Estimez vos User Stories avec la méthode T-shirt
Imaginez que votre patron vous demande : "Combien de temps pour développer cette app ?" et que vous répondiez : "Aucune idée !" Pas très professionnel...
Mais d'un autre côté, donner un chiffre précis comme "47 heures et 23 minutes" est tout aussi ridicule car le développement est plein d'incertitudes.
C’est bien là tout le dilemme des estimations traditionnelles. Elles semblent rassurantes au départ, mais la réalité finit presque toujours par les démentir.
Prenons un exemple concret : Pour la fonctionnalité de connexion utilisateur, vous estimez 4 heures. En pratique, il vous faudra 12 heures.
Pourquoi ? Un bug imprévu dans l’intégration OAuth, un problème de compatibilité mobile, une demande de modification de dernière minute du client, ou encore du temps de recherche sous-estimé.Résultat : frustration, retards, perte de crédibilité.
Prendre en compte l’ensemble du cycle de vie du ticket
Une erreur fréquente est de n’estimer que le temps de développement pur. En réalité, l’estimation doit couvrir tout le flux de vie du ticket, de sa mise en "TO DO" jusqu'à sa mise en production.
Cela inclut non seulement le développement, mais aussi les tests, la validation, les corrections éventuelles et la mise en production.
Par exemple, il est beaucoup plus simple de tester un ticket consistant à ajouter un lien sur une page qu’un ticket qui envoie un email automatiquement à 4h du matin : la complexité des tests doit être intégrée à l’estimation globale.
Ainsi, une bonne estimation reflète la charge réelle de travail pour livrer la fonctionnalité complète, et pas seulement le codage.
Objectifs d’une estimation
L’estimation n’est pas une boule de cristal, ni une promesse. Son but est de fournir un cadre pour :
planifier les Sprints de manière réaliste,
prioriser les fonctionnalités selon leur coût/bénéfice,
communiquer avec les clients sur la faisabilité,
détecter les tâches trop complexes à découper.
C’est pourquoi il est recommandé d’adopter une approche pragmatique comme la méthode des T-shirts, qui permet d’estimer sans tomber dans le piège de la fausse précision.
La méthode T-shirt : estimer par comparaison relative
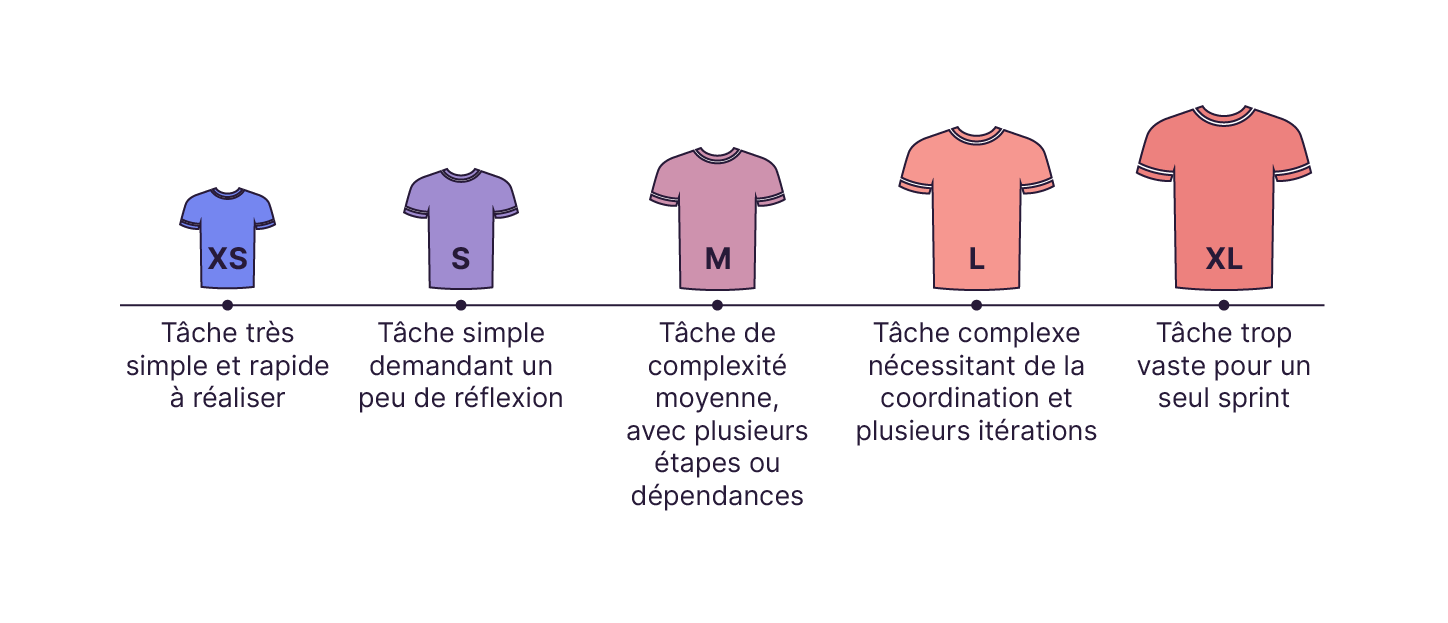
Voici un tableau qui compare les estimations de tâches en développement classique et low-code/no-code.
Taille | Développement classique | Développement Low-Code / No-Code |
XS (Extra Small) | Modifications cosmétiques ultra-simples :
| Modifications cosmétiques ultra-simples :
|
S (Small) | Fonctionnalités simples et bien délimitées :
| Fonctionnalités simples :
|
M (Medium) | Fonctionnalités complètes avec logique métier :
| Fonctionnalités plus avancées :
|
L (Large) | Fonctionnalités complexes impliquant plusieurs systèmes :
| Fonctionnalités complexes mais souvent pré-packagées :
|
XL (Extra Large) | Tâche trop grosse pour être gérée d'un bloc, il faut diviser : Exemple : système de recommandations personnalisées basé sur l'IA | Même principe : on découpe en micro-tâches, souvent facilité par l’outil : |
L’estimation peut se faire en équipe, et il est possible de réajuster les tailles T-shirt avant le Sprint si de nouveaux éléments sont découverts.
La méthode T-shirt est très pratique pour comparer les User Stories entre elles et obtenir une vision globale de l’effort à fournir lors de l’élaboration du Product Backlog. Nous verrons dans la Partie 3 comment affiner ces estimations à l’aide des Story Points et planifier plus précisément le travail des Sprints.
À vous de jouer
Contexte
Vous continuez à développer votre application de streaming musical. Vous avez votre User Story : “Il faut qu’on puisse écouter de la musique quand on a pas internet."
Consigne
Attribuez-lui une taille T-shirt (XS, S, M, L ou XL) et justifiez votre choix.
Livrable
En résumé
L'estimation par comparaison relative (méthode T-shirt) est plus fiable que les estimations en temps absolu car elle s’appuie sur la comparaison de la complexité des tâches plutôt que sur des durées précises, ce qui réduit les biais et s’ajuste mieux à la réalité de l’équipe.
Les 5 tailles sont XS, S, M, L et XL..
La méthode T-shirt permet de comparer les User Stories entre elles et de détecter les tâches trop complexes.
Estimer c'est bien, mais par quoi commencer quand on a des dizaines de fonctionnalités possibles ?
