Explorez et comprenez la structure de la série avec Statsmodels

Vous venez de nettoyer et préparer une série hebdomadaire. Maintenant, vous allez apprendre à repérer une tendance, reconnaître une saisonnalité, détecter des anomalies, puis vérifier si la série est “stable” (stationnaire) pour savoir quels modèles seront adaptés.
En entreprise, cette étape sert souvent à répondre à des questions simples mais cruciales :
“Est-ce que l’activité augmente vraiment ou est-ce un effet saisonnier ?”
“Ce pic est-il un événement réel ou un problème de collecte ?”
“Peut-on comparer cette semaine à une semaine ‘normale’ ?”
Repérez visuellement les tendances et anomalies
Visualisez vos données temporelles avec Plotly
Commençons par charger la série hebdomadaire préparée au chapitre précédent.
import pandas as pd
import plotly.express as px
weekly = pd.read_csv("epidemioscope_weekly.csv", parse_dates=["date"])
weekly = weekly.set_index("date")["ili_consultations"].sort_index()
display(weekly.head())Lors du chapitre précédent nous avons utilisé plotly sans jamais rentrer dans le détails.
Alors déjà, pourquoi plotly et pas matplotlib ?
Un des arguments principaux est l’intéractivité de plotly express dans les notebook jupyter.
Zoomer, dézoomer ou pointer une valeur facilite l’exploration de données :
fig = px.line(
x=weekly.index,
y=weekly.values,
labels={"x": "Date", "y": "Consultations"},
title="EpidemioScope — consultations (hebdo)",
)
fig.show()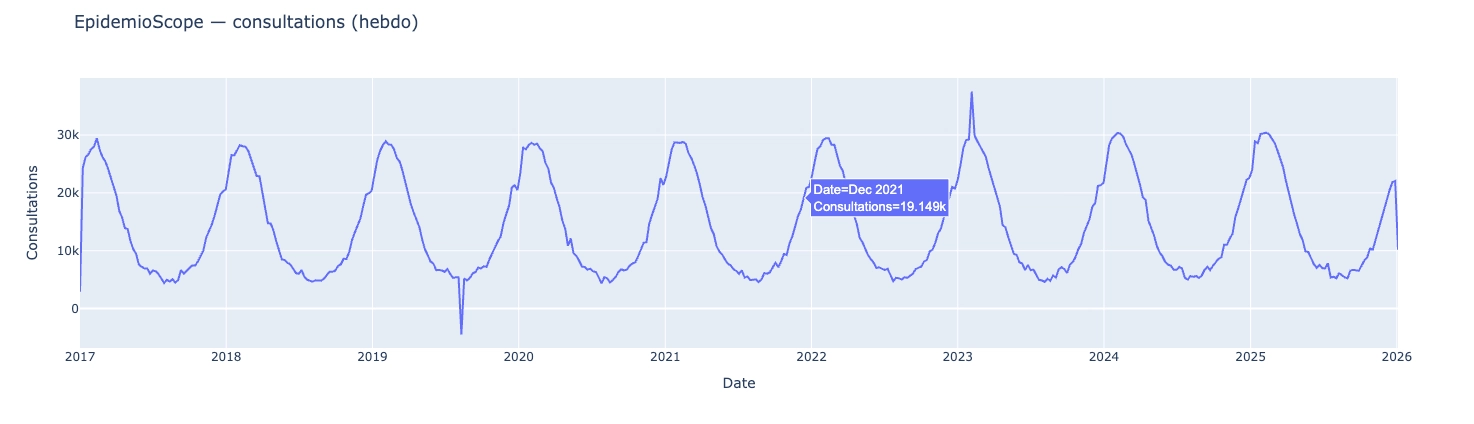
Grâce à plotly vous allez déjà pouvoir décrire ce que vous voyez, sans théorie complexe:
la série monte-t-elle ou baisse-t-elle globalement ?
observe-t-on un motif qui revient chaque année ?
existe-t-il des pics isolés ?
Identifiez une tendance globale
Une tendance correspond à un mouvement lent du niveau moyen de la série. Pour mieux la lire, vous pouvez lisser le signal avec une moyenne mobile.
trend_rolling = weekly.rolling(window=12).mean()
df_trend = pd.DataFrame({
"date": weekly.index,
"Série observée": weekly.values,
"Moyenne mobile 12 semaines": trend_rolling.values,
})
df_trend = df_trend.melt(id_vars="date", var_name="Série", value_name="Consultations")
fig = px.line(
df_trend,
x="date",
y="Consultations",
color="Série",
title="Signal hebdo et tendance lissée",
)
fig.show()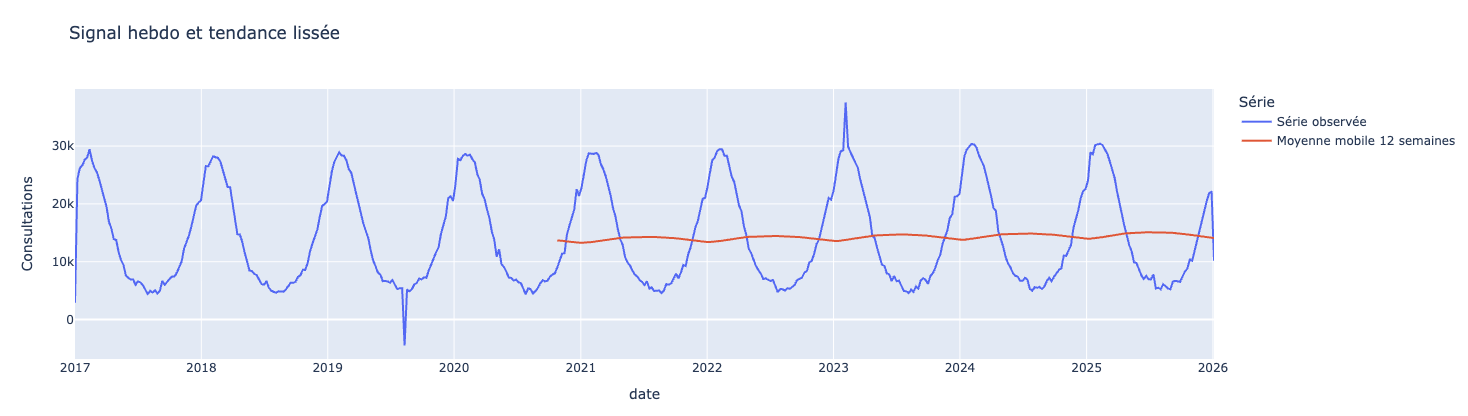
Dans notre cas la moyenne mobile à 12 semaines ne nous apporte que peu d’informations sur la tendance de fond de la série.
Voici une règle pratique pour choisir une fenêtre de moyenne mobile
Fenêtre trop courte → vous lissez à peine (vous suivez le bruit).
Fenêtre trop longue → vous perdez les variations utiles (vous “écrasez” le signal).
Pour une série hebdomadaire : essayez 13 semaines (≈ trimestre), puis 52 semaines (≈ annuel), puis comparez.
En essayant avec 200 semaines et en zoomant sur la tendance lissée, arrivez-vous à percevoir la tendance qui augmente ?
La moyenne mobile sert de première approche, mais ce n’est pas un modèle fiable, c’est une aide pour distinguer le bruit de la tendance de fond.
Dans notre cas, une particularité de notre dataset vient rendre la moyenne mobile difficile à lire, et c’est la saisonnalité de nos données.
Repérez les saisonnalités
Voyez la saisonnalité comme une schéma qui se répète. Dans notre dataset, la donnée oscille régulièrement.
Sur une série hebdomadaire, la saisonnalité annuelle est en général proche de **52 semaines**.
La saisonnalité, c’est une variation qui revient à intervalles réguliers (ex. hiver/été). Dans un modèle, ça signifie souvent : “si je connais la semaine de l’année, j’ai déjà une bonne information”.
Si la saisonnalité est forte, certains modèles simples (régression naïve, moyenne mobile) peuvent être trompeurs. La décomposition STL va nous aider à isoler la partie “répétitive” avant de parler de prédiction.
Un premier repère visuel consiste à regarder si les pics se reproduisent à des périodes proches d'une année à l'autre.
weekly_by_year = weekly.to_frame("y")
weekly_by_year["year"] = weekly_by_year.index.year
weekly_by_year["week"] = weekly_by_year.index.isocalendar().week.astype(int)
pivot = weekly_by_year.pivot_table(index="week", columns="year", values="y", aggfunc="mean")
display(pivot.head())
plot_season = pivot.reset_index().melt(id_vars="week", var_name="year", value_name="consultations")
fig = px.line(
plot_season,
x="week",
y="consultations",
color="year",
title="Profil hebdomadaire par année (saisonnalité)",
)
fig.show()
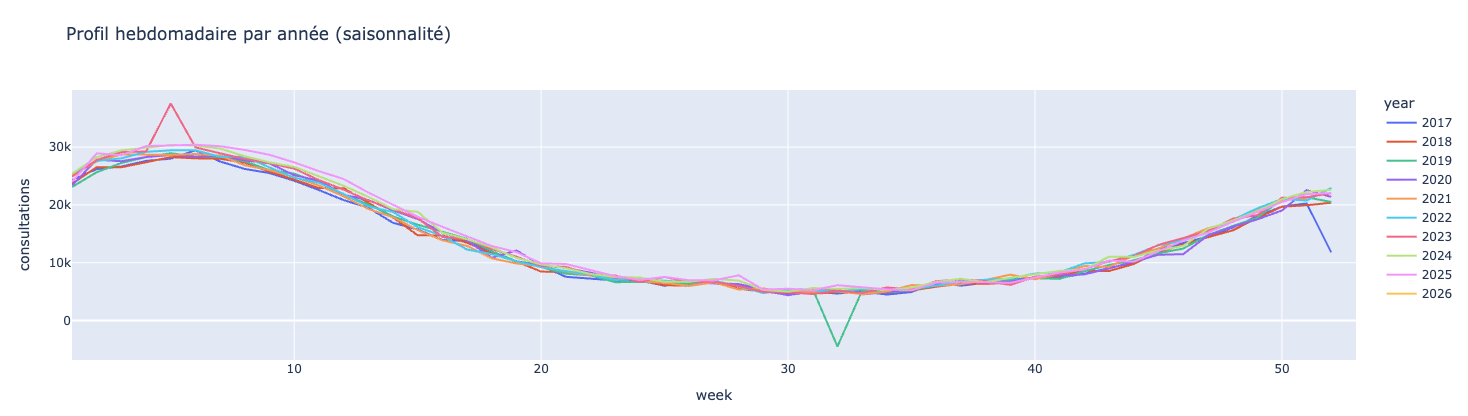
Nous pouvons voir que les courbes annuelles ont des formes extrêmement proches, ce qui est typique pour une saisonnalité récurrente.
Détectez les valeurs inhabituelles
Vous êtes normalement déjà familiers avec le Z-score, et nous pouvons le réutiliser pour détecter les anomalies de valeurs.
Pour rappel, le Z-score est utile pour alerter, pas pour conclure automatiquement. Dans un contexte épidémiologique, un pic peut être un vrai événement, pas une erreur.
z = (weekly - weekly.mean()) / weekly.std()
anomalies = weekly[z.abs() > 3]
display(anomalies.head())
print("Nombre d'anomalies détectées :", anomalies.shape[0])
df_weekly = weekly.reset_index(name="consultations")
df_anom = anomalies.reset_index(name="consultations")
fig = px.line(df_weekly, x="date", y="consultations", title="Série hebdo avec anomalies détectées")
fig.add_scatter(
x=df_anom["date"],
y=df_anom["consultations"],
mode="markers",
name="Anomalies (|z| > 3)",
)
fig.show()
Vous pouvez observer que le Z-score ne détecte aucune anomalie, pourtant certaines données paraissent aberrantes aux vu des données. Essayez de passer le Z-score à 2 et regardez l’impact.
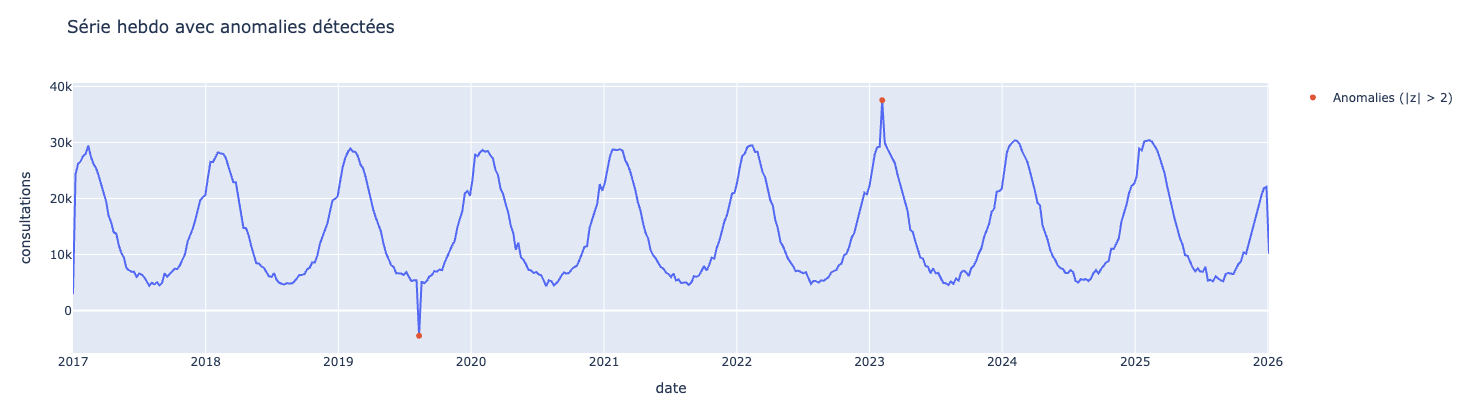
Pourquoi alors le Z-score ne détecte pas très bien les valeurs aberrantes dans notre cas ? Parce qu'il y a une saisonnalité forte.
Ok donc pour résumer, la moyenne mobile sert à observer une tendance de fond mais c'est inefficace s'il y a de la saisonnalité… Le z-score permettrait de détecter des anomalies, mais c'est inefficace s'il y a de la saisonnalité, du coup comment on s’en sort ?
Au lieu de comparer chaque point à la moyenne globale, comparez-le à la moyenne de la même semaine de l’année. Exemple : la semaine 3 de 2019 doit être comparée aux semaines 3 des autres années. C’est souvent beaucoup plus juste pour repérer des anomalies “à saison égale”.
Une “anomalie” est-elle une erreur de données (capteur cassé, retard de collecte) ou un événement réel (épidémie, campagne de dépistage) ? Dans le doute, on alerte mais on ne “corrige” pas sans validation métier.
Décomposez la série
Séparez tendance, saisonnalité et bruit
Afin de comprendre réellement une série temporelle, nous pouvons la décomposer en 3 parties distinctes :
La Saisonnalité (Seasonal) : motif répétitif,
La Tendance (Trend) : évolution lente de long terme,
Le Bruit ou Résidus (Loss) : bruit et événements non expliqués.
Cette séparation STL (Seasonal, Trend, Loss) facilite l'explication métier et le choix du modèle.
La décomposition vous permet de dire :
“La hausse vient de la tendance (structurelle).”
“Les pics d’hiver sont de la saisonnalité (attendue).”
“Ce point-là est dans le résidu (donc potentiellement inhabituel).”
Comparez une série brut et une série décomposée
Observons nos données :
from statsmodels.tsa.seasonal import seasonal_decompose
decomp = seasonal_decompose(weekly, period=52)
decomp_df = pd.DataFrame({
"date": weekly.index,
"observed": decomp.observed,
"trend": decomp.trend,
"seasonal": decomp.seasonal,
"resid": decomp.resid,
})
decomp_long = decomp_df.melt(id_vars="date", var_name="component", value_name="value")
fig = px.line(
decomp_long,
x="date",
y="value",
facet_row="component",
title="Décomposition (observed / trend / seasonal / resid)",
height=900,
)
fig.update_yaxes(matches=None)
fig.for_each_annotation(lambda a: a.update(text=a.text.split("=")[-1]))
fig.show()
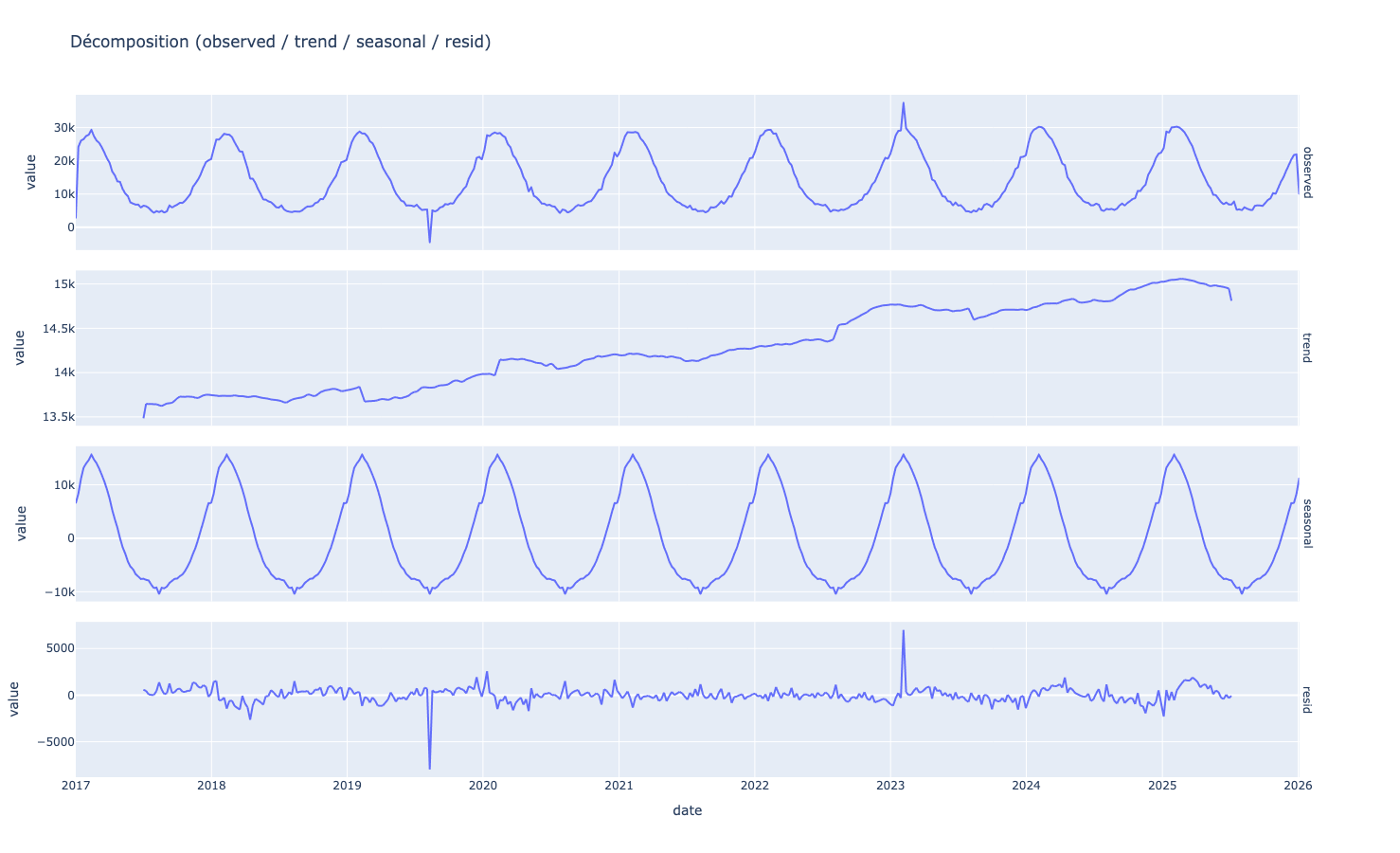
Cette fois-ci grâce à la courbe de tendance, nous observons une réelle évolution positive de nos données, ce qui avait été trouvé laborieusement en jouant avec les moyennes mobiles.
La saisonnalité est aussi très marquée, ce qui renforce l’idée d’un modèle de données saisonnier.
La Loss quand a elle met en valeur très distinctement les valeurs aberrantes.
Évaluez la stationnarité
Comprenez l’intérêt des séries “stables”
Une série stable ou stationnaire est une série dont les caractéristiques principales (moyenne, écart-type..) ne changent pas dans le temps. Une série avec de fortes variations de saisonnalité n’est généralement pas considérée comme stationnaire.
Avoir une série stable permet de :
Mieux prévoir : les modèles de prédictions sont plus fiables
Avoir des seuils d’alertes cohérents : les pics d’anomalies sont réellement détectés
Mieux expliquer les résultats : “Ce point est normal par rapport au comportement habituel”
Stationnaire ne veut pas dire “plat”, ça veut dire : comparable dans le temps. Si la série change de niveau ou de variance, beaucoup de méthodes “classiques” deviennent fragiles, car elles supposent que le passé ressemble (un peu) au futur.
Appliquez deux tests statistiques pour évaluer la stabilité de la série
Nous allons vérifier la stationnarité de notre série avec deux tests statistiques :
le premier test ADF (Augmented Dickey-Fuller) demande : “Est-ce que la série dérive sans motif”? —> Elle augmente, diminue sans schéma distinct, comme si le prochain point de donnée est dû au hasard
le second test KPSS (Kwiatkowski–Phillips–Schmidt–Shin) demande l’inverse : “Est-ce que la série reste stable autour d’un niveau”?
ADF part du principe que la série est non stationnaire et KPSS part du principe que la série est stationnaire. En testant les deux, il est plus simple d’évaluer la robustesse de la conclusion des deux tests.
Mettons ça en pratique :
from statsmodels.tsa.stattools import adfuller, kpss
adf_p = adfuller(weekly.dropna())[1]
kpss_p = kpss(weekly.dropna())[1]
print("p-value ADF:", adf_p)
print("KPSS p-value:", kpss_p) ADF | KPSS | Interprétation |
Rejette (p-value <0.05) | Ne rejette pas (p-value≥0.05) | Série stationnaire |
Ne rejette pas (p-value≥0.05) | Rejette (p-value <0.05) | Série non stationnaire |
Rejette (p-value <0.05) | Rejette (p-value <0.05) | Série instable |
Ne rejette pas (p-value≥0.05) | Ne rejette pas (p-value≥0.05) | Manque d’informations |
Nous allons nous concentrer sur les transformations de la série elle-même plutôt que sur les tests.
Appliquez les méthodes permettant de rendre une série plus stable
Lorsqu’une série est trop instable, certaines transformations peuvent être utilisées:
Si la tendance est trop forte, nous pouvons l’atténuer en utilisant
.diff(1), par exempleweekly.diff(1)(Différenciation d’ordre 1 —> Pour se la raconter en diner mondain)Si la saisonnalité annuelle est importante, nous pouvons l’atténuer en utilisant
.diff(52), par exempleweekly.diff(52)( Différenciation saisonnière —> Toujours pour briller en société)
adf_p_raw = adfuller(weekly.dropna())[1]
adf_p_diff1 = adfuller(weekly.diff(1).dropna())[1]
adf_p_diff52 = adfuller(weekly.diff(52).dropna())[1]
print("p-value ADF (brut) :", adf_p_raw)
print("p-value ADF (diff 1) :", adf_p_diff1)
print("p-value ADF (diff 52) :", adf_p_diff52)Dans notre cas, la série brut était déjà stationnaire.
À vous de jouer !

Consigne :
Décomposezdaily puis répondez aux questions suivantes :
la tendance monte/descend-elle ?
l’amplitude saisonnière est-elle stable ?
quels pics semblent “anormaux” ?
Faites un ADF et un KPSS sur :
daily
Puis proposez une atténuation de la tendance et de la saisonnalité
Corrigé :
import plotly.express as px
import pandas as pd
from statsmodels.tsa.seasonal import seasonal_decompose
# Chargement des données
daily = pd.read_csv("epidemioscope_clean_daily.csv", parse_dates=["date"])
daily = daily.set_index("date")
daily = daily["ili_consultations"]
# Décomposition
decomp = seasonal_decompose(daily, period=365)
# Construire un DataFrame propre
df_decomp = pd.DataFrame({
"Observed": decomp.observed,
"Trend": decomp.trend,
"Seasonal": decomp.seasonal,
"Residual": decomp.resid
})
# Passer en format long pour px
df_long = df_decomp.reset_index().melt(id_vars="date",
var_name="Component",
value_name="Value")
# Plot
fig = px.line(
df_long,
x="date",
y="Value",
facet_row="Component",
height=800
)
fig.update_layout(showlegend=False)
fig.show()
Analyse attendue :
tendance : lente, relativement stable (selon simulation)
saisonnalité : motif annuel fort
résidus : quelques pics isolés
En résumé
Visualiser la série permet d’identifier tendance, saisonnalité et anomalies avant toute modélisation
La moyenne mobile aide à lire la tendance, mais devient limitée si la saisonnalité est forte.
La décomposition (Trend / Seasonal / Resid) clarifie la structure réelle et isole les anomalies.
La stationnarité se vérifie avec ADF et KPSS, et se corrige si nécessaire par différenciation adaptée à la fréquence des données.
Vous maîtrisez la décomposition STL et les tests de stationnarité, voyez cela comme l’explication du passé. Il est désormais temps de prédire le futur !
