Carry Out a Hierarchical Clustering
In the previous chapter we learned how the hierarchical clustering algorithm finds groups of data points in a sample using a different approach to k-means.
Let's see how we can use the scikit-learn implementation of hierarchical clustering by writing some Python code.
We will again use the same Times Educational Supplement university rankings data that we used in the PCA and k-means exercises.
Loading, cleaning and standardizing the data
We perform an initial load, clean and standardise of the data in exactly the same way as for PCA and k-means:
# Import standard libraries
import pandas as pd
import numpy as np
# Import the hierarchical clustering algorithm
from sklearn.cluster import AgglomerativeClustering
# Import functions created for this course
from functions import *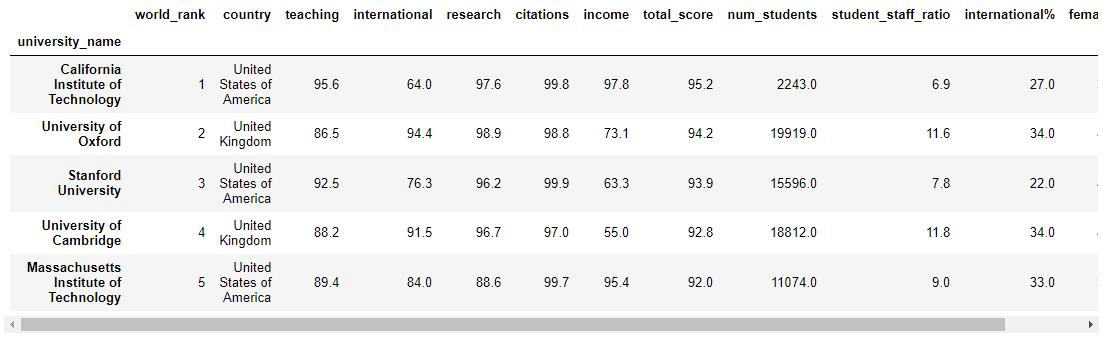
As we did with k-means and PCA we will remove country, total_score and world_rank columns so we are left with useful quantitative data:
X = original_data[['teaching', 'international',
'research', 'citations', 'income', 'num_students',
'student_staff_ratio', 'international%', 'female%',
'male%']]
X.head()
Again, we will replace nulls with the mean value of the variable:
X = X.fillna(X.mean()) Again, we will apply the standard scaler to scale our data so that all variables have a mean of 0 and a standard deviation of 1.
# Import the sklearn function
from sklearn.preprocessing import StandardScaler
# Standardize the data
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_scaled
So, thus far we have treated the data in exactly the same way we did for PCA and k-means clustering.
Performing a hierarchical clustering
Now we can perform the hierarchical clustering. First, let's ask the algorithm to produce the full hierarchical cluster tree.
# Create a hierarchical clustering model
hiercluster = AgglomerativeClustering(affinity='euclidean', linkage='ward', compute_full_tree=True) Next, we will ask the algorithm to find 3 clusters from the tree:
# Fit the data to the model and determine which clusters each data point belongs to:
hiercluster.set_params(n_clusters=3)
clusters = hiercluster.fit_predict(X_scaled)
np.bincount(clusters) # count of data points in each clusterarray([555, 146, 99], dtype=int64)
One of the advantages of hierarchical clustering is that we can now change how many clusters we want just by "reading off" the required number from the tree:
# Read off 5 clusters:
hiercluster.set_params(n_clusters=5)
clusters = hiercluster.fit_predict(X_scaled)
np.bincount(clusters) # count of data points in each clusterarray([336, 50, 99, 146, 169], dtype=int64)
Let's stick with 5 clusters and put the cluster number on as a new column on the original data, so we can see what it did:
# Add cluster number to the original data
X_scaled_clustered = pd.DataFrame(X_scaled, columns=X.columns, index=X.index)
X_scaled_clustered['cluster'] = clusters
X_scaled_clustered.head()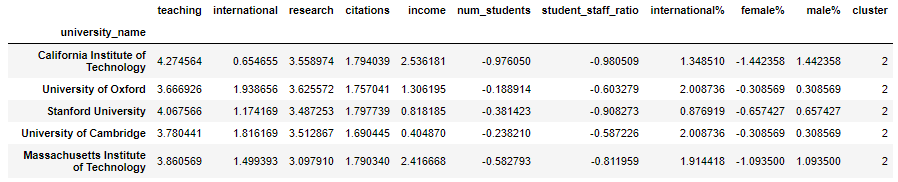
That's it! We have performed hierarchical clustering on our data. In the next chapter, we will analyse the results.
Recap
We can ask the algorithm to produce the full hierarchical cluster tree
Then, we can ask the algorithm to read-off a given number of clusters from the tree
