos flux. Kestra est livré avec des centaines de plugins pré-intégrés, et vous pouvez également développer vos propres plugins personnalisés.
Installez Kestra
Il est temps d’installer Kestra – regardons ça ensemble :
C'est maintenant à votre tour !
En résumé
Kestra est une plateforme. Elle donne tous les éléments clés pour orchestrer des flux complexes, de façon robuste et résiliente.
Kestra s’adresse à un large éventail de profils : data engineer, analyste, ML (machine learning) engineer, platform engineer, dévélopeur de logiciel, etc.
Kestra permet d’orchestrer des projets data, des projets d’infrastructure et des projets de développement logiciel. Le tout avec une interface graphique complète permettant de créer, exécuter et monitorer des flux.
Kestra utilise une approche déclarative offrant une simplicité et une rapidité dans le développement des projets.
La séparation de la logique métier et d’orchestration est un élément clé dans la vision de Kestra. Il est tout à fait possible d’orchestrer des scripts - écrits dans n’importe quel langage de programmation - et de les interconnecter avec Kestra.
Dans le prochain chapitre, nous allons rentrer dans le détail et explorer les différentes façons d’éditer et de visualiser un flux Kestra.
