Créez des Flows
 Laissez-moi vous présenter Julien. Julien est un jeune data engineer. Il travaille dans une entreprise qui vend des smartphones. Il emploie beaucoup d’outils au quotidien, notamment des bases de données de type Postgres, des data warehouses comme Snowflake, des services cloud hébergés chez AWS. En plus, Julien utilise plusieurs systèmes de messagerie (email, Slack, etc.).
Laissez-moi vous présenter Julien. Julien est un jeune data engineer. Il travaille dans une entreprise qui vend des smartphones. Il emploie beaucoup d’outils au quotidien, notamment des bases de données de type Postgres, des data warehouses comme Snowflake, des services cloud hébergés chez AWS. En plus, Julien utilise plusieurs systèmes de messagerie (email, Slack, etc.).
Sa mission principale est d’automatiser l’extraction et la transformation de données venant de ces différents systèmes.
Le travail de Julien est intégral pour l’entreprise. Ses tâches sont importantes, car elles permettent à l’entreprise de prendre de meilleures décisions ainsi que d’optimiser les différentes parties de leur produit.
Julien s’apprête à automatiser ses tâches avec un Flow. Nous allons suivre ce processus avec lui. Kestra laisse la possibilité de créer des Flows de différentes manières : soit avec une syntaxe déclarative en YAML, soit avec un formulaire dit “low-code” qui permet notamment à des profils moins techniques de créer leur Flow. Regardons ensemble les Flow de plus près.
Qu’est-ce que le Flow ?
Avant de commencer, Julien se renseigne sur les Flows. Un Flow Kestra se définit nécessairement avec les trois propriétés suivantes :
id: l’identifiant du Flow.namespace: Un namespace permet d'organiser vos Flows, un peu comme les dossiers sur un ordinateur.tasks: La partie principale d'un Flow est la liste des Tâches qui seront exécutées les unes après les autres pendant l'exécution du Flow.
Il est possible de créer des Flows avec de mêmes noms dans différents Namespaces. Mais vous ne pouvez pas avoir de Flows avec les mêmes noms dans le même Namespace.
Examinez la syntaxe YAML
Avant d'explorer les propriétés de Kestra, examinons de plus près certains aspects clés, tels que le YAML et la visualisation des Flows. Le YAML est un langage balisé étant facile à lire et à écrire, aussi bien pour des humains que pour des machines. Il offre plusieurs avantages :
Il est facile à apprendre. Une syntaxe simple permet d’intégrer au mieux les ingénieurs dans le processus d’orchestration et de faciliter la collaboration entre les équipes. Vous le verrez dans la suite du cours : en quelques minutes, vous allez pouvoir créer un flux sans connaissance préalable en programmation informatique.
L'intégration native du YAML dans Kestra permet de détecter et de corriger les erreurs de configuration plus tôt dans le cycle de vie, assurant ainsi une plus grande stabilité des workflows en production. Nous le verrons plus tard dans le cours, mais l’interface graphique aide grandement les développeurs à écrire des Flow Kestra de façon très rapide.
Le YAML est une surcouche du JSON, ce qui permet de facilement s’intégrer avec des API REST tout en restant lisible et compréhensible pour un humain.
En décrivant un flow en YAML, il est facile de suivre les changements et de collaborer sur des Pull Requests, et revenir sur des versions antérieures le cas échéant.
À titre d’exemple, voici deux workflow similaires. L’un est écrit avec Airflow, le framework d’orchestration Python le plus connu, l’autre avec la syntaxe YAML Kestra.
Voici le code Airflow :
from airflow import DAG
from airflow import operators.bash_operator import BashOperator
from datetime import datetime, timedelta
default_args = (
# ...
)
dag = DAG('hello_world', default_args=default_args, schedule_interval=timedelta(days=1))
t1 = BashOperator(
task_id='say_hello',
bash_command='echo "Hello World from Airflow!"',
dag=dag,
)Et voici le même workflow écrit dans Kestra :
id: myflow
namespace: company.team
tasks:
- id: hello
type: io.kestra.plugin.core.log.Log
message: Hello World!Julien se remarque de la simplicité de la syntaxe utilisée par Kestra et comment elle est plus explicite.
Il sait que plus il va avancer dans ses projets, plus la taille de son codebase sera importante et plus le projet sera coûteux à maintenir. Il est donc essentiel pour lui de savoir gérer la complexité et la taille de sa codebase.
Découvrez la Topology
Chaque Flow peut être visualisé graphiquement à l’aide de la Topology.
Cette vue offre la possibilité de voir les différents embranchements d’un flow, ainsi que les tâches correspondantes. Elle convient particulièrement pour des profils moins techniques qui voudraient comprendre un Flow sans avoir à rentrer dans les détails.

Éditez un flow en “Low Code”
Bien que les flux Kestra soient composés en YAML, il est possible de créer un Flow directement dans l'interface utilisateur à l'aide d'un formulaire “low code”.
Lorsque vous utilisez cette fonctionnalité, vous pouvez toujours obtenir le code YAML – et vice versa. Cela peut être très pratique, que vous ayez une formation technique ou non.
Quels sont les avantages d’utiliser cette fonctionnalité par rapport au YAML directement ?
En réalité, choisir l’une ou l’autre dépend essentiellement de vos préférences.
Certains développeurs vont préférer utiliser le YAML pour son aspect déclaratif et scalable. D’autres vont préférer passer par l’éditeur “low code” par habitude d’utiliser des interfaces graphiques.
Il n’y a pas de mauvais choix ici, le plus important est que vous soyez à l’aise dans le développement de vos flux.
Par exemple, pour Julien qui a plutôt l’habitude d’écrire du code, il sera plus naturel d’écrire les Flow Kestra directement en YAML.
Regardons ensemble comment nous pouvons utiliser l’éditeur “low code” sans perdre l’avantage de l’approche déclarative avec du code :
Utilisez les Namespaces
Comme vous l’avez vu, les Namespaces vous permettent d’organiser vos flows, un peu comme des dossiers. À l'aide du symbole point “.”, vous pouvez ajouter une structure hiérarchique à vos namespaces, ce qui vous permet de séparer logiquement les environnements, les projets, les équipes ou les services.
De cette façon, toutes les équipes peuvent utiliser la même instance Kestra, tout en gardant leurs flux organisés et séparés. Différentes parties prenantes peuvent avoir leurs propres namespaces enfants qui appartiennent à un namespaces parent en les regroupant par environnement, projet ou équipe.
Un namespaces peut être construit à partir de caractères alphanumériques. La profondeur de la hiérarchie des namespaces est illimitée. Voici quelques exemples de namespaces :
project_onecompany.project_twocompany.team.project_three
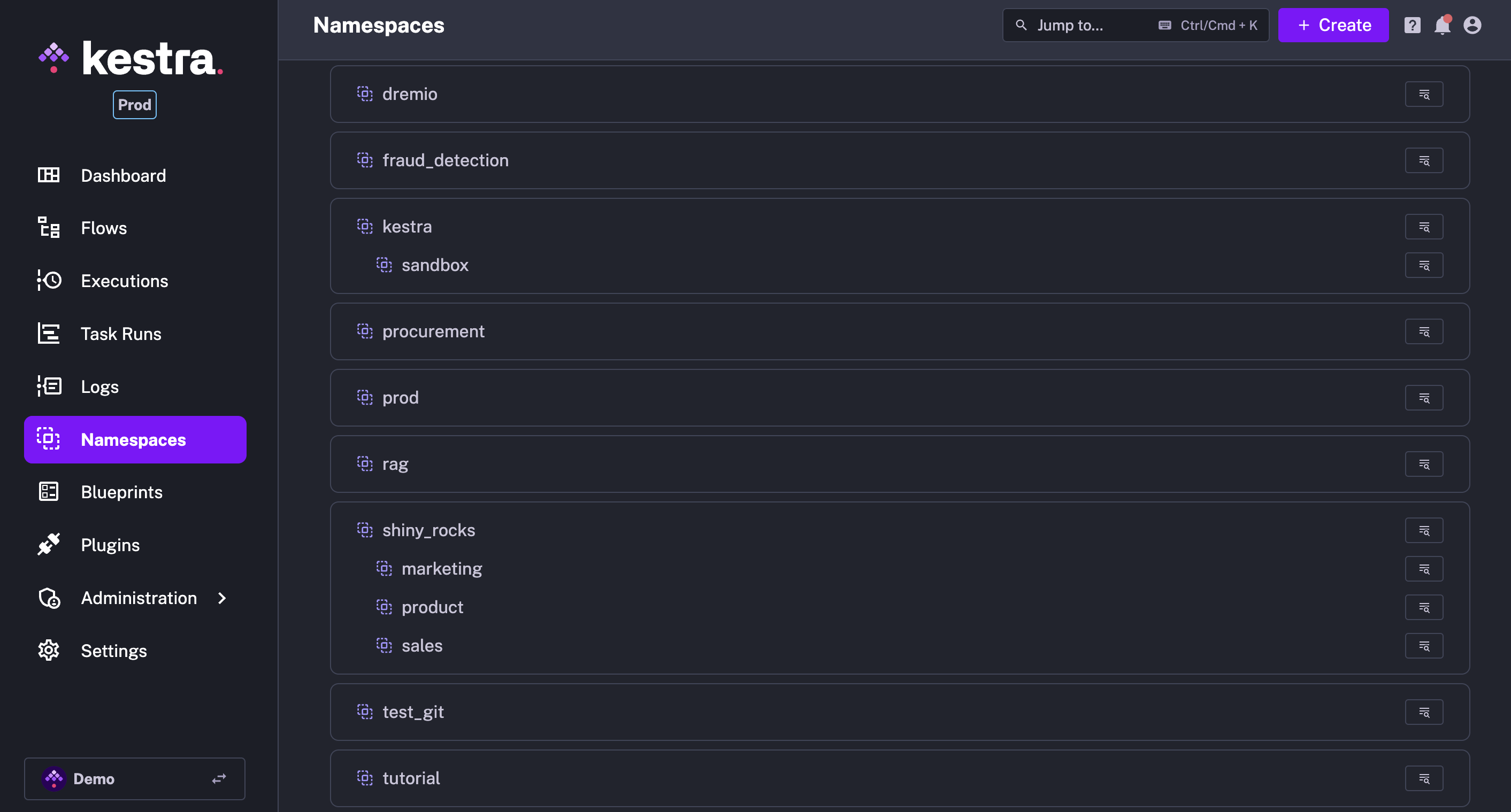
Les Namespaces sont encore plus puissants dans l'édition Enterprise de Kestra :
Role Base Access Control : vous pouvez associer certains utilisateurs à des Namespaces spécifiques et contrôler leurs niveaux d'accès grâce à une configuration granulaire des rôles.
Variables, secrets, propriétés par défaut : vous pouvez déclarer des ressources spécifiques telles que des variables, des secrets ou des valeurs par défaut au niveau des Namespaces, facilitant ainsi la gouvernance de vos projets.
En résumé
Un flow Kestra est défini par un identifiant, un namespaces et des tâches.
Un flow Kestra peut être créé de deux façons différentes : via du code YAML ou avec une interface “low-code”.
Un flow Kestra peut être visualisé graphiquement avec la vue Topology.
Les namespaces permettent d’organiser les flows Kestra pour refléter vos projets ou votre organisation.
Dans le chapitre suivant, nous allons explorer le cœur des flows : les tasks.
