Optimisez la performance de Spark
Travailler avec Spark, c’est comme piloter une fusée : il faut savoir comment la faire décoller à toute vitesse sans gaspiller de carburant ! 🚀 Pour tirer le meilleur parti de Spark, vous devez optimiser ses performances. En comprenant comment analyser vos tâches et identifier les goulots d’étranglement, vous pourrez accélérer vos traitements, économiser des ressources et rendre votre code encore plus efficace ! 💯
Mais ça veut dire quoi "optimiser Spark" ?
Optimiser Spark, c’est s’assurer qu’il fonctionne de manière efficace en utilisant au mieux les ressources disponibles. Cela signifie éviter les surcharges en vérifiant la répartition du travail sur les nœuds du cluster et réduire les coûts en évitant l’utilisation inutile de ressources. Vous verrez, avec quelques exemples, ça vous paraîtra évident à vous aussi ! 👍
Analysez l’exécution de votre code avec le profiling
Faire un profiling de votre code (avec ou sans Spark) revient à examiner en détail comment votre code fonctionne pour repérer les points faibles, les tâches qui traînent et les ressources mal utilisées. C’est essentiel pour comprendre ce qui tourne bien et ce qui ralentit votre traitement. Grâce aux outils de profiling, vous allez pouvoir diagnostiquer les problèmes, ajuster vos configurations et ainsi rendre vos applications beaucoup plus performantes !
Spark UI : votre centre de contrôle interactif
Souvenez-vous, dans un screencast précédent, je vous ai montré comment visualiser un DAG à l’aide d’un interface graphique nommé… 🥁 Spark UI ! Avec Spark UI, vous pouvez non seulement voir les DAG associés à votre code mais surtout surveiller vos jobs Spark en temps réel ! Vous pouvez voir tout ce qui se passe dans votre cluster et repérer les ralentissements.
Comment utiliser Spark UI ? 🕵️♂️
Accédez à Spark UI
Si vous avez une session Spark active, vous pouvez accéder à Spark UI avec l’URL suivante : http://localhost:4040. Ouvrez-la dans votre navigateur, et vous voilà dans la tête de Spark ! 🤖
Voici ce que vous verrez:
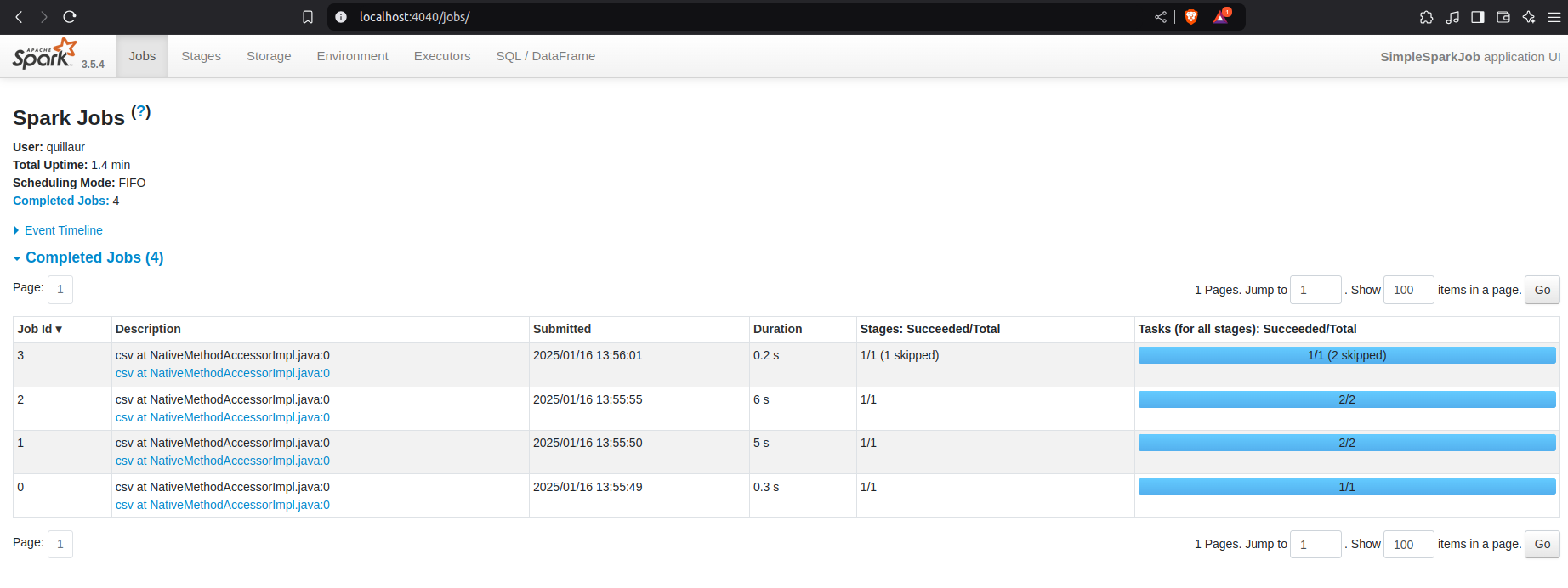
Bien entendu, le contenu de la page dépend de ce que vous avez demandé à Spark d'exécuter.
Petite astuce, pour que votre session Spark reste active après l'exécution d’un script, ajouter les lignes suivantes à ce script:
# Gardez la session Spark active pour explorer l'interface web
input("Appuyez sur Entrée pour arrêter la session Spark...")
# Arrêt de la session Spark
spark.stop()Ainsi, votre session Spark ne se fermera qu’après avoir appuyé sur “Entrée” dans votre terminal.
L’interface est très simple mais efficace. Vous avez un onglet pour chaque aspect de l'exécution du code de votre session Spark. Voyons ensemble à quoi ils servent.
Explorez l’onglet Jobs : Ici, vous voyez tous vos jobs Spark. Vous pouvez repérer ceux qui prennent le plus de temps et comprendre pourquoi en utilisant les autres onglets de l’interface.
Analysez les Stages : Les stages, ce sont les étapes de votre job. Si une étape prend trop de temps, c’est peut-être là que se cache le problème de votre job. Par exemple, si la phase de chargement des données est lente, vous saurez qu’il faut optimiser cette partie.
Examinez SQL / DataFrame : Si vous utilisez des DataFrames ou des requêtes SQL, cet onglet vous montre comment Spark optimise vos requêtes. Vous pouvez voir si Spark fait des opérations coûteuses, comme des scans complets de table, et ajuster votre code en conséquence.
Surveillez Storage : Si vous ne voyez rien dans l'onglet Storage de Spark UI, pas de panique ☺️, c'est probablement parce que vos données ne sont pas stockées (entendez: de façon persistante) en mémoire ou sur disque par Spark lors de l'exécution de vos jobs. En effet, Spark ne stocke les données que si vous le lui demandez explicitement avec les méthodes cache() ou persist(). Si vous n'utilisez pas ces méthodes, Spark ne garde pas les données en mémoire après les avoir traitées.
Dans le cas où vous utilisez ces méthodes, cet onglet vous permet de voir si trop de données sont écrites sur le disque (persist) au lieu d’être stockées en mémoire (cache).
Employez des leviers de pression
Maintenant, on va voir trois façons d'utiliser des leviers de pression.
Optimisez le partitionnement des données
Le partitionnement, c’est un peu comme organiser une grande fête : si vous invitez trop de monde, ça devient le bazar, et si vous n’en invitez pas assez, c’est pas très animé. Avec Spark, c’est pareil ! Si vous avez trop de partitions, le scheduler (le chef d’orchestre) est débordé, et si vous n’en avez pas assez, les calculs ne sont pas assez parallélisés, donc tout va plus lentement.
Comment est-ce que je trouve le bon nombre de partitions ?
Par défaut, Spark choisit un nombre de partitions en fonction de la taille de vos données et de la configuration de votre cluster. Par exemple, si vous chargez un fichier CSV de 1 Go et que votre cluster a 4 cœurs, Spark pourrait créer environ 8 partitions par défaut (cela dépend de la configuration de spark.default.parallelism). Mais ce n’est pas toujours optimal.
Comment savoir si je dois augmenter ou diminuer le nombre de partitions ?
Ici, 2 choses sont à prendre en compte:
Certaines tâches prennent plus de temps sur de petites partitions que sur des grandes et vise-versa. Cela dépend de l’algorithme sous-jacent.
La mémoire disponible dans votre executor. Si il peut tenir 1Go en mémoire, alors commencer par essayer de lui passer des partitions proche de 1Go chacune, mais surtout ne dépassez pas ! 💥
Une fois cela en tête, il vous faudra expérimenter de façon empirique pour trouver le juste équilibre.
Vous vous demandez peut-être comment savoir le nombre de partitions que Spark crée par défaut ?
Vous pouvez vérifier le nombre de partitions d’un RDD de la façon suivante:
df = spark.read.csv("data.csv")
print(df.rdd.getNumPartitions()) # Affiche le nombre de partitions par défautÉvitez les transformations qui coûtent cher !
Avec le temps, vous finirez par commencer à anticiper quelle transformation prendra beaucoup de temps sur telle taille de données. Par exemple, groupByKey() regroupe toutes les valeurs associées à une clé, mais si vous avez beaucoup de valeurs, ça peut vite devenir un cauchemar pour la mémoire. Rappelez-vous la fameuse partie reduce de l’algorithme MapReduce. Il est question ici de comment faire le reduce correctement. Vous pouvez utiliserreduceByKey() , qui combine les valeurs localement (dans chaque executor) avant de les regrouper complètement.
Et du coup… quand est-ce que j’utilise reduceByKey() au lieu de groupByKey() ?
Malheureusement, il n’y a pas de chiffre magique ici. Comme pour le nombre de partitions, il faut juste avoir en tête que ces possibilités existent et que vous pouvez tester les 2. Selon le matériel utilisé et le contenu des partitions, les performances peuvent pas mal varier entre les 2 méthodes.
Caching et Persistance
Allez, un petit dernier pour la route: la notion de persistance des données. Ici, c’est un peu comme mettre vos affaires les plus utilisées bien en évidence sur votre bureau pour ne pas avoir à les chercher à chaque fois. Si vous réutilisez souvent un RDD après avoir fait des transformations complexes, vous pouvez le stocker en mémoire avec cache() (une partie de la mémoire très proche de votre processeur) ou persist() (sur le disque dur).
Quand utiliser le caching ?
Imaginez que vous avez un DataFrame sur lequel vous faites plusieurs opérations : d’abord vous filtrez les données, puis vous les agrégez, et enfin vous les sauvegardez. Si vous ne cachez pas le DataFrame après le filtrage, Spark devra refaire le filtrage à chaque étape. Au lieu de ça, vous pouvez faire :
filtered_df = df.filter(df["age"] > 18).cache() # Cache le DataFrame filtré
# Opération 1 : Agréger les données
agg_df = filtered_df.groupBy("city").count()
# Opération 2 : Sauvegarder les données
filtered_df.write.csv("filtered_data.csv")Donc, si en regardant le DAG, vous voyez que les mêmes transformations sont calculées plusieurs fois, c’est un signe que vous devriez utiliser le caching.
D’un autre côté, si vos données sont trop grosses pour tenir en mémoire RAM, vous pouvez opter pour une stratégie mixte avec persist(StorageLevel.MEMORY_AND_DISK). Cela stockera une partie des données sur le disque dur en attendant qu’il y a de la place en RAM. Vous y perdrez en rapidité, mais c’est mieux que de ne pas pouvoir effectuer le calcul du tout ! 💫
Pas besoin d’en rajouter, vous l’avez compris: optimiser les performances implique d’utiliser le profiling pour faire des tests. Il faut donc connaître les possibilités qui sont entre vos mains et trouver le meilleur équilibre pour faire tourner votre programme. Maintenant, vous savez tout ! ✨
Alors, maintenant, laissez-moi vous reposer la question : imaginez que tous les hôpitaux décident de centraliser toutes les analyses de scans dans un seul datacenter… le vôtre. Que feriez-vous ? J’espère que la réponse vous paraît aussi évidente qu’à moi : "On appelle Spark à la rescousse, bien sûr !" 😉
En résumé
Le profiling consiste à examiner en détail comment votre code fonctionne pour identifier les points faibles, les tâches qui prennent trop de temps et les ressources mal utilisées.
Utilisez le UI pour visualiser les DAG, surveiller les jobs, les stages et les ressources utilisées.
Trouvez le bon nombre de partitions pour équilibrer la charge. Trop de partitions surcharge le scheduler, trop peu limite le parallélisme.
Déterminez quelle transformation est la plus appropriée en fonction de la taille de vos partitions.
Utilisez cache() ou persist() pour stocker en mémoire ou sur disque les données fréquemment réutilisées.
Ce fut un plaisir de partager ces connaissances avec vous. Portez-vous bien, et à bientôt pour de nouvelles aventures technologiques ! 🤗✨
