Understand window functions using OVER and PARTITION BY
Window functions are often used to (among other things):
calculate cumulative sums
order rows within a partition.
As you will see, there are many similarities between aggregations and window functions.
Let’s wave our little magic want over this... :magicien:
SELECT incorporation_date, min(id) OVER() FROM entity ;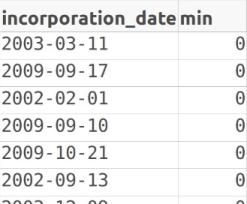
Tada! No more error! When we insert OVER() , the aggregate function min() returns as many rows as there are in entity. This is not normal behavior for an aggregate function!
Window Functions
Yes, it’s true... there are many similarities between aggregations and window functions. Both are executed in two phases, and they differ only in respect to phase two:
| Agrégation | Window Function |
Phase 1 | Partitioning by partitioning attributes | Partitioning by partitioning attributes |
Phase 2 | Application of an aggregate function | Application...
|
Result | As many rows as aggregates | As many rows as the original table |
Window functions are defined using an OVER clause. The OVER clause has two capabilities, each with its own behavior! Here are the corresponding syntaxes:
OVER (PARTITION BY ...)OVER (PARTITION BY ... ORDER BY ...)
OVER (PARTITION BY...)
Let’s analyze these two queries, which use the nb_entities table from the previous chapter:
-- REQUETE n°1SELECT sum(cnt_entities) FROM nb_entities GROUP BY id_intermediary ;-- REQUETE n°2SELECT sum(cnt_entities) OVER (PARTITION BY id_intermediary) FROM nb_entities ;Query no. 2 functions almost like the aggregation in query 1; the only thing that’s different is what sum returns.
In query no. 2, if sum receives as input the list of values [10, 1, 5] , it won’t return 16 ; it will return [16, 16, 16].
In both cases, we are calculating the total number of companies created by each intermediary. But here is how the result is presented using a window function:
SELECT id_intermediary, jurisdiction, cnt_entities, sum(cnt_entities) OVER (PARTITION BY id_intermediary) AS entities_by_intermediary FROM nb_entities ;id_intermediary | jurisdiction | cnt_entities | entities_by_intermediary |
4000 | SAM | 10 | 16 |
4000 | PMA | 1 | 16 |
4000 | CYP | 5 | 16 |
4001 | SAM | 3 | 5 |
4001 | NEV | 2 | 5 |
[...] | [...] | [...] | [...] |
OVER (PARTITION BY... ORDER BY...)
With an aggregate function
When we add ORDER BY to the OVER clause, the aggregate function behaves in still another way!
Indeed, it considers these values to be ranked. As before, the aggregate function is going to return as many rows as it received as input. But it’s going to do this:
Perform a calculation on the 1st value, and return the result;
Perform a calculation on the 1st and 2nd values, and return the result;
Perform a calculation on the 1st, 2nd, and 3rd values, and return the result;
And so on.
Thus, if the sum function receives [10, 5, 1], it will return [10, 15, 16], because
10 = 10
10 + 5 = 15
10 + 5 + 1 = 16
Here, sum behaves like a cumulative sum!
With a ranking function
If we use a ranking function (for example, rank ), it will simply return the order of the rows. These rows have been previously sorted, thanks to ORDER BY .
A little example: we are in a race, and have recorded the time it took each runner to finish the course. To find out who will be on the podium, we need to rank the athletes according to their time:
SELECT firstname, time, rank() OVER (ORDER BY temps) FROM course ;firstname | time | rank() |
Naomi | 3 min 15 s | 1 |
Sarah | 3 min 19 s | 3 |
Sonia | 3 min 16 s | 2 |
Luke | 10 min 39 s | 4 |
Cumulative Sums and Ranking Numbers
So let’s assign a rank to each jurisdiction for each intermediary. Let’s call our ranking rank . To assign a rank to a jurisdiction, I sort cnt_entities in descending order. Since I want to obtain a ranking for each intermediary, I write PARTITION BY id_intermediary .
We can also calculate a cumulative sum! Let’s calculate the cumulative sum of cnt_entities for each intermediary, sorting the rows in descending order of cnt_entities . Let’s call our cumulative sum cum_sum .
SELECT id_intermediary, jurisdiction, cnt_entities, rank() OVER(PARTITION BY id_intermediary ORDER BY cnt_entities DESC) AS rank, sum(cnt_entities) OVER(PARTITION BY id_intermediary ORDER BY cnt_entities DESC) AS cum_sumFROM nb_entities ;Here's the result:
id_intermediary | jurisdiction | cnt_entitites | rank | cum_sum |
4000 | SAM | 10 | 1 | 10 |
4000 | CYP | 5 | 2 | 15 |
4000 | PMA | 1 | 3 | 16 |
4001 | SAM | 3 | 1 | 3 |
4001 | NEV | 2 | 2 | 5 |
[...] | [...] | [...] | [...] | [...] |
Summary
Window functions are very similar to aggregations, except they don’t change the number of rows.
The
OVERkeyword can be used to form groups of rows (aggregate functions) or to order rows within a partition (ranking functions).The keyword
OVERcan be used to calculatecumulative sumsordetermine rankings.
