Conteneurisez votre projet ML avec Docker
Parler de ML Engineering et de déploiement d’un modèle, sans aborder de Docker serait un non-sens total. C’est l’outil omniprésent par excellence dans n’importe quel processus de déploiement d’un modèle de ML, voire d’un programme informatique en général.
À la fin de ce chapitre, nous aurons parcouru ensemble étape par étape un exemple de conteneurisation (ou plus communément “Dockerisation”) d’un projet ML. Allons-y !
Comprenez la big picture
Avant de mettre les mains dans le code, il est essentiel de commencer par prendre du recul et comprendre la place de la conteneurisation dans un projet ML plus large.
Dockeriser un projet passe par deux étapes, l’étape de build et l’étape de run. Les noms de ses étapes vous donnent déjà une idée de ce qui se passe, mais soyons explicites :
Le build va venir justement encapsuler votre projet (code, modèle, packages, variables d’environnement, tout le nécessaire) dans une image, isolée du reste des autres processus qui tournent dans votre PC
L’étape run consiste à lancer l’image au sein du conteneur, ce de la même manière qu’on lance un environnement virtuel en Python. À ce stade il s’agit plus d’une vérification que votre build a bien fonctionné. Si votre code fonctionnait correctement dans votre PC avant sa conteneurisation, mais pas après, cela est un indicateur fort que votre conteneur ne contient pas tout ce qu’il faut pour fonctionner dans un autre PC que le vôtre, ou autrement dit, en production.
L’image docker devient alors un "package" autonome qui peut s'exécuter de manière identique sur n'importe quelle infrastructure supportant Docker.
Parfois tu me parles d’images, d’autres fois de conteneurs… Ce sont des synonymes ?
Pas vraiment et c’est un point important à comprendre ! Pour faire simple :
une image contient tous les ingrédients (code, packages, variables d’environnement) pour que le projet dockerisé se lance.
un conteneur est justement le fruit du lancement de l’image. Quand on fait docker run, on prend une image et elle se “transforme” en conteneur qui va exécuter le projet construit avec docker build. Dans le jargon, on dit que l’image est instanciée en tant que conteneur.
Par abus de langage, les professionnels de la Data utilisent des fois le terme image et container de manière interchangeable.
Ok, maintenant que j’ai dockerisé mon projet, comment je le partage avec les autres ? Je dois le pousser dans Git comme le reste de mon code ?
Alors, on va en effet pousser l’image quelque part, mais pas dans Git ! En général, nous poussons notre image dans ce que l’on appelle un Container Registry, un lieu de stockage spécialisé pour les images Docker. Les Container Registry ont un point commun avec Git, ils versionnent toutes les images Docker qui y sont poussées et leur attribuent un tag unique, afin de garantir la reproductibilité de vos résultats.
Pour rappel, Git n’est pas fait pour stocker autre chose que du code, y compris des fichiers très lourds. Or, les images Docker dans un projet ML peuvent facilement peser plusieurs Go.
Maintenant qu’on a digéré tout ce vocabulaire préliminaire, on peut enfin comprendre techniquement ce que signifie déployer notre projet : Il s’agit de lancer un docker run de notre image buildé au préalable dans un ordinateur à distance, accessible par API (je te regarde FastAPI) ou via un site web ( je te regarde aussi Streamlit).
On appelle souvent cet “ordinateur à distance” un compute instance ou compute ressource. C’est parce qu’il s’agit d’une machine que l’on active spécifiquement pour lancer les calculs d’un projet. Très régulièrement, la compute instance prend la forme :
D’une machine virtuelle avec des ressources dédiées (RAM, CPU, GPU, stockage etc.)
D’une machine virtuelle avec des ressources partagées avec d’autres machines. On parle dans ce cas-là de cluster.
Dans un contexte Microsoft Azure, tout cela ressemblerait à la chose suivante :
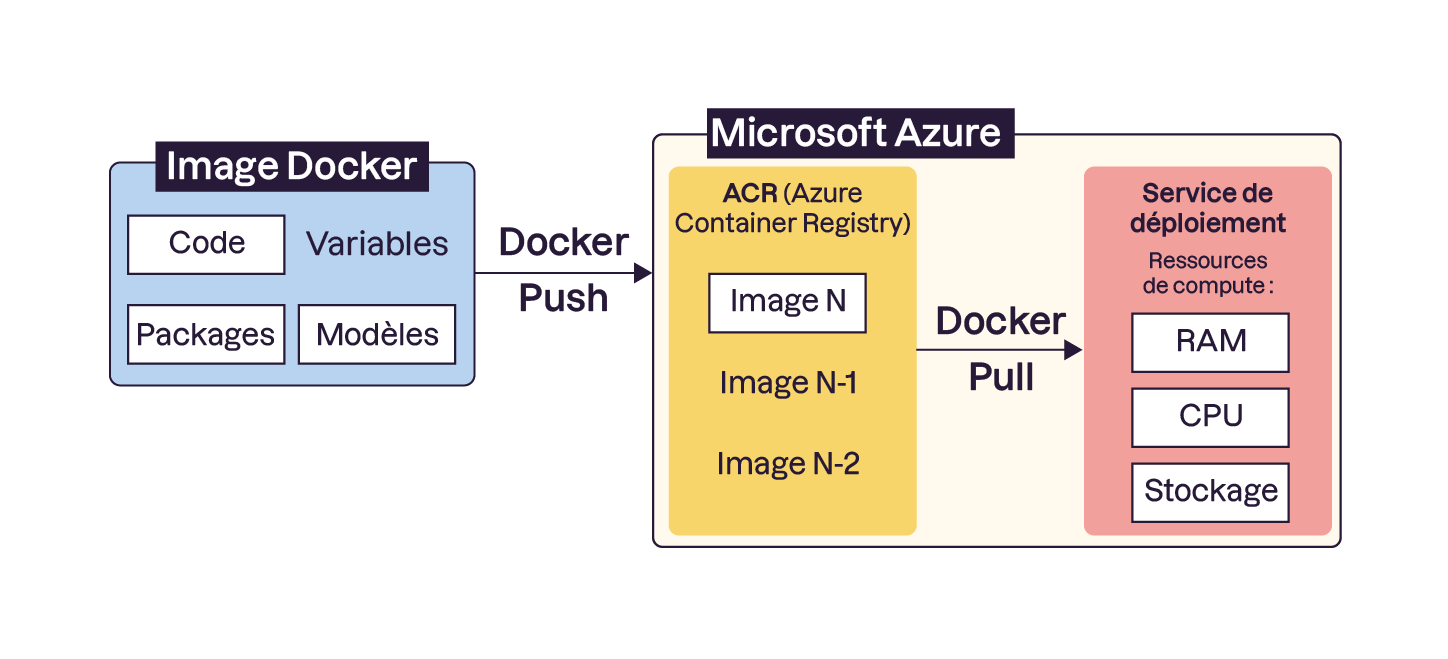
ACR (Azure Container Registry) va venir justement versionner toutes les images Docker que l’on décide de construire puis de pousser, sans s’occuper du déploiement. C’est un autre service qui va venir se charger du lancement du conteneur.
Réalisez votre première conteneurisation
Maintenant que l’on a compris au global comment Docker s’insère dans un projet. Rentrons dans le dur de comment Dockeriser notre projet, en commençant par un Dockerfile le plus simple possible :
Dans notre exemple, très basique, nous avons utilisé pip et un requirements.txt pour installer les packages. Cependant, vous savez désormais qu’UV est un outil beaucoup plus adapté pour gérer les dépendances d’un projet. Cela tombe bien, nous allons l’évoquer ensemble dans la section qui suit, quand on verra un exemple plus complexe de Dockerfile !
Maîtrisez le Layering de votre build Docker
Le screencast précédent vous a permis de comprendre comment lire un Dockerfile. Toutefois, ce fichier qu'on a passé en revue ensemble n'est en réalité pas optimisé. J'ai évoqué UV tout à l'heure, mais il ne s'agit pas de la piste d'optimisation la plus importante.
En réalité, l'opportunité d'optimisation la plus importante dans la Dockerisation, est ce que l'on appelle le Layering. Concrètement, chaque instruction de votre Dockerfile crée une couche (layer) distincte. Ces layers sont empilés les uns sur les autres pour former l'image finale.
Dans notre Dockerfile précédent, les deux layers les plus importants sont ceux liés aux instructions COPY . /app et RUN pip install -r requirements.txt.
Si l'on choisit de reconstruire la même image avec le même Dockerfile, Docker va utiliser un système de cache intelligent : si une instruction n'a pas changé et que les layers précédents sont identiques, Docker réutilise le layer en cache plutôt que de le reconstruire. C'est ce mécanisme qui permet d'accélérer considérablement les builds successifs.
Un build plus rapide est extrêmement intéressant, et pas simplement pour ne pas trop se tourner les pouces devant un PC pendant qu'il construit l'image Docker. Vous vous en doutez déjà après avoir compris la Big Picture et vous le comprendrez encore mieux dans deux chapitres, mais avoir des builds plus rapides signifie :
Réduire la durée entre le moment où vous poussez un nouveau code sur Git et le moment où ce même code est live en production
Réduire les coûts financiers associés à des docker builds très longs, car exécutés dans des machines que nous payons à l'utilisation dans le Cloud.
Si l'on relit ensemble le Dockerfile, on va remarquer que la ligne COPY . /app arrive avant la ligne RUN pip install -r requirements.txt. C'est justement un choix qui n'optimise pas du tout le layering. Cela signifie que dès que vous modifiez le moindre fichier dans votre projet (un commentaire dans votre code, un fichier de documentation, n'importe quoi), le layer COPY est invalidé, ce qui invalide également tous les layers suivants, y compris le RUN pip install.
Or, installer une nouvelle librairie Python pour répondre à un nouveau besoin du projet est un événement beaucoup moins fréquent que le fait de mettre à jour le code d'un projet, sans installer de nouveaux packages. Si l'on modifie simplement notre code métier sans toucher au fichier requirements.txt, on devrait pouvoir réutiliser le layer d'installation des packages. Mais avec l'ordre actuel, Docker est privé de cela car le COPY global a changé avant.
La bonne pratique consiste à écrire les instructions du Dockerfile dans un ordre décroissant de fréquence de modification. En principe, les variables d'environnement changent beaucoup moins régulièrement que les packages Python, qui eux-mêmes changent beaucoup moins régulièrement que le code du projet. Je ne le dirai jamais assez, ce principe est à adapter en fonction de votre projet et de ses contraintes.
En inversant les deux instructions vues précédemment, seul le dernier layer (celui qui copie le code) sera reconstruit à chaque modification de votre application, ce qui nous fera économiser facilement plusieurs minutes, comme nous avons beaucoup de packages de ML assez lourds installés !
Combinez UV et Docker pour un build optimisé
Maintenant que l’on a compris le Layering… parlons d’UV et décortiquons ensemble un Dockerfile qui l’utilise ! Vous verrez que certaines instructions optimisent notre image pour un usage en production. Elles ne sont pas nécessaires dans tous les contextes.
# ------------------- Image de Base + Configurations Globales -------------
FROM ghcr.io/astral-sh/uv:python3.12-bookworm-slim
WORKDIR /app
ARG POSTGRES_HOST
ARG POSTGRES_PORT
ARG POSTGRES_DB
ARG POSTGRES_USER
ARG POSTGRES_PASSWORD
ENV POSTGRES_HOST=$POSTGRES_HOST
ENV POSTGRES_PORT=$POSTGRES_PORT
ENV POSTGRES_DB=$POSTGRES_DB
ENV POSTGRES_USER=$POSTGRES_USER
ENV POSTGRES_PASSWORD=$POSTGRES_PASSWORD
ENV MLFLOW_TRACKING_URI=/app/mlruns
# --------------------- Configurations UV -------------------------
# Permet aux packages installés d'être compilés et importés plus rapidement dans le code
ENV UV_COMPILE_BYTECODE=1
# Copie depuis le cache au lieu de créer des liens car c'est un volume monté
ENV UV_LINK_MODE=copy
# Permet à UV d'attendre plus longtemps pour installer les packages, en cas de projet avec beaucoup de dépendances
ENV UV_HTTP_TIMEOUT=1000
# --------------------- Étapes Principales ---------------------
# Copie uniquement les fichiers nécessaires pour reproduire l'environnement virtuel avec les packages
COPY pyproject.toml uv.lock /app/
# ----- Installation du Projet avec UV ------
# Installe les dépendances du projet en utilisant le lockfile et les paramètres, pour une vitesse maximale
RUN --mount=type=cache,target=/root/.cache/uv \
uv sync --locked --no-dev
COPY . /app
# Activation de l'environnement virtuel
ENV PATH="/app/.venv/bin:$PATH"
EXPOSE 8000
CMD ["uvicorn", "p1_c4_orm:app", "--host", "0.0.0.0", "--port", "8000"]La première partie du fichier ainsi que ces deux dernières lignes de code restent quasiment inchangées ! La seule différence : l'image de base contenant la distribution Python est différente. Ici, nous utilisons une image de base accompagnée d’UV déjà installé ! Pratique pour la suite.
Maintenant, la vraie magie réside dans l'instruction RUN --mount=type=cache,target=/root/.cache/uv . Cette syntaxe crée un cache mount persistant : un volume qui persiste entre les builds successifs et qui n'est pas inclus dans l'image finale. Concrètement, lorsque UV télécharge un package (par exemple numpy), il le stocke dans /root/.cache/uv. Lors du prochain build, même si le layer est reconstruit, UV retrouve ces packages en cache et n'a pas besoin de les re-télécharger depuis PyPI. Ceci nous épargne de précieuses secondes, voire minutes consacrées au téléchargement des packages. Seule leur installation est provoquée par la reconstruction du layer.
La variable UV_COMPILE_BYTECODE=1 force UV à pré-compiler vos fichiers Python dès l'installation. Normalement, Python compile vos packages à leur première exécution, ce qui ralentit le démarrage de votre application. En compilant pendant le build, vous perdez un peu plus de temps pendant le build, mais vos conteneurs démarrent beaucoup plus rapidement pendant le run ! C'est particulièrement utile quand nous voulons une application en production qui démarre très rapidement !
La commande uv sync --locked --no-dev utilise le fichier uv.lock pour installer exactement les mêmes versions de dépendances, de manière déterministe. Le flag --no-dev exclut les dépendances de développement (pytest, ruff, etc.) pour alléger l'image finale. Le --locked garantit qu'UV échouera si le lockfile n'est pas à jour, évitant les surprises en production.
Enfin, la commande ENV PATH="/app/.venv/bin:$PATH" active l'environnement virtuel Python. C'est exactement la même chose qu'une source .venv/bin/activate que nous exécutons sous Linux pour lancer l'environnement créé par UV ! Bien évidemment, cette étape doit précéder le lancement de FastAPI.
Mais si Docker crée un environnement isolé et reproductible dans une autre machine… Pourquoi avons-nous besoin de créer un environnement virtuel Python en plus ? Cette double isolation n'est-elle pas redondante ?
Ça fait beaucoup de nouveautés d'un coup ! Ce chapitre est en effet dense, mais il est conçu pour que vous puissiez y revenir souvent, dès que vous arrivez à une phase dans votre projet où vous allez packager votre code pour le déployer en prod !
En résumé
Distinguez image et conteneur : l’image est le package, le conteneur est son exécution.
Dockerisez votre projet pour garantir portabilité, reproductibilité et déploiement simplifié.
Optimisez vos Dockerfiles en ordonnant les instructions selon leur fréquence de modification (layering).
Utilisez UV pour une gestion efficace et rapide des dépendances dans un environnement virtuel.
Déployez votre image sur une compute instance via un Container Registry (Docker Hub, ACR, etc.).
Passons maintenant au prochain chapitre pour découvrir comment automatiser tout ce processus avec les pipelines CI/CD !
