Connectez votre pipeline ML avec FastAPI
Maintenant vous avez en tête les fondamentaux pour “API-ser” le modèle de ML sur lequel vous avez beaucoup itéré dans votre projet, jusqu’à le rendre fiable. En revanche, l’histoire ne s’arrête pas là.
Dans le chapitre précédent, nous avons présenté un cas simple, voire simpliste, où le modèle est isolé de toute la phase de feature engineering qui y est intimement liée. Ceci n’est pas du tout réaliste quand on souhaite industrialiser un modèle en entreprise. Remédions à cela ensemble.
Calculez des features avec FastAPI
Réfléchissons un instant. Dans le chapitre précédent on a présenté une requête API de la part de l’utilisateur, comme suit :
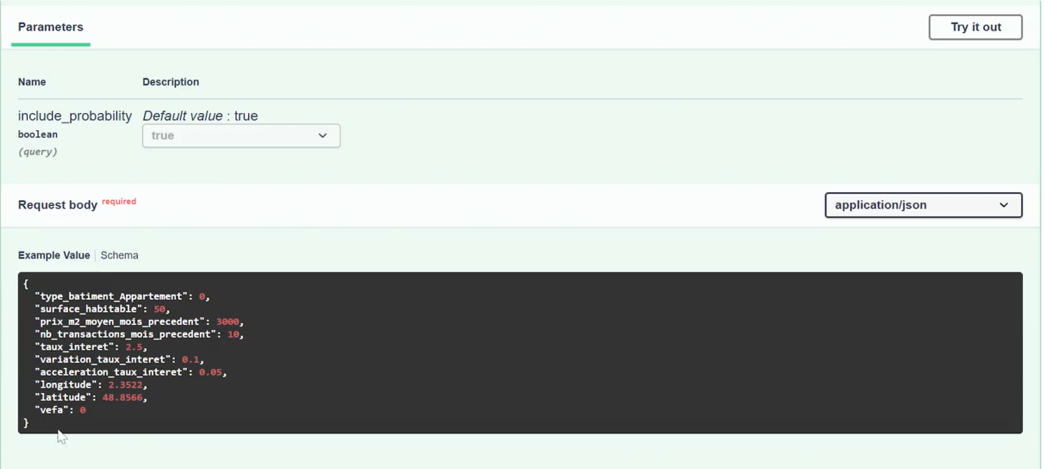
Mais en réalité, un utilisateur métier non-technique ne pourra jamais interroger le modèle ML par API de cette manière. Prenons par exemple les features catégorielles, elles ont subi un label encoding et un one-hot-encoding. Il faut être a minima Data Analyst pour 1 - savoir lire les features sous cette forme; 2 - comprendre pourquoi il est indispensable de représenter les features de cette manière.
Imposer ce genre de format à quelqu’un qui n’a pas vocation à comprendre les rouages techniques d’un algorithme ML, est évidemment contre productif pour sécuriser l’adoption de votre projet . C’est comme s’il fallait être mécanicien pour pouvoir démarrer une voiture ! Cela va contre l’esprit même d’une API. Le rôle de l’API est de faciliter au maximum l’interaction entre une personne et un algorithme.
De deux choses l’une. Il faudrait d’abord exposer à l’utilisateur une version simplifiée et orientée métier des inputs qu’il doit fournir au modèle. Ensuite, la logique de l’API doit réécrire les inputs simplifiés de l’utilisateur au format dans lequel le modèle est conçu pour les recevoir.
Regardons ensemble en screencast à quoi cela peut ressembler :
Et voilà ! Nous avons quelque chose de fonctionnel et de beaucoup plus réaliste du côté de l’utilisateur métier !
Mais on demande quand même à l’utilisateur métier de pouvoir lire un Swagger, ou d’être capable d’écrire une requête HTML de type curl depuis un Terminal. N’est-ce pas tout aussi irréaliste ?
C’est un très bon point. En effet, une interface Swagger suffirait pour des software engineer, d’autres data scientists qui auraient besoin de vos prédictions, sans avoir à gérer votre code, voire des data analysts initiés à l’utilisation du terminal ou d’un Swagger.
Pour des utilisateurs métier, il faut en plus créer un front-end, c’est-à-dire une interface web facile d’utilisation (et pas moche). Quand le projet n’est pas excessivement complexe, et/ou que le nombre d’utilisateur métiers est relativement bas, le package open-source Streamlit est votre ami.
C’est LE package Python open source incontournable, très prisé par les Data Scientists/ML Engineers, pour développer et déployer rapidement des fronts-ends simples, sans avoir à apprendre le langage JavaScript.
Combinez FastAPI et SQLModel pour gérer les données
Le code de la section précédente fonctionne quand nous pouvons obtenir un résultat via API uniquement à partir des paramètres que nous envoyons (par exemple, on envoie des valeurs de features pour obtenir une prédiction, modulo une logique de traduction des inputs métiers en features comme nous avons vu).
Cependant, nous avons plusieurs cas de figure fréquents de projets ML où cela ne suffit pas. Pour ne citer que quelques exemples :
L’utilisateur métier peut souhaiter comparer les inputs qu’il a soumis avec les données historiques du projet pour des analyses complémentaires
L’utilisateur métier peut remonter que les prédictions proposées par le modèle sont incohérentes
L’utilisateur métier peut labelliser des données (image, texte) pour enrichir un historique de targets
Il y a des opérations communes entre ces trois exemples : ils nécessitent de lire des données historiques et de les mettre à jour. Ça tombe bien, le langage SQL est parfait pour réaliser ces tâches.
Pourquoi nécessairement SQL ? Je pourrais charger ma donnée historique dans un DataFrame Pandas et faire le nécessaire.
Dans une certaine mesure oui, mais ce serait moins optimal et surtout impossible à faire passer à l’échelle. Imaginez la situation suivante : vous interrogez l’API pour avoir une prédiction du prix moyen au m2 à Strasbourg sur les 3 derniers mois. Ensuite, l’API charge TOUTE la donnée historique à l'échelle nationale et sur plusieurs années dans un Pandas Dataframe, pour enfin la filtrer sur le périmètre voulu avant de nourrir le modèle ML. Clairement, on s'impose une opération superflue et très coûteuse en stockage et en puissance de calcul.
Le SQL permet justement de décharger le serveur où se trouve le modèle, en injectant uniquement la donnée nécessaire pour répondre à la requête envoyée à l’API.
Donc quand j’envoie des paramètres via un appel API, il faut que mon code Python contenant FastAPI… exécute une requête SQL ?
C’est cela ! Nous avons deux façons d’implémenter du SQL au sein de Python. La première est très simple, on utilise ce que l’on appelle un query engine. C'est tout simplement un connecteur qui fait le pont entre votre code Python et votre base de données. Il exécute vos requêtes SQL et vous retourne les résultats directement utilisables dans Python (souvent sous forme de liste ou de DataFrame). Concrètement, on écrit la requête SQL dans un formatted string, et on l'exécute via le query engine comme ceci :
import sqlite3
import pandas as pd
def charger_features(ville: str, type_bien: str, surface_min: float):
"""Charge les features depuis la base de données selon les filtres"""
query = f"""
SELECT
surface_habitable,
type_batiment_Appartement,
taux_interet,
nb_transactions_mois_precedent
FROM features_immobilieres
WHERE ville = '{ville}'
AND type_bien = '{type_bien}'
AND surface_habitable >= {surface_min}
ORDER BY date DESC
LIMIT 1
"""
conn = sqlite3.connect('immobilier.db')
df_features = pd.read_sql_query(query, conn)
conn.close()
return df_features
df_features = charger_features(
ville="Strasbourg",
type_bien="Appartement",
surface_min=35
)Ce code se lit comme une requête SQL ! Définir la requête au sein d’une fonction permet, entre autres, de rendre dynamique les filtres WHERE. En l'occurrence nous requêtons une base SQLite (avec le package sqlite3), mais les autres types de BDD les plus couramment utilisés fonctionnent exactement de la même manière.
Une autre solution, moins verbeuse et plus “Pythonique”, consiste à utiliser ce que l’on appelle un ORM. Qu’est-ce que c’est ? Demandons à Mistral :
En termes simples, un ORM (Object Relational Mapping) te permet de manipuler les données de ta base de données comme si c’étaient des objets Python, au lieu d’écrire directement du SQL.
Grâce à un ORM, tu peux :
Définir tes tables comme des classes Python (par exemple, une classe
Utilisateurpour une tableutilisateurs).Lire, créer, modifier ou supprimer des données en utilisant des méthodes Python, sans écrire de requêtes SQL manuellement.
Bénéficier de la validation automatique des données (par exemple, vérifier qu’un email est valide avant de l’enregistrer).
Par exemple, au lieu d’écrire :
INSERT INTO utilisateurs (nom, email) VALUES ('Zakaria', 'zakaria@example.com');Avec ORM, tu écris :
utilisateur = Utilisateur(nom="Zakaria", email="zakaria@example.com") session.add(utilisateur) session.commit()Pratique non ?
Et ça tombe bien, le créateur de FastAPI a pensé exactement à cela. Il a créé un package Python d’ORM très efficace qui s'intègre parfaitement avec FastAPI. Il s’agit du package SQLModel.
Découvrez le demo de la pipeline feature engineering et inférence
Essayons de résumer ce qui se passe sous le capot quand un utilisateur métier fait appel au modèle via API :
Les inputs de l’utilisateur sont encapsulés dans les paramètres (path & query) ainsi que le body content
FastAPI va exécuter les fonctions concernées par l’appel API. Celles-ci vont récupérer les inputs de l’appel API et éventuellement requêter des données supplémentaires stockées dans une BDD SQL. Pour ce faire, SQLModel est un choix courant
L’API renvoie les résultats des fonctions exécutées par les endpoints, tout en s’assurant grâce à Pydantic que les entrées et les sorties sont sous un format conforme à celui attendu.
Regardons tout cela en action.
Nous avons fait une démo avec PostgreSQL, solution très répandue, mais vous pouvez très bien vous pencher vers d’autres solutions. Une particulièrement en vogue en ce moment est DuckDB, je vous encourage fortement à aller y jeter un coup d'œil quand vous serez plus à l’aise avec les concepts de ce chapitre !
Allez plus loin avec FastAPI
En réalité, la meilleure ressource pour aller plus loin dans FastAPI… est la section "Learn de la documentation officielle de FastAPI" ! Elle est aux petits oignons !
Je recommanderais particulièrement les chapitres Testing, Debugging & Bigger Applications de la partie User Guide. Ensuite, tout dépendra des besoins spécifiques de votre projet ! Vous avez bien compris à ce stade que le plus difficile dans la conception d’un projet ML n’est pas le code en lui-même mais plutôt comment penser les briques techniques en fonction des contraintes métier et techniques de votre projet.
En résumé
Simplifiez les inputs utilisateur en exposant une version métier, puis transformez-les côté API en features exploitables par le modèle.
Utilisez Streamlit pour créer un front-end accessible aux utilisateurs métier si besoin.
Requêtez une base SQL depuis FastAPI pour enrichir les inputs avec des données historiques pertinentes.
Préférez SQLModel pour manipuler des BDD de manière Pythonique et intégrée avec FastAPI.
Structurez vos appels API en combinant FastAPI, Pydantic et SQLModel pour une pipeline cohérente et maintenable.
Prêts à mettre tout cela en pratique ? Passons au prochain chapitre pour explorer les stratégies de déploiement d’un modèle ML en production !
