Decouvrez les autres enjeux de ML Engineeing
Comme dit à la fin du chapitre précédent. Ici, on va toucher à beaucoup de choses, mais ne rien approfondir. L’objectif est de vous donner de la vision, de vous faire découvrir certaines problématiques communes de ML Engineering que nous ne pouvons pas couvrir dans ce cours, au moins de changer son titre de "Initiation au ML Engineering" à "Formation complète".
C’est que du bonus, alors profitez-en !
Comprenez les enjeux d’Infrastructure
Pendant la deuxième partie du cours, on a vu que déployer un modèle ML passait souvent par la location d’une machine virtuelle dans le Cloud. C’est le fameux compute instance qui héberge nos modèles Dockerisés ! Cependant, on ne s’est pas du tout intéressés aux caractéristiques de ce compute instance. Combien de RAM, de CPU, de mémoire en stockage ? D’ailleurs, qui nous dit qu’il nous en faut qu’un seul ?
Si l’équipe Data figure plusieurs Data Scientists qui veulent déployer des modèles, il faut une stratégie de gestion de ces ressources en Compute et en Storage, ainsi qu’un outil pour rapidement implémenter cette stratégie et l’ajuster au fil de l’eau.
Bienvenue dans le monde de l’Infrastructure Management ! C’est le domaine où l’on gère dynamiquement toutes les ressources informatiques dont nos applications ont besoin pour fonctionner.
Et je dis bien TOUTES les ressources ! Les compute instances ne représentent qu’une fraction de ce que l’on peut gérer. Pour donner d’autres exemples, on peut gérer automatiquement le fonctionnement d’un GitHub d’entreprise :
Qui a la permission de créer un répo, d’écrire dans un répo, ou de tout simplement voir le répo
Les caractéristiques des runners dans GitHub Actions, qu’on connaît désormais bien
La gestion des secrets Github Actions, qui sont utilisés dans un pipeline CI/CD
Et j’en passe et des meilleurs !
Tu parles d’un outil pour automatiser ces prises de décisions liées à l’Infra. De quoi s’agit-il ?
À l’heure d’écriture de ce cours, la tendance dominante dans le monde de la Data quand il s’agit d’Infra Management est celle de l’IaC (Infrastructure as Code). Comme le nom l’indique, le principe est le suivant : j’écris toutes mes instructions de gestion d’infrastructure… avec du code ! Exécuter ce code, crée ou modifie l’infrastructure.
Aujourd’hui, l’un des outils d’IaC les plus répandus est Terraform. Parlons en un tout petit peu plus avant de clôturer cette section !
Terraform propose d’écrire l'infrastructure avec un langage spécial nommé le HCL. Le script ressemble pas mal à un fichier de config YAML ou un JSON, même si la syntaxe n’est pas la même. Ceci dit, en lisant un fichier peu complexe, on peut comprendre ce qui se passe !
# Configuration du provider AWS
provider "aws" {
region = "eu-west-1"
}
# Création d'une compute instance EC2 pour héberger notre modèle ML
resource "aws_instance" "ml_model_server" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t3.large"
tags = {
Name = "ML-Model-Production"
Environment = "production"
Team = "data-science"
}
# Configuration du stockage
root_block_device {
volume_size = 50
volume_type = "gp3"
}
}
# Création d'un bucket S3 pour stocker les artifacts du modèle
resource "aws_s3_bucket" "ml_artifacts" {
bucket = "company-ml-artifacts"
tags = {
Purpose = "ML Model Storage"
}
}Dans cet exemple de code Terraform, on définit l'infrastructure nécessaire pour déployer un modèle ML en production. On commence par spécifier qu'on travaille avec AWS dans la région Europe de l'Ouest. Ensuite, on crée une compute instance EC2 de type t3.large (2 vCPUs, 8 Go de RAM) qui hébergera notre modèle ML API-sé et Dockerisée. On lui attribue des tags pour faciliter la gestion et le suivi des coûts. On configure également 50 Go de stockage pour l'instance. Enfin, on crée un bucket S3 qui servira à stocker nos artifacts ML, avec une logique similaire de ce que l’on a vu dans le chapitre précédent. En exécutant ce code avec terraform apply, toute cette infrastructure sera créée automatiquement en quelques minutes !
Mais comment Terraform, un outil qui n’existe pas dans AWS, arrive à manipuler des ressources AWS ?
Eh bien, les créateurs de Terraform (HashiCorp) ont énormément investi dans la création et la maintenance de plug-ins pouvant interagir (souvent via API) avec des Cloud Providers et des Softwares. Pour vous rendre compte de à quel point Terraform est un acteur puissant dans l’IaC, je vous invite à aller parcourir la liste des providers actuellement en vigueur.
Traditionnellement, Terraform et l’IaC au sens large, sont des compétences souvent associées aux DevOps. Mais comme le ML Engineering est à la croisée des chemins entre plusieurs disciplines, les principales étant La Data Science, le Data Engineering et le DevOps, l’IaC peut rentrer dans le champ de compétences d’un ML Engineer.
Monitorez la santé de votre Infra
Restons dans le domaine de l’Infrastructure Management ! Si Terraform est un pionnier dans la création et l’ajustement de l’infra, il ne permet pas du tout de monitorer son fonctionnement, sa santé et de détecter des anomalies pendant qu’elle tourne.
En effet, on a supposé pendant la deuxième partie du cours qu’on est dans le meilleur des mondes et que toutes les compute instance que nous pourrions louer, seraient parfaitement fonctionnelles pendant toute la durée de vie du modèle de ML, quelque soit la lourdeur des calculs réalisés et le nombre d’utilisateurs qui souhaitent appeler le modèle ML par API en même temps.
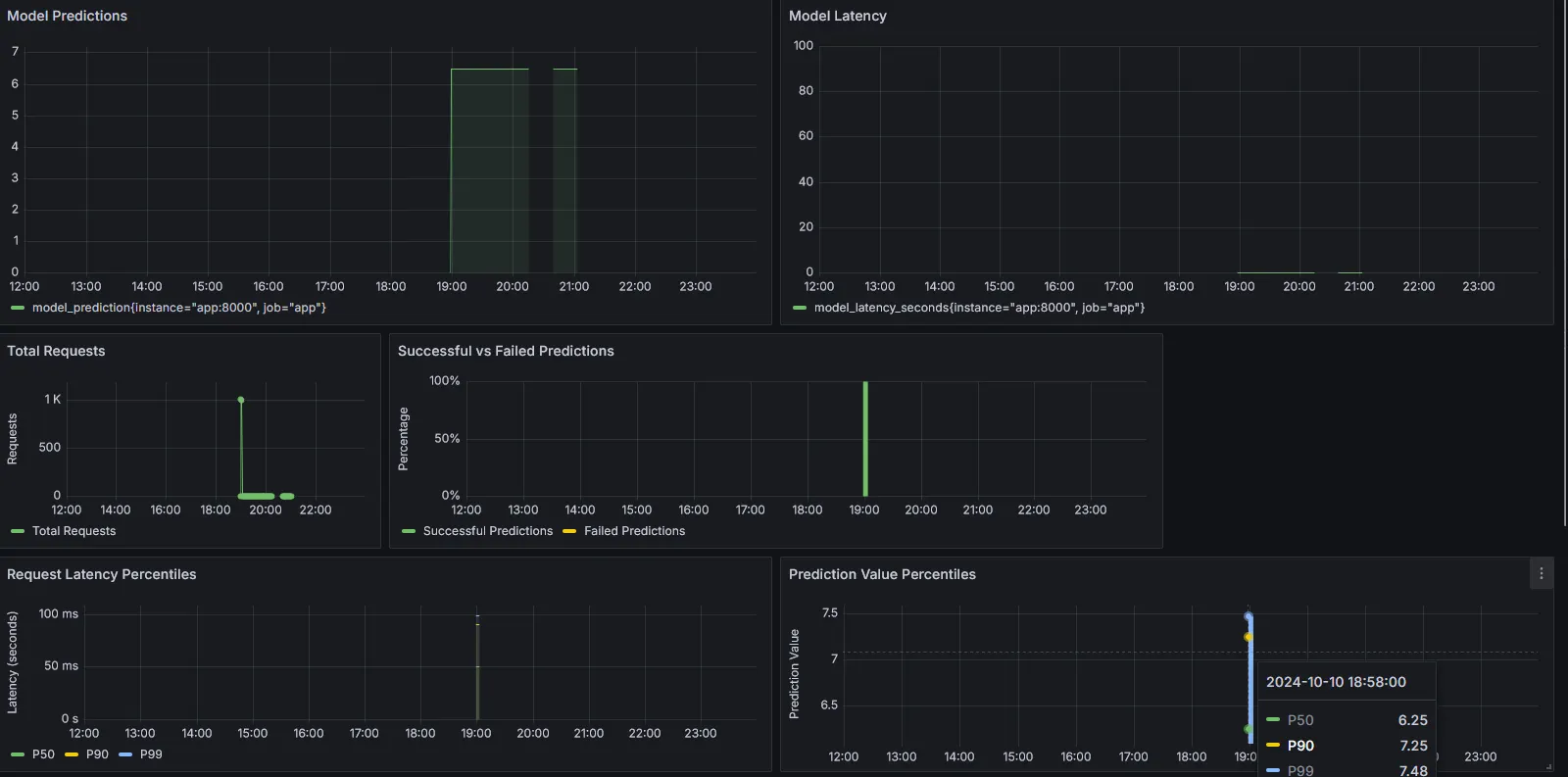
Soyons réalistes, nous pouvons surcharger une compute instance, ou subir involontairement une anomalie concernant nos ressources. Plusieurs outils existent pour couvrir ce besoin, mais nous allons citer ici le duo Prometheus & Grafana.
Pour faire très simple, Prometheus va venir collecter pour nous, toutes les x secondes (par défaut 15 secondes), les métriques de santé de notre infra que nous souhaitons tracker, et Grafana va nous mettre à disposition un dashboard pour les visualiser. Dans le cadre d’un projet ML en prod, il est pertinent de collecter des infos comme :
Le pourcentage d’utilisation de la RAM, CPU, GPU et du Disque I/O. Si ces métriques sont tout le temps très élevées, c’est peut-être le signe qu’il faut augmenter la puissance des ressources physiques, avec Terraform par exemple.
Le nombre d’appels API au modèle et sa latence de réponse. Nous avons vu une implémentation simple de FastAPI, mais si nous remarquons un nombre d’appels API et une latence plus élevée qu’attendue, il faudrait sans doute prévoir une refonte du fonctionnement de l’API et d’implémenter des fonctionnalités plus avancées de FastAPI.
Voici à quoi tout cela pourrait ressembler dans Grafana (exemple issu de l’article suivant) :
Il est également possible de tracker des métriques purement ML, comme le rappel, la précision, le R2 etc. Mais nous avons vu ensemble MLFlow, et dans un autre cours Evidently, qui sont plus adaptés pour cette composante.
Comprenez les enjeux du Scheduling
Pour terminer, nous allons sortir du domaine de l’Infrastructure Management pour aborder un dernier concept incontournable dans la gestion des projets ML (et Data et Software d’ailleurs) : L’orchestration.
Si l’on reprend notre cas d’usage immobilier, on a vu lors des chapitres précédents qu’il était opportun de passer par une base de données pour ne fournir au modèle ML que ce dont il a besoin pour l’inférence. Nous avons notamment vu du code qui chargeait une partie des features depuis une table.
Cela sous-entend que nous avons une, voire plusieurs tables SQL, qui :
Transforment l’historique brut de données en un historique de features proche du format attendu par un modèle ML.
Sont régulièrement mise à jour par un processus automatisé.
Sauf que, pour mettre à jour ces tables, il faut que les données brutes soient à jour. Celles-ci dépendent peut-être d’autres mises à jour d’autres systèmes aussi ! Comment pouvons-nous cadencer tout cela, pour éviter d’avoir des pipelines de transformation qui tournent sans que tous les prérequis soient réunis ?
La réponse la plus basique serait d'utiliser cron, l'outil de scheduling natif des systèmes Unix/Linux. On pourrait imaginer lancer chaque tâche à des horaires décalés : extraction des données brutes à 1h00, création des features à 2h00, réentraînement du modèle à 3h00, etc. Simple, non ?
Malheureusement, cette approche pose de sérieux problèmes ! Si l'extraction des données brutes prend exceptionnellement 1h30 au lieu de 30 minutes à cause d'un ralentissement de la base source ou d’une quantité exceptionnelle de données entrantes qui casse la compute instance réalisant la mise à jour, votre script de feature engineering se lancera quand même à 2h00 pile... sur des données incomplètes ou obsolètes. A ce stade, je n’ai plus à vous expliquer l’impact d’une telle situation sur la qualité du modèle ML en bout de chaîne !
De plus, avec cron, vous n'avez aucune visibilité sur ce qui se passe réellement : pas de logs centralisés, pas d'alertes automatiques en cas d'échec, aucun moyen simple de relancer une tâche qui a planté sans tout recommencer depuis le début. Et si vous voulez ajouter une étape de validation des données avant le feature engineering ? Il faut repenser tout le cadençage de vos horaires manuellement !
C'est précisément pour résoudre ces problématiques qu'existent les orchestrateurs de workflows comme Apache Airflow. Avec Airflow, vous définissez vos pipelines sous forme de DAG (Directed Acyclic Graph) : un graphe où chaque nœud représente une tâche, et les flèches représentent les dépendances entre elles. Airflow s'assure qu'une tâche ne démarre que si toutes ses dépendances ont réussi. Le tout, en Python.
Concrètement, votre pipeline immobilier ressemblerait à : Extraction données brutes → Feature engineering → Entraînement modèle → Validation performances → Déploiement (si validation OK). Si l'extraction échoue, Airflow arrête tout, vous envoie une alerte, et vous permet de relancer uniquement la partie qui a planté sans recommencer l'ensemble du pipeline.
A ce sujet, l’une des pratiques courantes en entreprise est de connecter Airflow à un canal Microsoft Teams ou équivalent pour y poster ces fameuses alertes.
Airflow offre également un dashboard web qui vous donne une visibilité totale sur l'historique et l'état actuel de vos pipelines : quelles tâches sont en cours, lesquelles ont réussi, lesquelles ont échoué, combien de temps chacune a pris, et pourquoi tel ou tel échec s'est produit grâce aux logs intégrés.
Dans une équipe Data où plusieurs Data Scientists et ML Engineers déploient des dizaines de modèles avec leurs propres pipelines de réentraînement et de mise à jour de features, tout en utilisant tous les mêmes données brutes, Airflow devient tout simplement indispensable pour garder le contrôle, assurer la fiabilité de vos systèmes ML, et éviter des problèmes de qualité de données en production !
En résumé
Automatisez la gestion des ressources Cloud avec l’IaC, en particulier via Terraform.
Monitorisez votre infrastructure avec Prometheus & Grafana pour détecter rapidement les anomalies.
Orquestrez vos pipelines de données et de réentraînement avec Apache Airflow pour éviter les erreurs de timing.
Définissez vos workflows comme des DAGs afin de sécuriser les dépendances entre les tâches.
Combinez toutes ces briques pour fiabiliser, maintenir et scaler vos systèmes de Machine Learning en production.
Bravo, vous êtes arrivé au bout de ce cours d’initiation au ML Engineering ! Pour continuer à monter en compétences, formez-vous sur des projets concrets ou approfondissez les outils vus ici en contexte réel !
