Initiez-vous au calcul distribué

Imaginez que tous les hôpitaux décident de centraliser toutes les analyses de scans dans un seul data center : le vôtre. Cela représente des milliers de scans médicaux générés chaque jour. Vous pourriez recruter plein de radiologues pour analyser ces images et diagnostiquer des maladies. Mais le volume de données est tellement énorme qu'il devient évident que ce travail est impossible à faire manuellement, notamment vu les exigences de qualité et de rapidité demandées par le domaine médical. C'est ici que le calcul distribué entre en jeu et… vous aussi !
Qu’est-ce que le calcul distribué ?
Pour comprendre comment vous allez pouvoir gérer cette montagne de données, regardons de près la définition du calcul distribué.
Ce concept est particulièrement utile pour traiter le Big Data : ces ensembles de données si volumineux et complexes qu'ils dépassent les capacités des outils de traitement de données traditionnels. Dans notre cas, les scans médicaux représentent un exemple typique de Big Data.
C’est évident me direz-vous… 😁, oui… peut-être, je vous l’accorde… mais que se passe-t-il dans votre ordinateur quand vous divisez un calcul ? Et puis… Comment est-ce qu’on divise un calcul en fait ? Un peu de patience...j'y arrive ! 😉!
Maintenant que j’ai piqué votre curiosité, poursuivons avec un peu de vocabulaire.
Il y a 2 notions importantes pour faire un calcul distribué efficace : le parallélisme et la scalabilité.
Imaginez un texte très long. Comment est-ce que vous comptez les mots à l'intérieur ? Si vous essayez de le faire tout seul, ça va vous prendre beaucoup de temps.
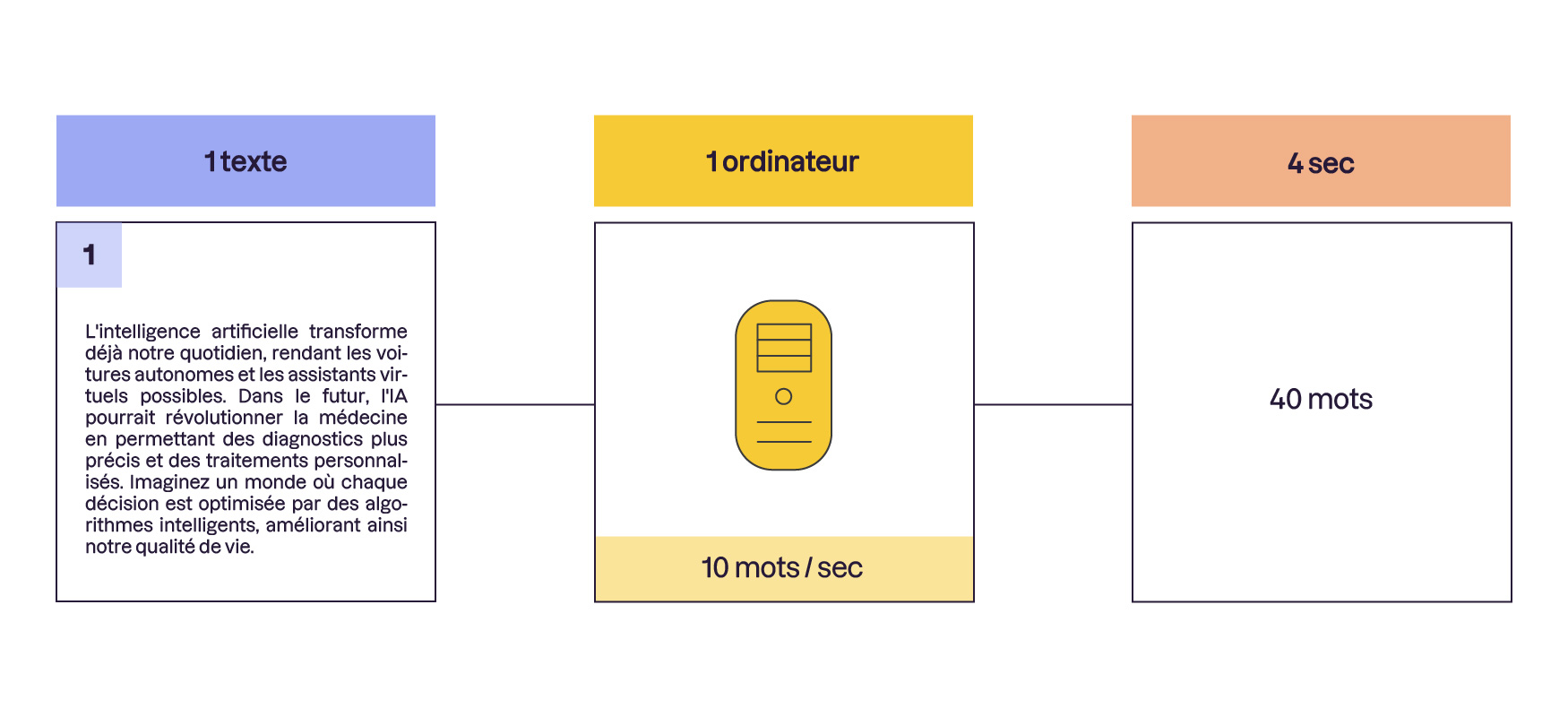
Mais si vous divisez le texte en plusieurs phrases et que vous demandez à vos amis de compter les mots dans chaque phrase en même temps, vous irez beaucoup plus vite. C'est ça, le parallélisme : faire plusieurs tâches simultanément à plusieurs pour aller plus vite.
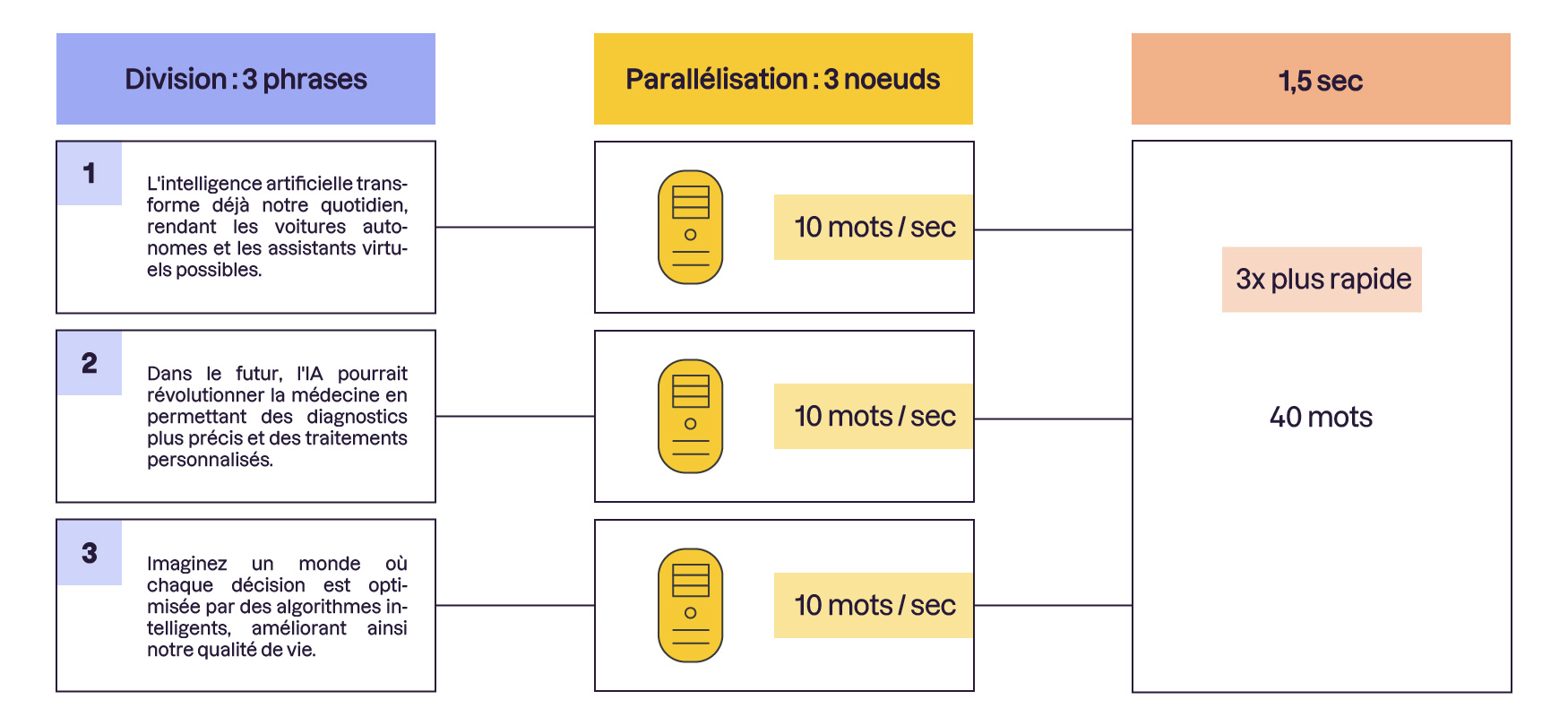
Maintenant, imaginez que votre texte devient de plus en plus long et que vous ayez besoin de plus d'amis pour continuer à compter les mots. La scalabilité, c'est pouvoir ajouter plus d'amis pour que vous puissiez toujours compter les mots sans que l’équipe ne soit surchargée.
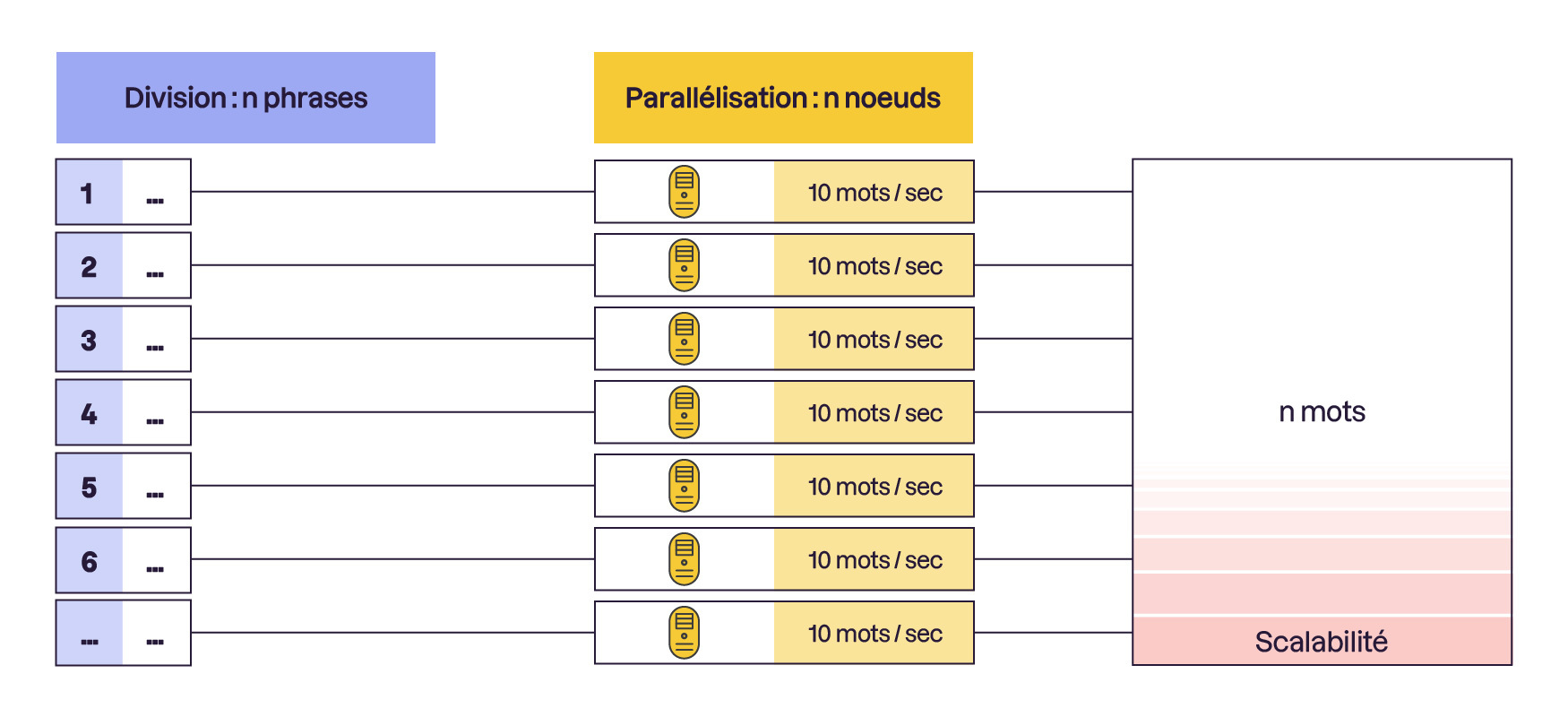
Dans notre histoire de data center, c'est pareil. Les images qui arrivent dans votre data center, c'est comme votre long texte. Le parallélisme, c'est quand plusieurs ordinateurs travaillent ensemble pour analyser les images médicales en même temps. Et la scalabilité, c'est quand on ajoute plus de nœuds pour que le data center puisse toujours traiter plus d'images sans ralentir.
Mais au fait, c’est quoi des nœuds ? 🤔
Ah oui ! Pardon, j’y réponds dans le prochain paragraphe.
Découvrez l’architecture du calcul distribué
Pour mettre en place ce système, vous allez avoir besoin d’une sacrée équipe d'ordinateurs, et le terme équipe n’est pas là par hasard ! En effet, l'architecture de votre data center sera composée de clusters, autrement dit des ensembles de nœuds interconnectés, qui travaillent ensemble et simultanément pour accomplir une tâche.
Je suis perdu…
Pas de panique ! Voici un petit schéma de récap :
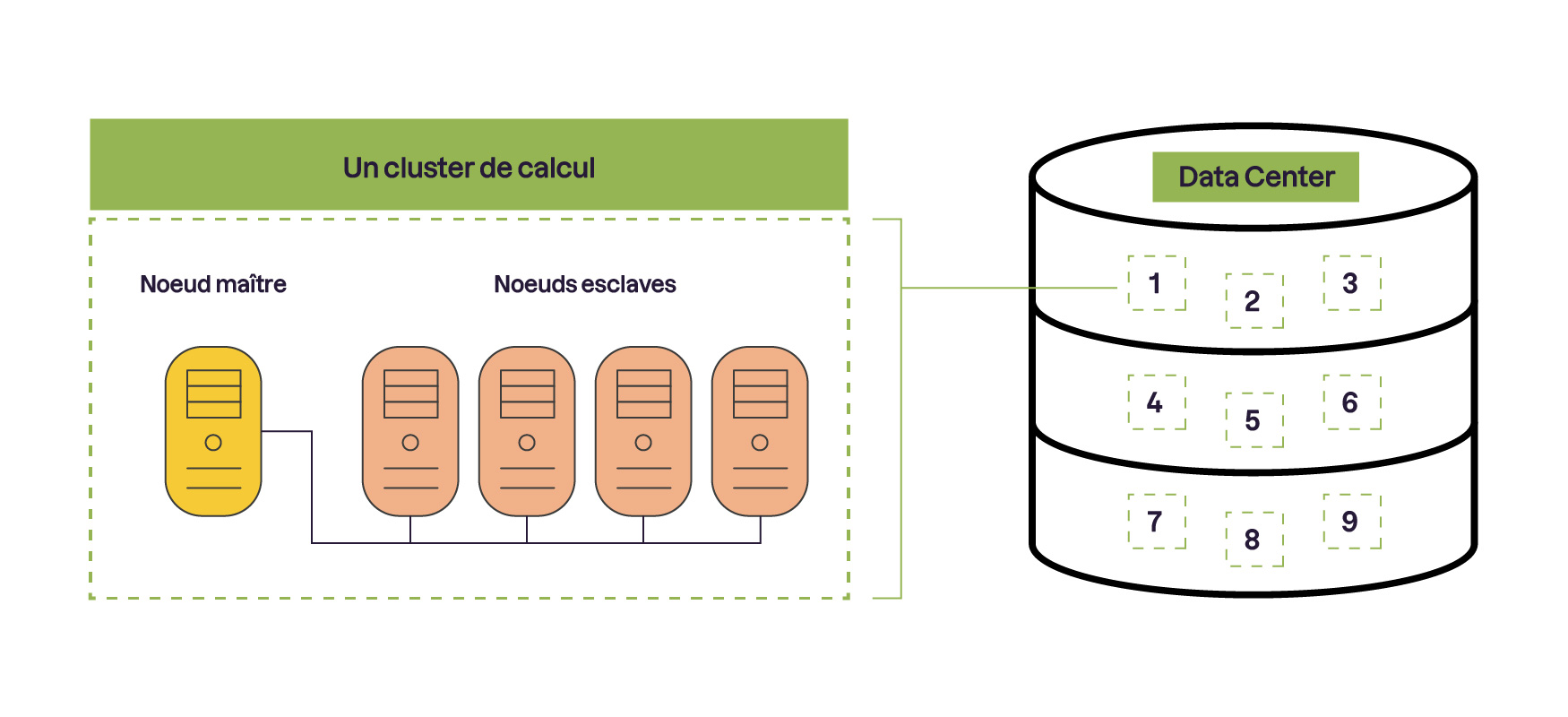
Ça va mieux 🙂 ? Comme vous pouvez le voir : les nœuds sont les unités de base d'un cluster et peuvent être classés en différents types : un nœud maître, qui coordonne et distribue les tâches, et des nœuds esclaves, qui exécutent les tâches assignées par le nœud maître. Le nœud maître décide quelles images doivent être analysées par quels ordinateurs, en fonction de leurs capacités et de la complexité des tâches. Par exemple, une radiographie à haute résolution sera envoyée à un nœud possédant plus de capacité et inversement pour une basse résolution.
Comprenez le calcul distribué avec MapReduce
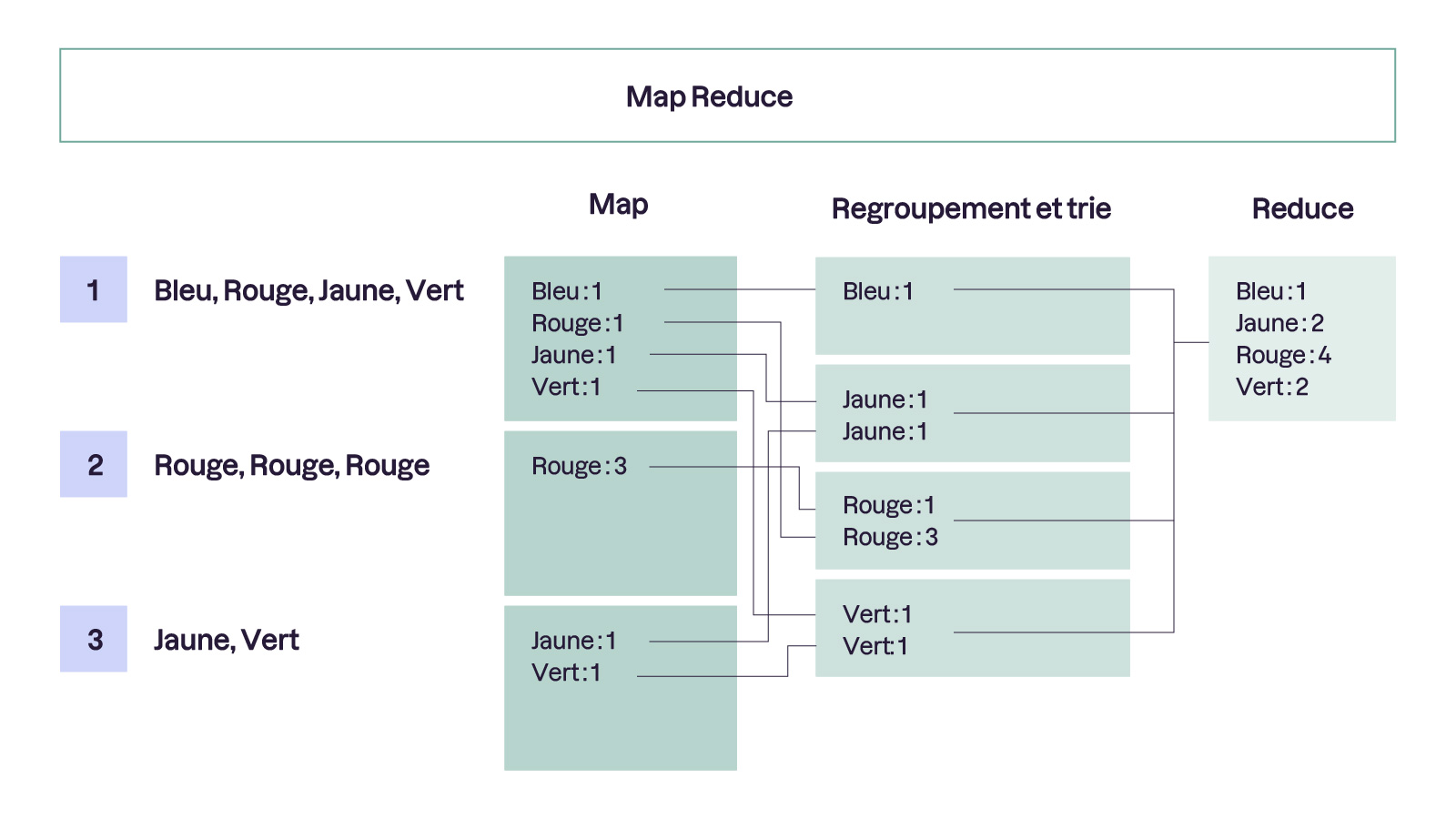
Arrêtons-nous un peu pour être sûr de bien comprendre et prenons l'exemple d'un algorithme de distribution très connu appelé MapReduce. MapReduce est conçu pour le traitement de grandes quantités de données. Il se compose de deux phases principales : la phase Map et la phase Reduce.
Pour illustrer cela, reprenons un exemple que vous connaissez bien : le comptage du nombre de mots dans un texte. Allez, ne soyons pas fainéants et complexifions un peu les choses 🤔 : cette fois, je veux connaître le nombre d'occurrence de chaque mot dans le texte. Même pas peur ? Bien, ça aurait été dommage de s’arrêter en si bon chemin quand même ! 🤓
Dans la phase Map, le texte est divisé en plusieurs phrases, et chaque phrase est envoyée à un nœud différent.
Mais alors, comment suivre les résultats obtenus pour chaque nœud ?
C’est là qu’intervient le système de paires clé-valeur. Chaque nœud traite une phrase et produit des paires : la clé est un mot et la valeur est le nombre d'occurrences de ce mot dans la phrase. Sachant cela, vous devrez donc toujours pouvoir associer un concept ou un label (la clé) à un résultat (ou une valeur) lorsque vous souhaitez utiliser cet algorithme de calcul distribué.
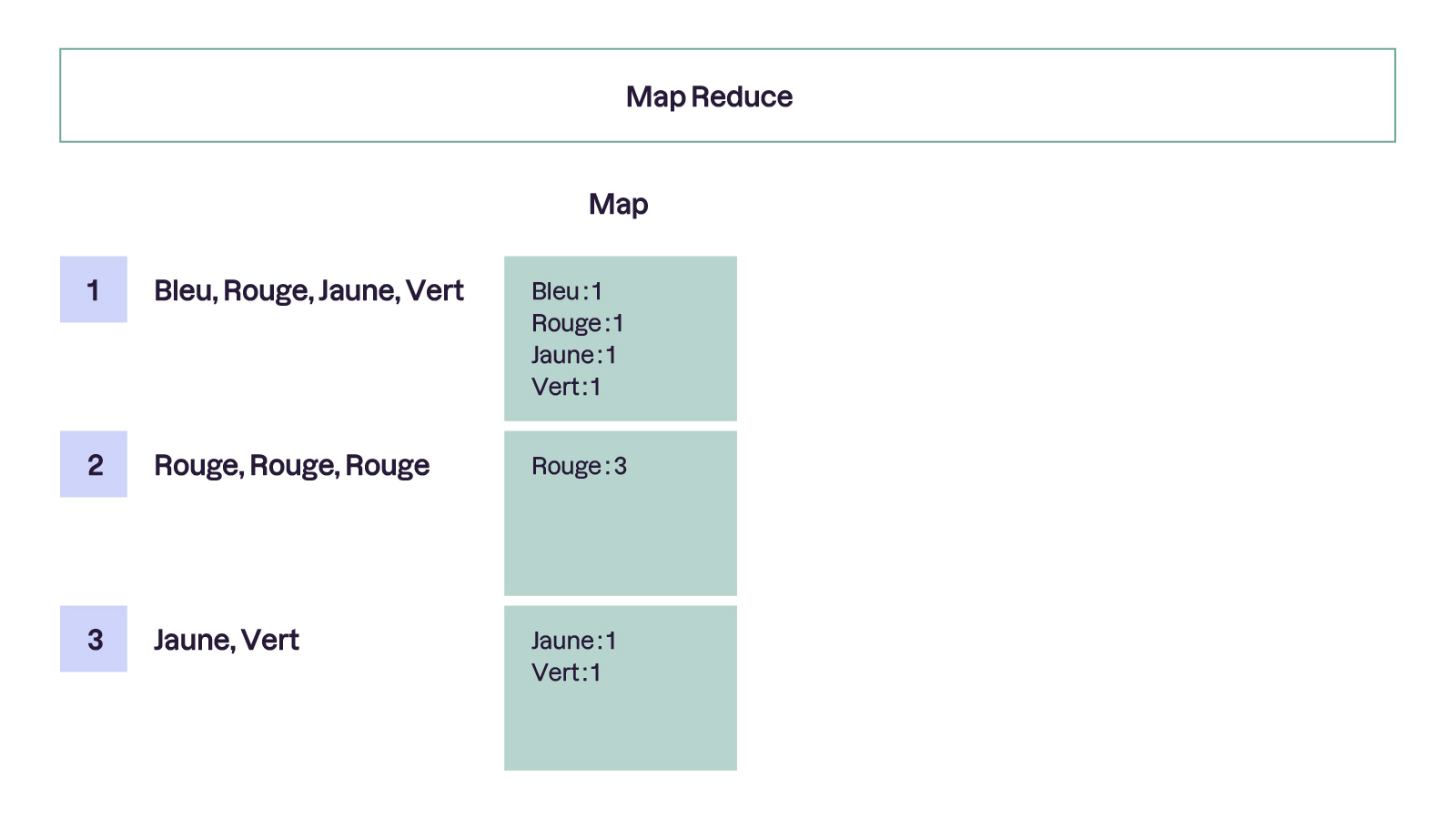
Ainsi, si le mot "Rouge" apparaît 1 fois dans une phrase et 3 fois dans une autre, la phase Reduce combinera ces résultats pour indiquer que "Rouge" apparaît 4 fois dans l'ensemble du texte.
Distinguez calcul parallèle et calcul distribué
Lors d'un calcul réalisé en parallèle, différents threads d'exécutions (et non des nœuds) sont exécutés en même temps et partagent une mémoire commune qui leur permette de se synchroniser entre eux.
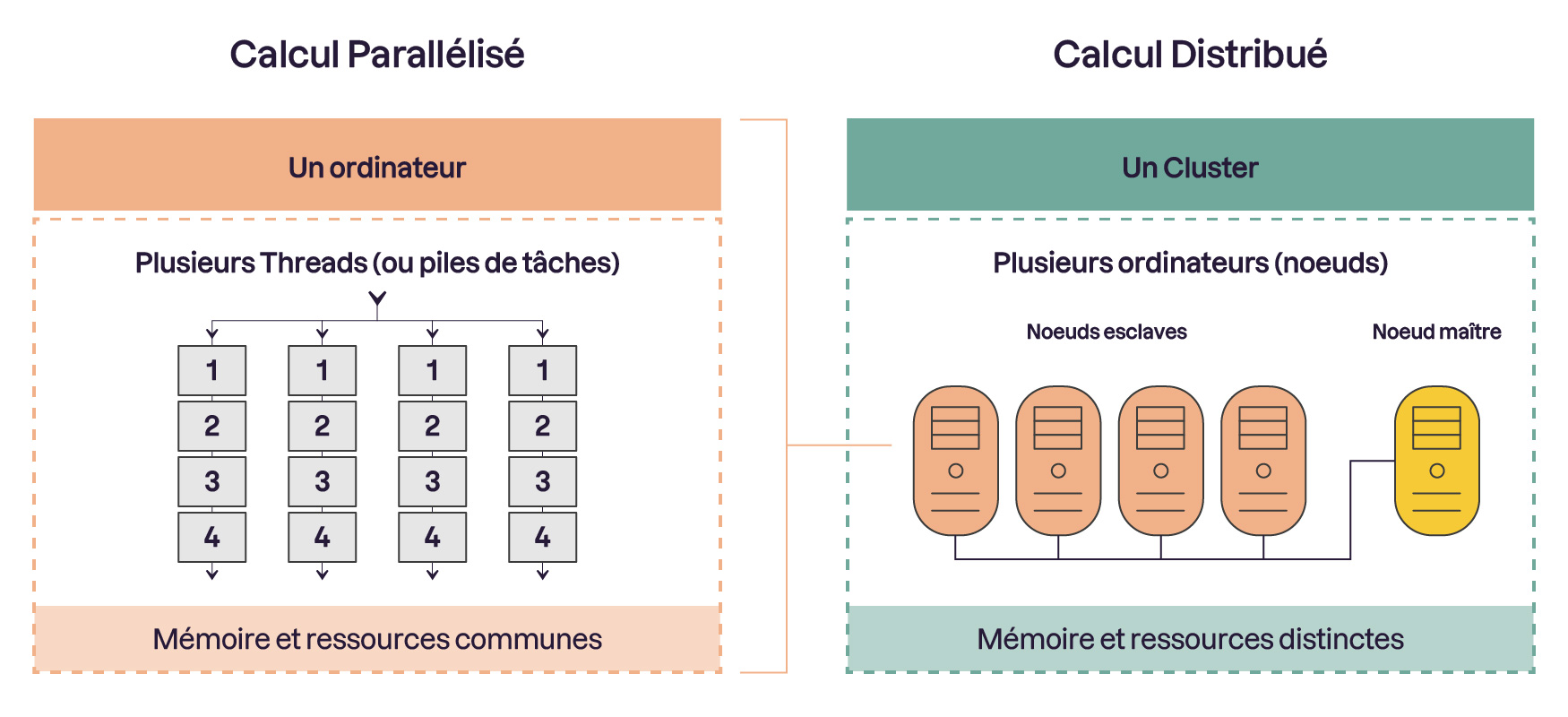
Dans ce cours, nous nous concentrons donc sur le calcul distribué tout simplement car ce procédé n’a pas de limite pour la résolution de problématiques liées au Big Data (si ce n’est votre compte en banque… 😅). En effet, le passage à l'échelle sur un système de calcul distribué s'effectue de manière horizontale c'est-à-dire qu'il suffit d'ajouter des nœuds au cluster pour augmenter sa capacité de calcul. Il permet donc d’envisager des architectures infiniment extensibles.
Tout ne devient donc qu’une histoire de ressources disponibles et de communication. Et oui, même en informatique, ce célèbre dicton trouve tout son sens : "Seul, on va vite, mais ensemble, on va loin." 🤩
Parlons des ressources
Avant de passer à la pratique, plongeons un moment dans le cœur battant du calcul distribué : la gestion des ressources. C'est ici que les choses deviennent certes plus complexes, mais tout autant impressionnantes !
La gestion des ressources est l’élément crucial pour assurer l'efficacité du système.
Ne vous inquiétez pas, je vois bien la question qui vous pend aux lèvres :
Mais c’est quoi une ressource en informatique ?
Pour ce qui est du calcul distribué, cela inclut l'allocation des tâches, la gestion de la mémoire et la surveillance des performances. Le tout étant de garantir que chaque nœud fonctionne de manière optimale et que les ressources sont utilisées de manière efficace.
Comme dit précédemment :
Le nœud maître décide quelles images doivent être analysées par quels ordinateurs, en fonction de leurs capacités et de la complexité des tâches.
Cela implique que le nœud maître connaît à tout moment la capacité de chaque nœud à prendre une tâche en charge. Il doit donc y avoir un système qui gère la mémoire à l’échelle du cluster et présent au niveau du nœud maître.
Et bien de même, si un ordinateur manque de mémoire, il peut ralentir ou même échouer à analyser l'image envoyée, ce qui retarde tout le processus. Le nœud maître doit donc surveiller constamment la mémoire disponible et ajuster les allocations en conséquence.
Et puis, il y a la surveillance des performances. Prenez le cas d’un superviseur qui observe attentivement le travail de chacun de ses ouvriers : si l’un des ouvriers ralentit, le superviseur, souhaitant faire preuve de compassion, prend la charge de travail de l’ouvrier et l’affecte aux autres ouvriers en fonction de leurs capacités.
C’est exactement pareil si un nœud ralentit en termes de temps d'exécution de sa tâche. Le système détecte le problème et redistribue certaines de ses tâches à d'autres ordinateurs moins sollicités. C'est bel et bien un travail d'équipe où chaque membre doit être prêt à aider les autres !
Si vous ne vous voyez pas gérer tout ça, car vous ne sortez pas d’école d’informatique ou que vous n’aimez pas le travail en équipe 😉, eh bien soyez rassurés, vous n’y toucherez pas ! En effet, et heureusement, tout cela sera géré par votre fournisseur de service cloud ainsi que par le framework que j’ai vous avez choisi... Spark ! Avec Spark, vous pouvez vous concentrer sur l'analyse des données et laisser la gestion des ressources du cluster aux experts.
Quel est l’intérêt de nous avoir présenté autant de détails ?
Tout simplement parce que pour pouvoir apprécier pleinement la technologie que vous manipulez ainsi que les tenants et les aboutissants de votre projet, il faut en comprendre les mécanismes clés sous-jacents. Ça évite beaucoup de grosses bêtises… croyez en mon expérience !
En résumé
Le calcul distribué est une méthode de résolution de problèmes complexes en divisant le travail entre plusieurs ordinateurs ou nœuds. Chaque nœud traite une partie des données, et les résultats sont ensuite combinés pour obtenir la solution finale.
Le parallélisme permet de faire plusieurs tâches simultanément pour aller plus vite, tandis que la scalabilité permet d'ajouter plus de ressources pour gérer des volumes de données croissants sans surcharge.
L'architecture du data center repose sur des clusters de nœuds interconnectés, où les nœuds maîtres coordonnent et distribuent les tâches, tandis que les nœuds esclaves les exécutent.
MapReduce est un modèle de programmation pour le traitement de grandes quantités de données, où la phase Map divise les données en morceaux traités par différents nœuds pour générer des paires clé-valeur, et la phase Reduce agrège ces résultats intermédiaires pour produire la solution finale.
La gestion des ressources couvre l’allocation des tâches, la gestion de la mémoire et la surveillance des performances, avec le nœud maître redistribuant les tâches en cas de surcharge, de baisse de performance ou de panne d’un nœud.
Maintenant que vous êtes des experts du calcul distribué, voyons un peu ce qu’est ce fameux framework : Spark.
