Produisez rapidement des prévisions business avec Prophet

Comprenez la logique “clé en main” de Prophet
Prophet est une librairie développée par META qui repose sur une idée simple :
Et cette fois-ci, plus besoin de choisirp,d,qou encore de tester la stationnarité, Prophetil modélise automatiquement une tendance flexible, plusieurs saisonnalités et des évènements spécifiques. C’est un modèle robuste aux données bruitées et conçu pour aller vite.
Testons rapidement la librairie sur nos données :
from prophet import Prophet
import pandas as pd
from itables import show
weekly = pd.read_csv("epidemioscope_clean_weekly.csv", parse_dates=["date"])weekly = weekly.set_index("date")["ili_consultations"].sort_index()
df = weekly.reset_index()
df.columns = ["ds", "y"]
model = Prophet()model.fit(df)
future = model.make_future_dataframe(periods=94, freq="W")
forecast = model.predict(future)
show(forecast)
Vous vous retrouvez avec un grand tableau que nous allons décortiquer ensemble :
La colonne “trend” correspond à la tendance long terme, comme vu au chapitre Explorez et comprenez la structure de la série avec Statsmodels3.
La colonne “yearly”, qui représente la composante saisonnière annuelle, modélise la saisonnalité.
Les colonnes additives et multiplicatives permettent d’activer d’autres options, que nous ne verrons pas dans ce cours.
Enfin le
yhatcorrespond à la prédiction du modèle.
Pourquoi yhat ?
Tout simplement, parce qu’en mathématiques une valeur estimée possède un accent circonflexe : et en anglais, le circonflexe n’existe pas, il est donc traduit comme chapeau soit “hat”.
Maintenant que vous avez compris comment Prophet structure ses prévisions, voyons comment visualiser ces résultats de manière claire et exploitable.
Réalisez des graphiques compréhensibles
Prophet possède aussi des graphiques de base avec matplotlib:
fig = model.plot(forecast)
fig_components = model.plot_components(forecast)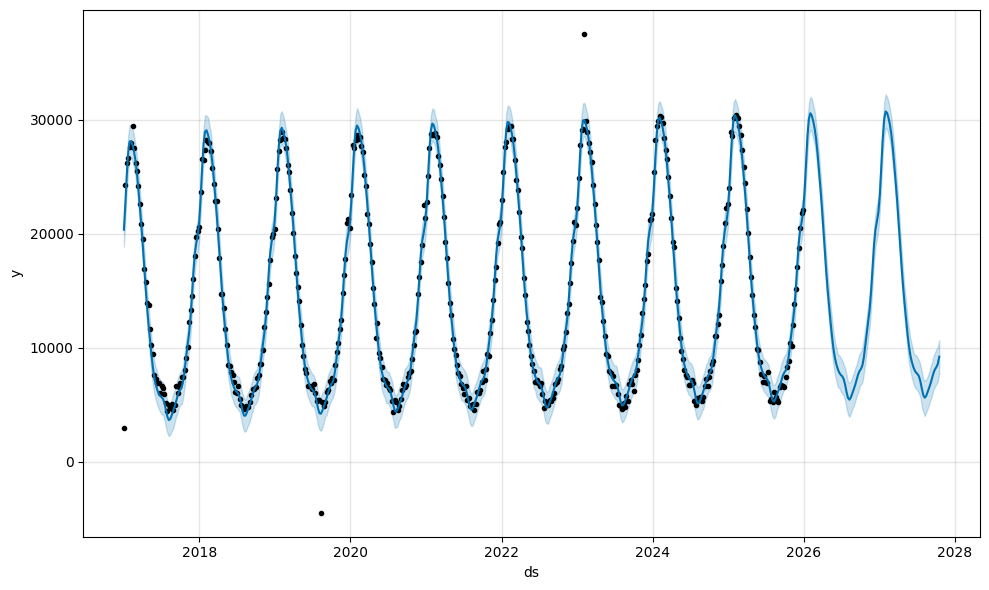
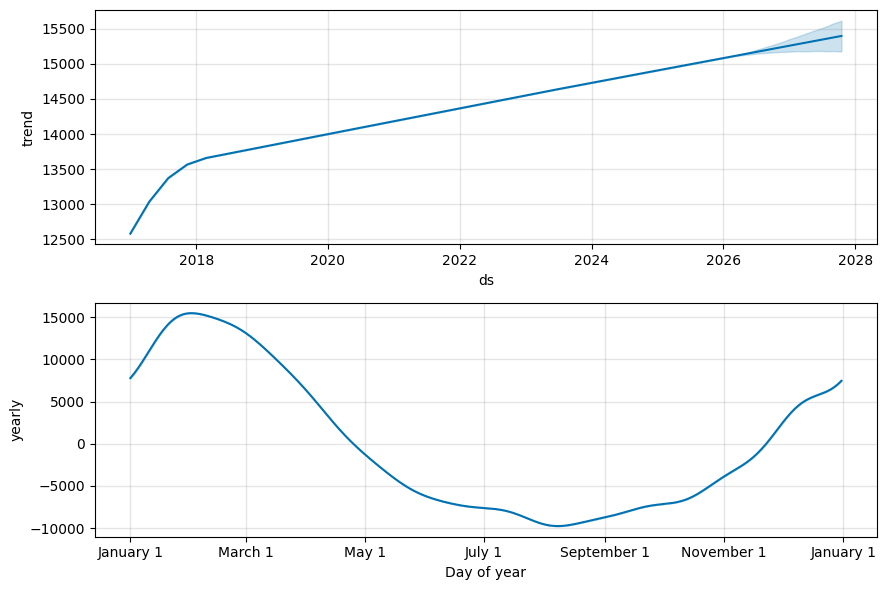
En un coup d’oeil, vous avez la possibilité de voir les prédictions avec les intervalles de confiance, la tendance et la saisonnalité ! Parfait pour partager rapidement des résultats.
Prophet a aussi pensé à vous qui aimez l’intéraction :
from prophet.plot import plot_plotly, plot_components_plotly
fig = plot_plotly(model, forecast)
fig_components = plot_components_plotly(model,forecast)
fig.show()
fig_components.show()
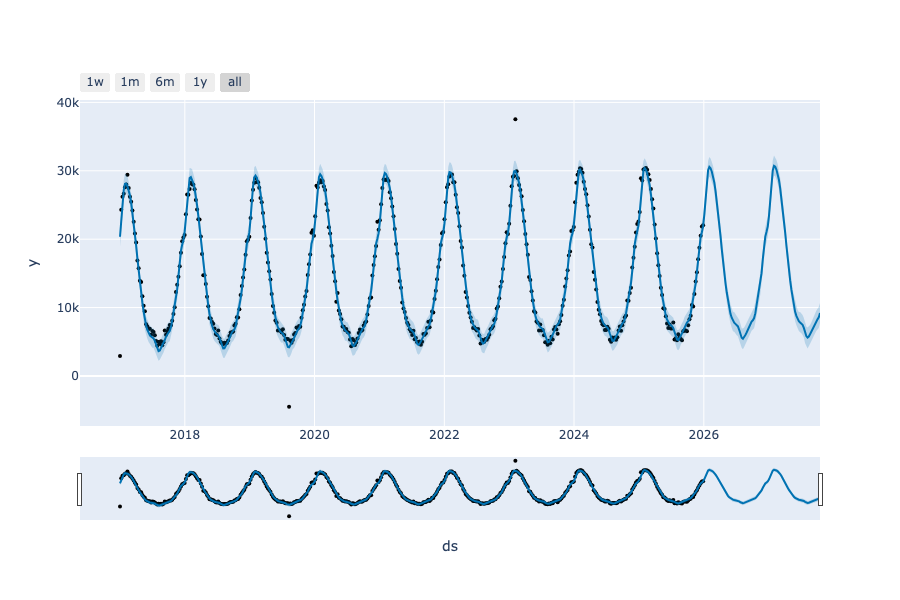
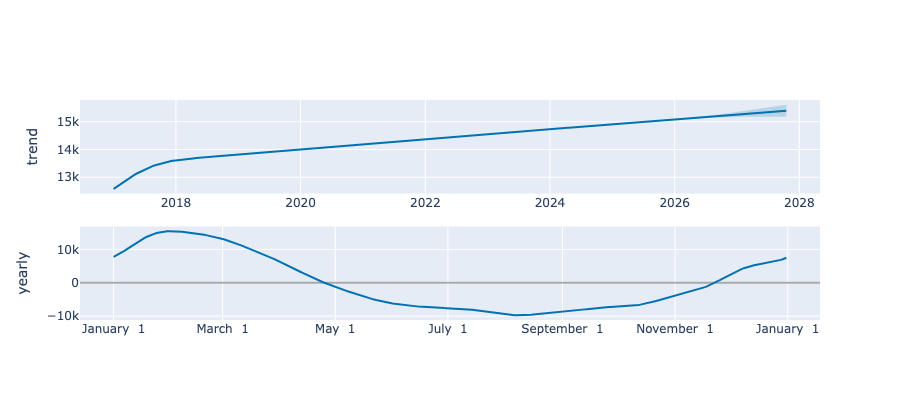
Vous pouvez désormais intéragir à votre guise avec vos graphiques.
Intégrez des événements et jours spéciaux
Prophet donne la possibilité d’intégrer des périodes “spéciales” comme les vacances. Il est probable que pendant ces périodes les données varient. E, en indiquant les périodes de vacances à Prophet, la librairie estime automatiquement l’impact sur les données.
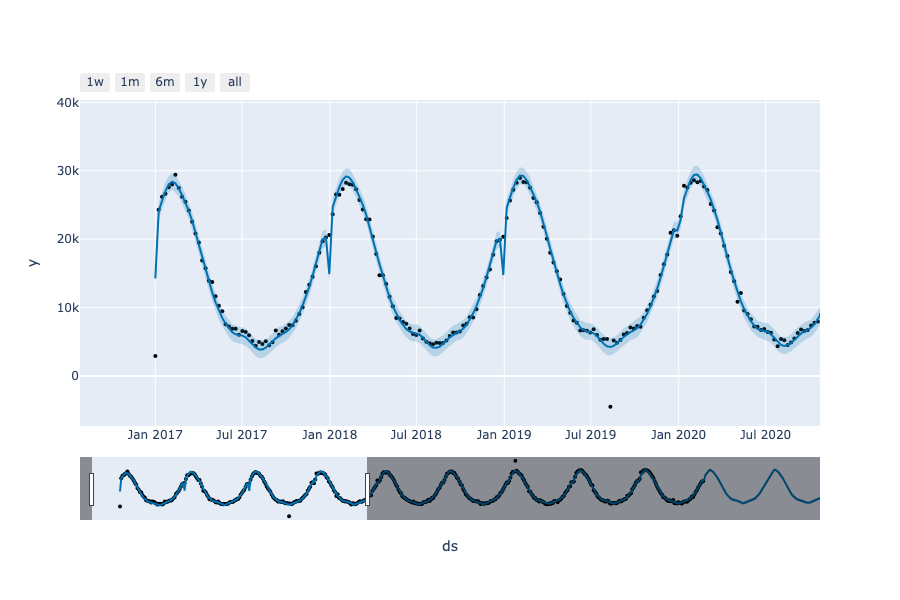
Maintenant, passons à l'étape qui transforme votre travail d'analyse en outil opérationnel : le déploiement.
Nous avons laissé explicitement 2 données aberrantes (outliers en anglais) dans notre jeu de données : avec une valeur de -4497 pour la semaine du 11/08/2019 et une valeur de 37533 pour la semaine du 05/02/2023. Voyons maintenant comment gérer ces données avec Prophet.
La première donnée est une donnée négative donc nous pouvons la supprimer, ou la passer en positif. Si nous ne voulons pas nous mouiller nous allons simplement la passer en NaN pour que Prophet ignore cette donnée.
Concernant la semaine du 05 février 2023, c’était une semaine où exceptionnellement il y a eu un pic de consultations. Nous allons le classifier comme événement et le rentrer dans les données types “Holidays”.
events = pd.DataFrame({
"holiday": "consultations_exceptionnelles",
"ds": ["2023-02-05"],
"lower_window": 0,
"upper_window": 0,
})
df.loc[df["y"]<0, "y"] = None
model = Prophet(holidays=events)
model.fit(df)
future = model.make_future_dataframe(periods=94, freq="W")
forecast = model.predict(future)
fig = plot_plotly(model, forecast)
fig_components = plot_components_plotly(model,forecast)
fig.show()
fig_components.show()
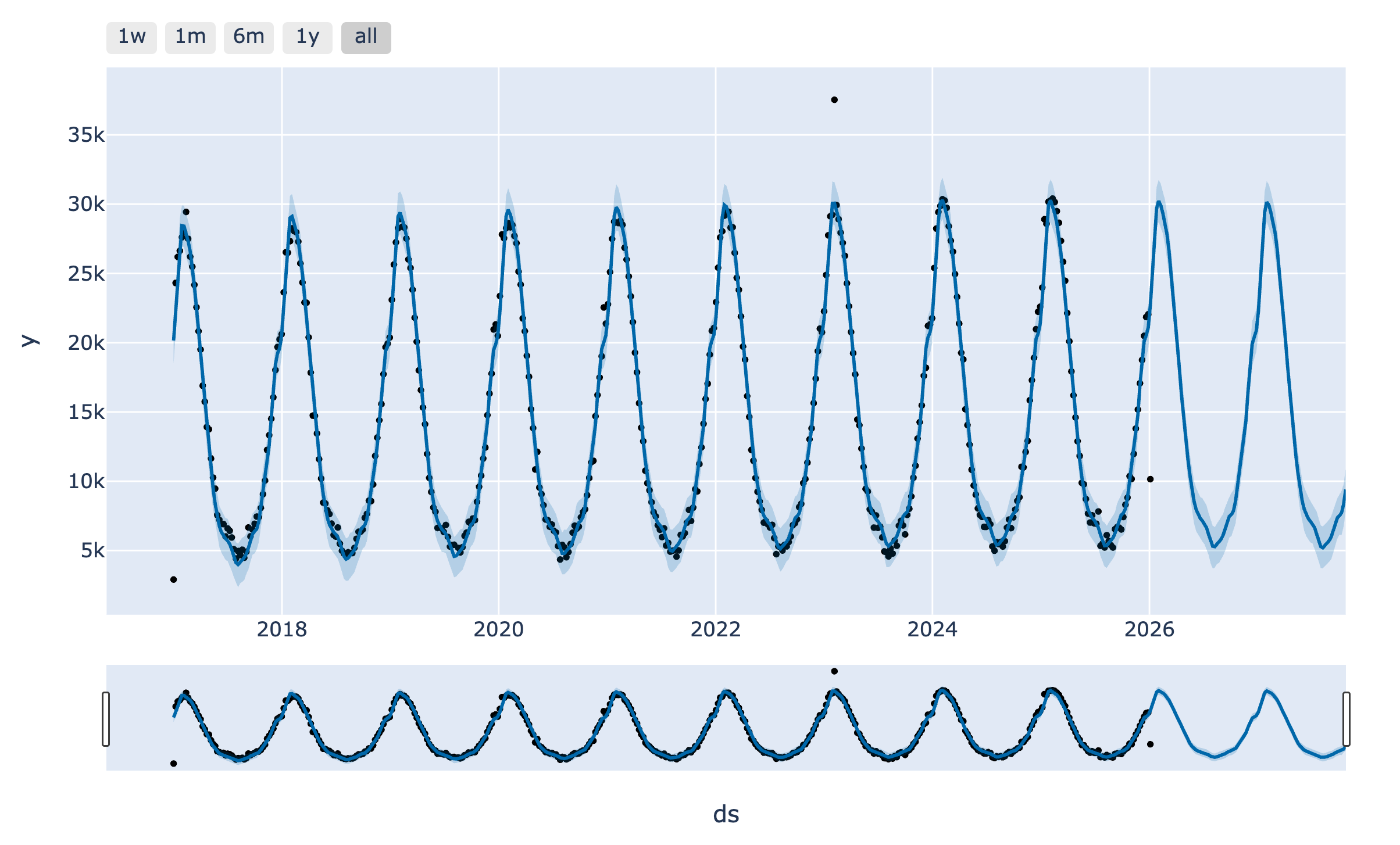
Gérez les changements de tendance
Détectez des ruptures
Notre jeu de donnée est très propre sans rupture marquée.
Regardons maintenant un nouveau jeu de données concernant un nombre de consultations hebdomadaires dans un réseau de cabinets et utilisons Prophet pour l’analyser :
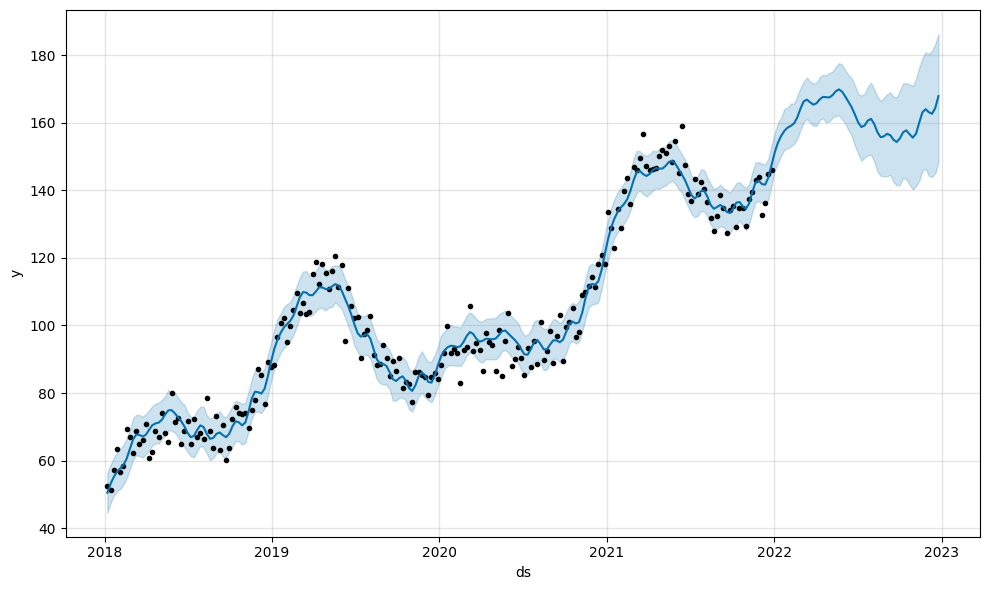
Entre Janvier 2018 et mai 2019, une croissance progressive s’observe, suivi par une baisse entre mai 2019 et septembre 2020. À partir de septembre 2020, un rebond est observé ; et ilet qui vient se stabiliser à partir de mai 2021.
Regardons maintenant comment Prophet détecte des ruptures :
from prophet.plot import add_changepoints_to_plot
fig = m.plot(forecast)a = add_changepoints_to_plot(fig.gca(), m, forecast)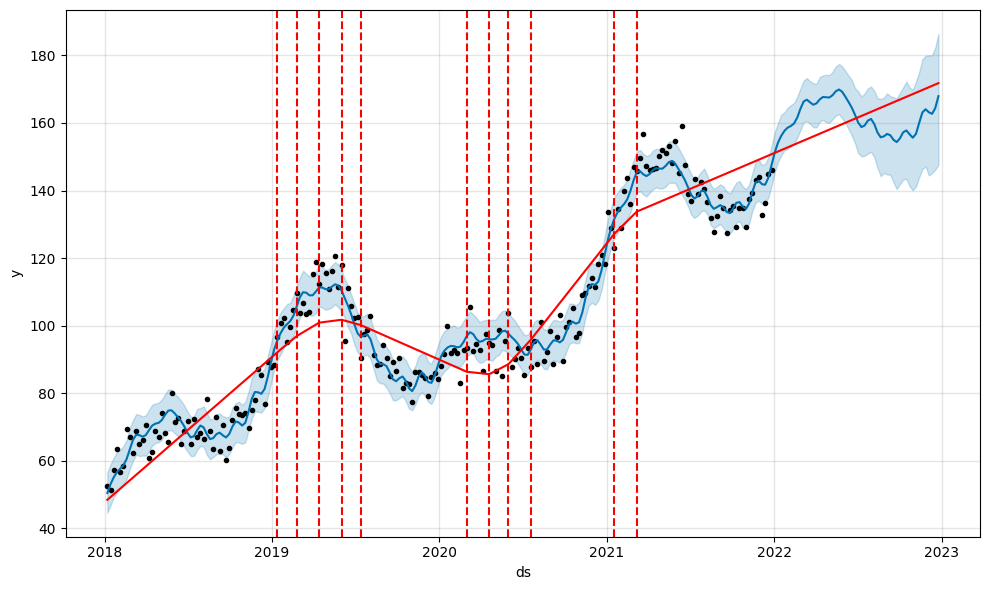
La ligne rouge représente la tendance globale estimée, et les lignes verticales en pointillées représentes les ruptures (ou change points) détectés automatiquement par Prophet. Ces points de rupture changepoints et leur impact peuvent être ajustés pour améliorer le modèle.
Ajustez la flexibilité de la tendance pour éviter une sur/sous-réaction
Exemple avec unchangepoint_prior_scale=0.01:
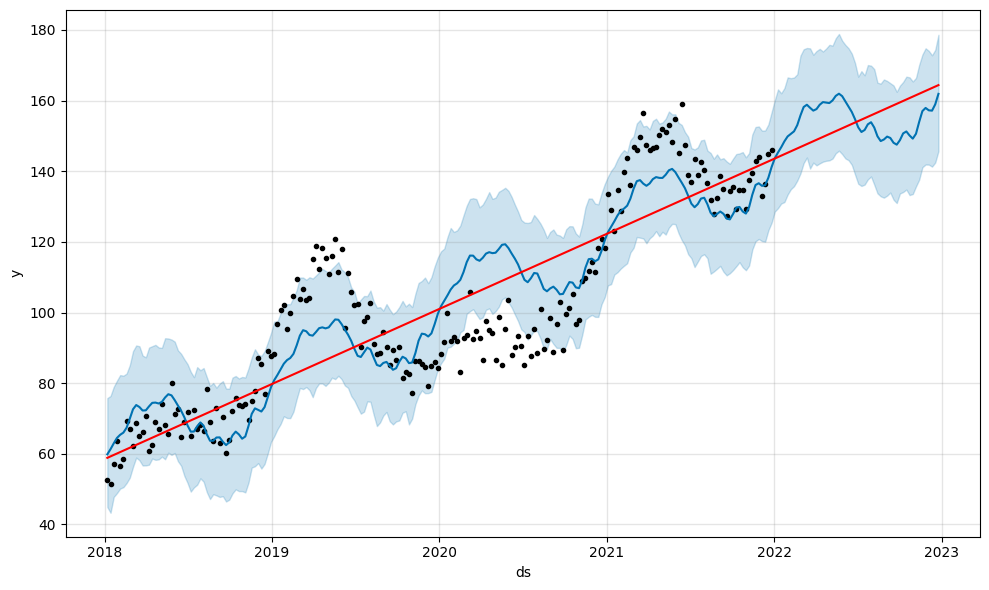
Le modèle ne voit qu’une saisonnalité croissante et n’arrive pas à capturer les différentes variations.
Exemple avec unchangepoint_prior_scale=10:
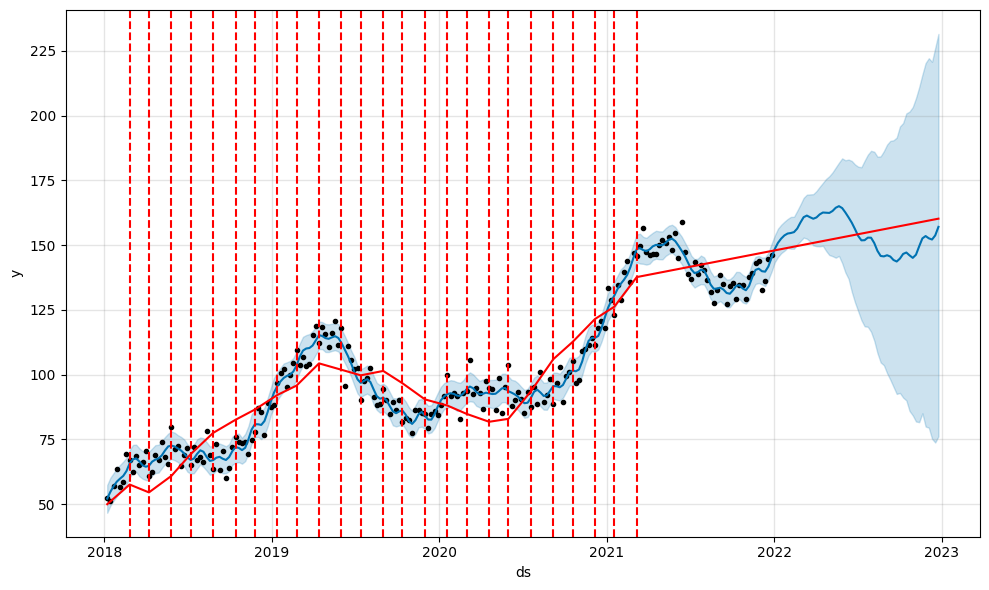
Cette fois-ci, le modèle capture trop de petites variations et l’intervalle de confiance de prédictions devient exponentiellement grand, ce qui signifie que le modèle n’est pas utilisable pour de la prédiction.
En plus de la flexibilité des ruptures, vous pouvez ajouter des ruptures, à la manière des vacances, pour modéliser plus finement votre modèle :
m = Prophet(
changepoints=[
"2019-05-01",
"2019-12-01",
"2020-09-01",
"2021-05-01",
"2021-09-01"]
)
m.fit(df)
future = m.make_future_dataframe(periods=52, freq='W')
forecast = m.predict(future)
fig = m.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), m, forecast)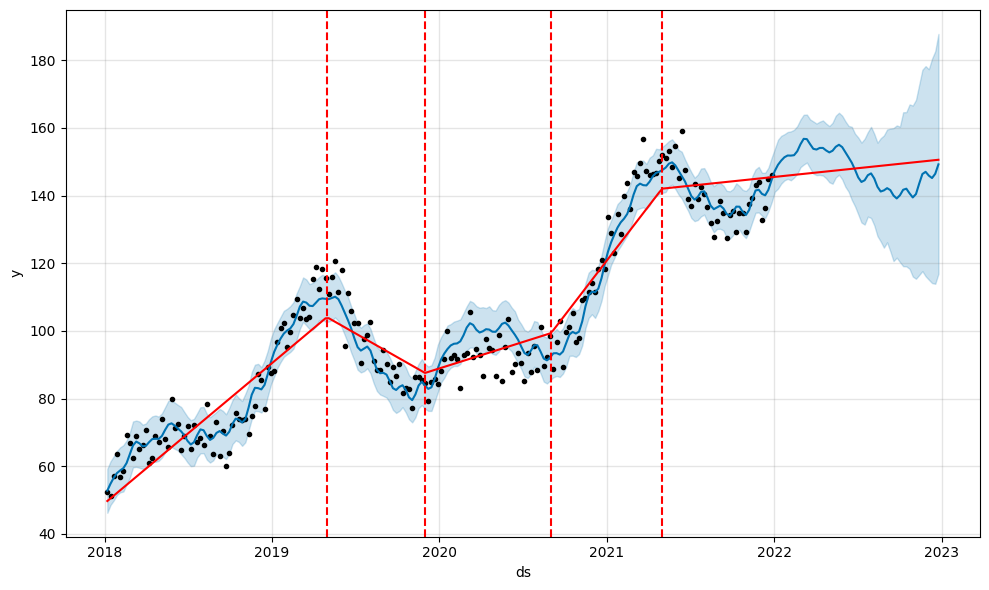
En résumé
Prophet modélise une série temporelle comme la somme d’une tendance, de saisonnalités et d’un bruit, ce qui permet de produire rapidement une première prévision.
Le modèle fournit une prévision centrale accompagnée d’intervalles d’incertitude, indispensables pour une lecture “business” du résultat.
Les composantes (tendance et saisonnalités) se visualisent facilement afin d’expliquer d’où viennent les variations observées et prévues.
Il est possible d’intégrer des événements et jours spéciaux pour capturer des pics ou des périodes atypiques, à condition de ne les ajouter que s’ils ont un impact réel sur la série.
La flexibilité de la tendance se règle via les paramètres de changepoints (dont
changepoint_prior_scale) pour éviter le sous-apprentissage comme le sur-apprentissage.
Vous savez désormais nettoyer vos données, produire un modèle de prédiction sur série temporelle et analyser ses résultats. Il est temps de répondre au quiz pour valider vos acquis. Ensuite je vous propose un dernier chapitre pour voir comme transformer votre modèle (qui vit pour l’instant sur votre notebook) en outil exploitable. C’est parti !
