Identify the Applications of Reactive Streams in Java
Until this point, you've seen how to use a range of approaches to write asynchronous software, which is highly efficient in solving complex tasks. A pattern you've seen repeatedly is the producer-consumer pattern, where each step of the program produces an output for the next step.
Traditionally, concurrent applications are generally designed to work in steps, and it's often up to you to connect those:
Consume data from some source, such as a file, database, or another program.
Repeatedly execute steps to map each piece of data into intermediary results.
Finally, reduce the results of those repeated mappings into some outcome or result.
You've seen how to avoid implementing connecting code, which passes data between producers and consumers threads. Instead, you can keep all your threads by using the ForkJoinPool with ComputableFutures to minimize potential blocking between each processing step.
While these tools are excellent for processing data requiring a result, what happens if there is no Step 3? That is, what if you need to keep running analytics on a continuous stream of data? It's quite normal these days as many engineering teams build or use data sources with continuous streams of live data.
We use the word live to describe data that represent recent changes happening continuously. For instance, measuring the temperature continuously gives you a series of values, which is vast. You can't process these all together and calculate an average at the end since there might not be an end! With data that you have a lot of, you want to consider each item in that data stream and respond to it in some way.
The solution is reactive programming. Reactive programming gets units of your code to react to events (units of change) that occur in a system.
Identify the applications of Reactive Programming
In 2013, a prominent group of engineers created The Reactive Manifesto. This detailed a set of principles for building systems designed to, as the name suggests, react to the data presented to it.
What's special about reactive systems?
The authors of the manifesto described reactive systems as asynchronous software with single responsibility publishers (producers) sending messages with data to consumers. These reactive systems are designed to allow you to build software which naturally copes with the needs of high volumes of data.
Reactive systems have the following properties (according to The Reactive Manifesto):
Responsiveness: This is the ability to meet or exceed the performance targets of your application. For instance, you might want to produce a meaningful average planetary temperature every 200 milliseconds.
Resilience: Errors always occur because that's the nature of software. Systems that can keep processing and absorb the impact of some processing errors are known as resilient. For instance, a NumberFormatException, when reading a row from a file, shouldn't impact your ability to read the next row.
Elastic: A system is said to be elastic if it can adjust its resources, such as the numbers of publishers, subscribers, or some other factor, to better handle changes in the demands placed upon it. For example, if you're publishing too much data in one part of your system, you might want to increase the number of subscribers in another part.
Message-driven: The reactive system communicates between publishers and subscribers using asynchronous messages. A publisher can publish a message that something has happened, and a subscriber will independently, at its own most convenient time, do something with that message.
Modern concurrent programming is based on the principles of non-blocking reactive systems. Most frameworks for asynchronous data processing remove the responsibility for you to manage the mechanics of your asynchronous code. Instead, you can focus on implementing the behavior your business needs you to deliver. The Reactive Streams specification is a step towards doing this.
Explaining the Reactive Stream Specification
To help standardize and simplify the development of reactive applications, the developers of Java and other existing frameworks to support Reactive Programming created the Reactive Streams specification. The specification says that:
The purpose of Reactive Streams is to provide a standard for asynchronous stream processing with non-blocking backpressure.
What this means is that reactive streams offer stream-like processing, but differ in that backpressure is used to slow down publishers if needed. It's similar to BlockingQueues where you could slow down a publisher.
How does this differ from the Stream API we used?
In the Java Stream API, new data is only put onto the stream if you have subscribers ready to pull in some more data. We call it a pull-based system for this reason. Reactive streams work the other way around in that publishers keep pushing data to their subscribers whether or not they are ready for it. As with BlockingQueues, this gets queued up and is regulated with backpressure. A subscriber can explicitly ask for more data when needed.
This specification is the basis for a set of interfaces that standardize the names of classes making up a reactive system. They include the following concepts (most Java frameworks represent these as classes):
Publisher
Responsible for preparing and sending data to subscribers as individual messages. These are objects of a given type.
Accepts a subscriber through its subscribe(Subscribers) method, telling it to send data to subscribers.
Subscriber:
Responsible for receiving messages from a publisher and processing this data. A subscriber is like a terminal operation in the Stream API.
A subscriber must implement the following methods:
onSubscribe(Subscription subscription)- This method gets called automatically when a publisher registers that a subscriber has registered and allows the subscription to request data.onNext(T message)- This method gets called on your subscriber every time the subscriber is ready to receive a new message of generic type T. Your subscriber can implement whatever behavior is required to respond to that message.
Subscription
A subscription describes how much data should be published from a publisher to a subscriber.
A subscription must have the following methods:
request(intnumberOfMessage)- You must pass this the number the maximum number of messages you want the publisher to queue up for your subscriber.cancel()- This cancels a subscription and prevents the publisher from sending any more data to the subscriber.
Processor
Responsible for both subscribing to a message and publishing a new one for its own subscribers.
Implementing this interface means that you are both a subscriber and a publisher.
It's great for intermediary steps of a stream that modify data and respond to it.
How does this differ from the producer-consumer patterns we saw previously?
Reactive publishers and subscribers are a specific implementation of the producer and consumer pattern used in reactive systems. Publishing involves producing messages to be consumed. Subscribers consume data produced by specific publishers they have subscribed to.
A difference between other producer and consumer implementations and the Reactive Streams API is that you plugin into a pattern and implementation that is already created by using a common API. Rather than having to implement each component and set up the data structures and polling loops for them to communicate, you publish a flow of messages or subscribe to it.
All of this means that Reactive Streams can be optimized to reduce blocking behavior. Even flow implementations use CompletableFutures and the thread-stealing ForkJoinPool to reduce blocking and provide the best performance.
Consider an example where you have a data source with temperatures in Kelvin. It can be converted to Celsius using the following Reactive Stream.
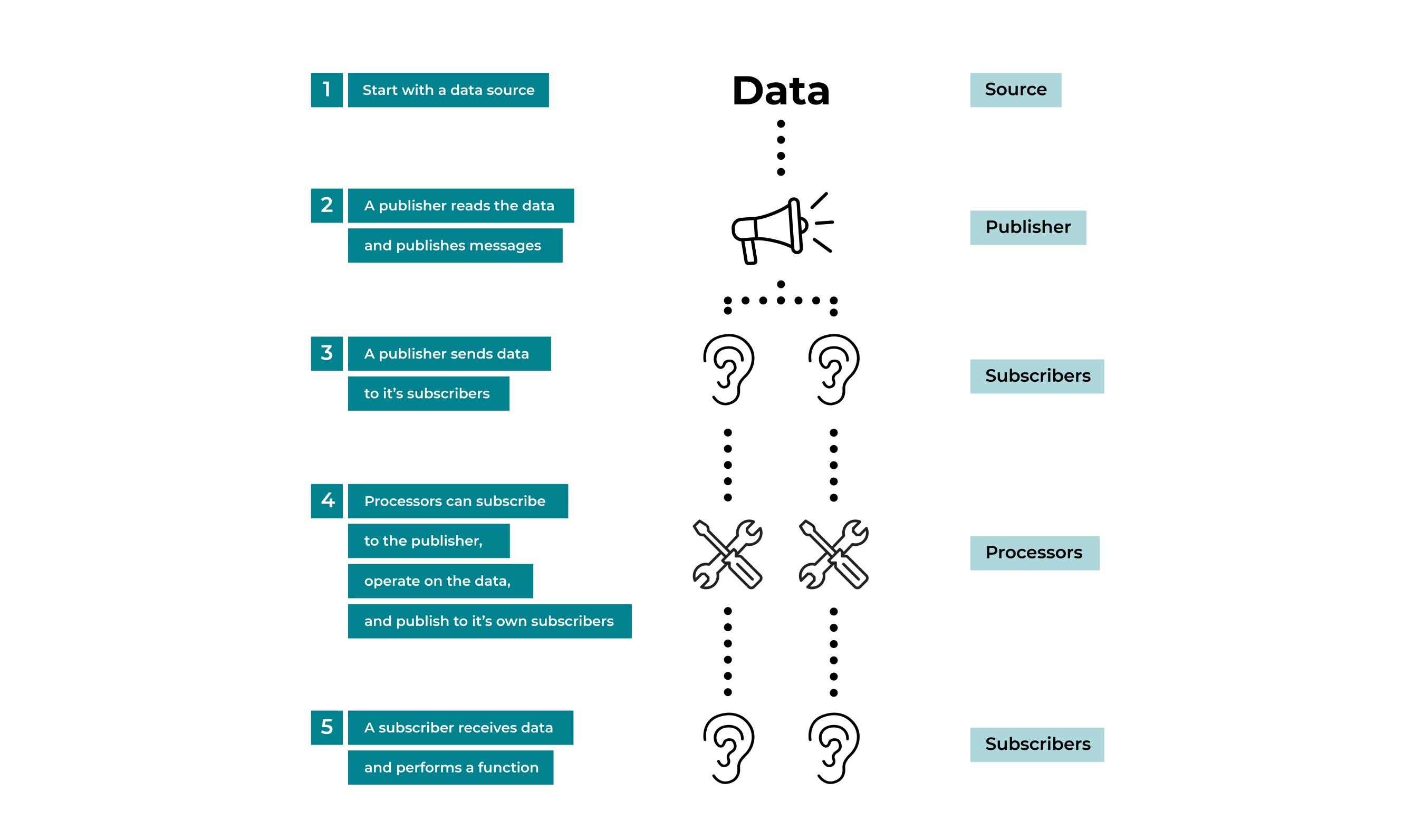
Reactive Streams use a publisher, processor, and subscriber to convert temperature to Celsius. Unlike the BlockingQueue examples, the publishers and subscribers of our application don't have to manage queues and other synchronization primitives between each component. They just use a single API to send messages, subscribe to them, and respond.
Let's break this down:
Step 1: Start with some sequential data in your data source. This might be a file or a feed from NASA.
Step 2: The publisher in the stream reads this data.
Step 3: The publisher sends a message with each temperature value to its subscribers. In this case, instances of the ConvertToCelsius processor.
Step 4: The ConvertToCelsius processors are individually subscribed to by StoreAsCelsius subscribers. As the processor's
onNext()method receives new temperature values in Kelvin, it might convert these to Celsius and emit them for its subscribers.Step 5: The StoreAsCelsius subscriber has its
onNext()method called for each message. It might store those values in a file, or do something else with them.
Although you can't see it here, the publisher holds onto several subscription objects referring to all of its subscribers. That is, TemperaturePublisher::subscribe has been called with instances of the ConvertToCelsius processors.
So how does this measure up against the properties of a reactive system?
You should also be able to have processors and subscribers that see a read temperature and do something with that data. For instance, auditing it or converting it to some other value, as done above. Let's see how much of a reactive system this pattern gives you:
Responsiveness - If the publishers, processors, and subscribers were relatively small and focused on their separate responsibilities, this application would start working on a new temperature as soon as it appears to a publisher.
Resilience - If an error occurs in one of your subscribers or processors, you can handle it there. That failure does not need to be advertised to all the other publishers and subscribers. The less they know about one another, the better.
How would you handle an error?
A popular and reactive approach is to publish that error to the subscriber that deals with errors!
Elastic - What happens if you need to process more temperatures faster? Well, you can easily use more subscribers for slower operations. If published data needs to be handled faster, then you have the option of increasing the number of subscribers. You still have the rope to hang yourself by using too many. Always benchmark and test such changes.
Message-driven - Inherent in the workflow you saw above, messages flow between publishers, subscribers, and producers. It's how they send their results to the next set of subscribers.
You should have subscribers at the ready to do their job. Reactive Streams allow you to focus on writing code, which reacts to changes. They save writing custom code to handle thread creation, plugging in queues, and making sure that data flows from the right producers to consumers. It removes much of the boilerplate code you write to make asynchronous code asynchronous.
Let's Recap!
Reactive systems attempt to robustly cope with huge amounts of data that is constantly changing.
Reactive systems provide high levels of responsiveness in their use, resilience in the face of errors, and elasticity to cope with increases in usage. They achieve this by being message-driven.
The Reactive Streams API provides Java interfaces for publishers (producers of messages) and subscribers.
Reactive systems produce streams of messages that flow continuously to consumers who handle those messages.
Publishers are subscribed to by a subscriber using a subscription. A subscription allows a subscriber to request new messages to queue up for it whenever it's ready.
In the next chapter, we'll put this theory into practice and work with Reactive Streams!
